 Página delantera > Programación > Optimización del web scraping: scraping de datos de autenticación usando JSDOM
Página delantera > Programación > Optimización del web scraping: scraping de datos de autenticación usando JSDOM
Optimización del web scraping: scraping de datos de autenticación usando JSDOM
 Navegar:860
Navegar:860
Como desarrolladores de scraping, a veces necesitamos extraer datos de autenticación como claves temporales para realizar nuestras tareas. Sin embargo, no es tan simple como eso. Por lo general, se encuentra en solicitudes de red HTML o XHR, pero a veces se calculan los datos de autenticación. En ese caso, podemos aplicar ingeniería inversa al cálculo, lo que lleva mucho tiempo desofuscar los scripts, o ejecutar el JavaScript que lo calcula. Normalmente utilizamos un navegador, pero es caro. Crawlee brinda soporte para ejecutar Browser Scraper y Cheerio Scraper en paralelo, pero eso es muy complejo y costoso en términos de uso de recursos informáticos. JSDOM nos ayuda a ejecutar JavaScript de páginas con menos recursos que un navegador y un poco más que Cheerio.
Este artículo analizará un nuevo enfoque que utilizamos en uno de nuestros Actors para obtener los datos de autenticación del centro creativo de anuncios de TikTok generados por las aplicaciones web del navegador sin ejecutar realmente el navegador, sino utilizando JSDOM.
Analizando el sitio web
Cuando visitas esta URL:
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
Verás una lista de hashtags con su clasificación en vivo, la cantidad de publicaciones que tienen, un gráfico de tendencias, creadores y análisis. También puede observar que podemos filtrar la industria, establecer el período de tiempo y usar una casilla de verificación para filtrar si la tendencia es nueva entre las 100 principales o no.
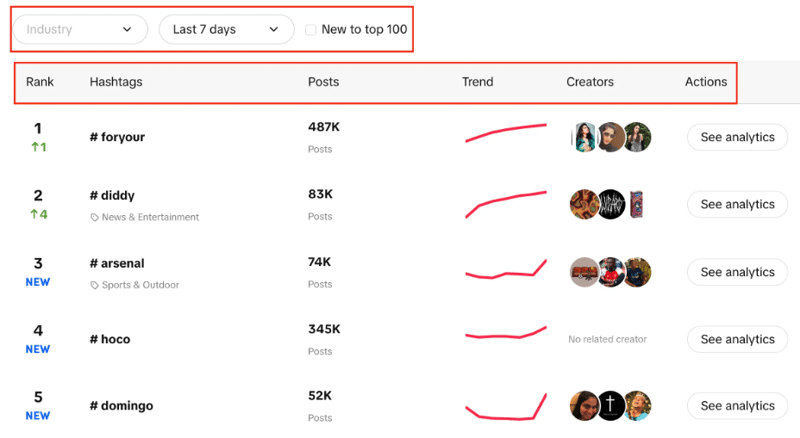
Nuestro objetivo aquí es extraer los 100 hashtags principales de la lista con los filtros proporcionados.
Los dos enfoques posibles son utilizar CheerioCrawler y el segundo será el raspado basado en navegador. Cheerio ofrece resultados más rápido pero no funciona con sitios web renderizados en JavaScript.
Cheerio no es la mejor opción aquí, ya que Creative Center es una aplicación web y la fuente de datos es API, por lo que solo podemos obtener los hashtags inicialmente presentes en la estructura HTML, pero no cada uno de los 100 que necesitamos.
El segundo enfoque puede ser usar bibliotecas como Puppeteer, Playwright, etc., para realizar scraping basado en navegador y usar la automatización para scrapear todos los hashtags, pero con experiencias previas, lleva mucho tiempo para una tarea tan pequeña.
Ahora viene el nuevo enfoque que desarrollamos para hacer que este proceso sea mucho mejor que el rastreo basado en navegador y muy cercano al rastreo basado en CheerioCrawler.
Enfoque JSDOM
Antes de profundizar en este enfoque, me gustaría darle crédito a Alexey Udovydchenko, ingeniero de automatización web en Apify, por desarrollar este enfoque. ¡Felicitaciones a él!
En este enfoque, realizaremos llamadas API a https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list para obtener los datos requeridos.
Antes de realizar llamadas a esta API, necesitaremos algunos encabezados requeridos (datos de autenticación), por lo que primero haremos la llamada a https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad /es.
Comenzaremos este enfoque creando una función que creará la URL para la llamada API por nosotros y realizará la llamada y obtendrá los datos.
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
En la función anterior, creamos la URL de inicio para la llamada API que incluye varios parámetros como hablamos anteriormente. Después de crear la URL de acuerdo con los parámetros, llamará a creative_radar_api y obtendrá todos los resultados.
