 Página delantera > Programación > Dominar MySQL: métricas clave de rendimiento que todo desarrollador debería monitorear
Página delantera > Programación > Dominar MySQL: métricas clave de rendimiento que todo desarrollador debería monitorear
Dominar MySQL: métricas clave de rendimiento que todo desarrollador debería monitorear
 Navegar:827
Navegar:827
Monitorear las métricas de rendimiento de MySQL y administrar su base de datos no tiene por qué ser difícil. Sí, escuchaste bien. Con las estrategias y herramientas de monitoreo adecuadas a su disposición, finalmente podrá pasar a un segundo plano. El método RED, combinado con las poderosas capacidades de monitoreo de Releem y las recomendaciones de configuración fáciles de aplicar, hace el trabajo pesado por usted.
Introducción al Método RED
El método RED se utiliza tradicionalmente para monitorear el rendimiento de aplicaciones y servicios web, pero también se puede aplicar al monitoreo del rendimiento de MySQL. Releem ha descubierto que el marco es igualmente valioso para monitorear las métricas de rendimiento de MySQL porque los desafíos que enfrentan las bases de datos, en términos de rendimiento y confiabilidad, reflejan los que enfrentan las aplicaciones web.
Cuando se aplica a bases de datos MySQL, el método RED se divide en tres áreas críticas de preocupación, cada una de las cuales proporciona información sobre el estado operativo de su base de datos:
Tasa de consultas (Rate): evalúa el volumen de consultas o comandos ejecutados por segundo, ofreciendo una medida directa de la carga de trabajo del servidor. Es fundamental para evaluar la capacidad de la base de datos para manejar operaciones simultáneas y su capacidad de respuesta a las demandas de los usuarios.
Tasa de errores (Errores): el seguimiento de la frecuencia de errores en las consultas arroja luz sobre posibles problemas de confiabilidad dentro de la base de datos. Una tasa de error alta puede indicar problemas subyacentes con la sintaxis de la consulta, el esquema de la base de datos o las restricciones del sistema que están afectando la integridad general de la base de datos. La métrica principal de MySQL para la tasa de monitoreo es Aborted_clients.
Duración de la ejecución de la consulta (Duración): la métrica de duración es una medida del tiempo que tardan las consultas en completarse, desde el inicio hasta la ejecución. Este indicador de rendimiento evalúa la eficiencia de las operaciones de recuperación y procesamiento de datos que tienen un impacto directo en la experiencia del usuario y el rendimiento del sistema.
El estado de estas métricas le brinda una comprensión sólida del rendimiento de su base de datos y, a su vez, de la experiencia que están teniendo sus usuarios. El método RED facilita evaluar qué está mal en su base de datos y qué es necesario corregir. Por ejemplo, si descubre que las consultas se ejecutan con lentitud, podría indicar la necesidad de ajustar los índices u optimizar las consultas afectadas para aumentar la eficiencia.
8 métricas de rendimiento de MySQL esenciales para el método RED
Para aplicar el método RED de manera efectiva al monitoreo del rendimiento de MySQL, Releem se concentra en ocho aspectos críticos de su base de datos. Cada uno de estos está vinculado a la tasa, los errores