Pero no funcionará hasta que tengamos los encabezados. Entonces, creemos una función que primero creará una sesión usando sessionPool y proxyConfiguration.
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
En esta función, el objetivo principal es llamar a https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en y obtener encabezados a cambio. Para obtener los encabezados estamos usando la función getApiUrlWithVerificationToken.
Antes de continuar, quiero mencionar que Crawlee admite de forma nativa JSDOM utilizando JSDOM Crawler. Proporciona un marco para el rastreo paralelo de páginas web utilizando solicitudes HTTP simples e implementación jsdom DOM. Utiliza solicitudes HTTP sin procesar para descargar páginas web, es muy rápido y eficiente en el ancho de banda de datos.
Veamos cómo vamos a crear la función getApiUrlWithVerificationToken:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
En esta función, estamos creando una consola virtual que utiliza CustomResourceLoader para ejecutar el proceso en segundo plano y reemplazar el navegador con JSDOM.
Para este ejemplo en particular, necesitamos tres encabezados obligatorios para realizar la llamada a la API, y son ID de usuario anónimo, marca de tiempo y signo de usuario.
Usando XMLHttpRequest.prototype.setRequestHeader, estamos verificando si los encabezados mencionados están en la respuesta o no, si es así, tomamos el valor de esos encabezados y repetimos los reintentos hasta obtener todos los encabezados.
Luego, la parte más importante es que usamos XMLHttpRequest.prototype.open para extraer los datos de autenticación y realizar llamadas sin usar navegadores ni exponer la actividad del bot.
Al final de createSessionFunction, devuelve una sesión con los encabezados requeridos.
Ahora, pasando a nuestro código principal, usaremos CheerioCrawler y usaremos prenavigationHooks para inyectar los encabezados que obtuvimos de la función anterior en requestHandler.
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
Finalmente, en el controlador de solicitudes hacemos la llamada usando los encabezados y nos aseguramos de cuántas llamadas son necesarias para recuperar todos los datos de la paginación de manejo.
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
Una cosa importante a tener en cuenta aquí es que estamos creando este código de manera que podamos realizar cualquier cantidad de llamadas API.
En este ejemplo en particular, solo realizamos una solicitud y una única sesión, pero puedes hacer más si lo necesitas. Cuando se complete la primera llamada API, se creará la segunda llamada API. Nuevamente, puedes hacer más llamadas si es necesario, pero nos detuvimos en dos.
Para aclarar las cosas, así es como se ve el flujo de código:
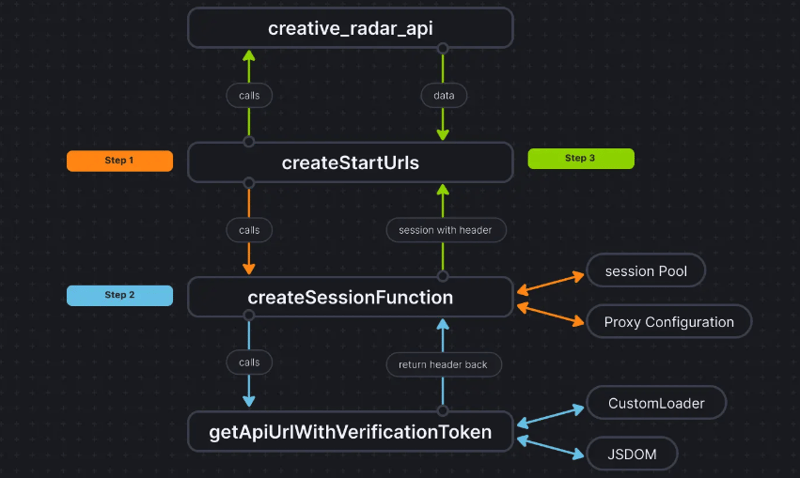
Conclusión
Este enfoque nos ayuda a obtener una tercera forma de extraer los datos de autenticación sin usar un navegador y pasar los datos a CheerioCrawler. Esto mejora significativamente el rendimiento y reduce el requisito de RAM en un 50%, y mientras que el rendimiento del scraping basado en navegador es diez veces más lento que el de Cheerio puro, JSDOM lo hace sólo 3 o 4 veces más lento, lo que lo hace 2 o 3 veces más rápido que el navegador. raspado basado.
El código base del proyecto ya está subido aquí. El código está escrito como Apify Actor; Puedes encontrar más información al respecto aquí, pero también puedes ejecutarlo sin usar Apify SDK.
Si tiene alguna duda o pregunta sobre este enfoque, comuníquese con nosotros en nuestro servidor de Discord.
-
 Eval () vs. AST.LITERAL_EVAL (): ¿Qué función de Python es más segura para la entrada del usuario?pesando eval () y Ast.literal_eval () en Python Security Al manejar la entrada del usuario, es imperativo priorizar la seguridad. eval (), una...Programación Publicado el 2025-04-09
Eval () vs. AST.LITERAL_EVAL (): ¿Qué función de Python es más segura para la entrada del usuario?pesando eval () y Ast.literal_eval () en Python Security Al manejar la entrada del usuario, es imperativo priorizar la seguridad. eval (), una...Programación Publicado el 2025-04-09 -
¿Cómo resolver las discrepancias de la ruta del módulo en el mod utilizando la Directiva Reemplazar?Superación del módulo Discrepancia en el mod Al utilizar el mod, es posible encontrar un conflicto en el que un paquete de terceros importe ot...Programación Publicado el 2025-04-09
-
¿Cómo puede definir variables en plantillas de cuchilla de laravel elegantemente?Definición de variables en plantillas de Blade Laravel con elegancia Comprender cómo asignar variables en plantillas de cuchillas es crucial p...Programación Publicado el 2025-04-09
-
¿Cómo crear una animación CSS suave de izquierda-derecha para un DIV dentro de su contenedor?animación CSS genérica para el movimiento de derecha izquierda En este artículo, exploraremos la creación de una animación genérica de CSS par...Programación Publicado el 2025-04-09
-
¿Por qué recibo un error de \ "clase \ 'Ziparchive \' no encontrado \" después de instalar Archive_Zip en mi servidor Linux?class 'Ziparchive' no encontrado Error al instalar Archive_Zip en Linux Server Sytom: cuando intentan ejecutar un script que utiliza...Programación Publicado el 2025-04-09
-
¿Necesito eliminar explícitamente las asignaciones de montón en C ++ antes de la salida del programa?deleción explícita en c a pesar de la salida del programa cuando trabajan con la asignación de memoria dinámica en c, los desarrolladores a me...Programación Publicado el 2025-04-09
-
¿Cómo convertir una columna Pandas DataFrame a formato de fecha y hora de filtrar por fecha?transformar la columna Pandas DataFrame en formato de Datetime escenario: datos dentro de un marco de datos PANDAS a menudo existe en varios...Programación Publicado el 2025-04-09
-
¿Cuáles fueron las restricciones al usar Current_Timestamp con columnas de marca de tiempo en MySQL antes de la versión 5.6.5?en las columnas de la marca de tiempo con cursion_timestamp en predeterminado o en las cláusulas de actualización en las versiones mySql antes de ...Programación Publicado el 2025-04-09
-
Fit de objeto: la cubierta falla en IE y Edge, ¿cómo solucionar?Object-Fit: la portada falla en IE y Edge, ¿cómo solucionar? utilizando objeto-fit: cover; en CSS para mantener la altura de imagen consistent...Programación Publicado el 2025-04-09
-
¿Cómo establecer dinámicamente las claves en los objetos JavaScript?cómo crear una clave dinámica para una variable de objeto JavaScript al intentar crear una clave dinámica para un objeto JavaScript, usando esta...Programación Publicado el 2025-04-09
-
¿Cómo recuperar eficientemente la última fila para cada identificador único en PostgreSQL?postgresql: extrayendo la última fila para cada identificador único en postgresql, puede encontrar situaciones en las que necesita extraer la ...Programación Publicado el 2025-04-09
-
¿Cómo puedo configurar PyTesseract para el reconocimiento de un solo dígito con salida de solo número?pytesSeract OCR con reconocimiento de un solo dígito y restricciones numéricas en el contexto de pytasseract, configurando el tesseract para r...Programación Publicado el 2025-04-09
-
¿Por qué cesan la ejecución de JavaScript cuando se usa el botón de retroceso de Firefox?Problema de historial de navegación: JavaScript deja de ejecutar después de usar el botón de retroceso de Firefox Los usuarios de Firefox pued...Programación Publicado el 2025-04-09
-
¿Cómo redirigir múltiples tipos de usuarios (estudiantes, maestros y administradores) a sus respectivas actividades en una aplicación Firebase?rojo: cómo redirigir múltiples tipos de usuarios a las actividades respectivas Comprender el problema en una aplicación de votación basada...Programación Publicado el 2025-04-09
-
¿Cómo eliminar los emojis de las cuerdas en Python: una guía para principiantes para solucionar errores comunes?Eliminación de emojis de las cadenas en python el código de python proporcionado para eliminar emojis falla porque contiene errores de sintaxi...Programación Publicado el 2025-04-09















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









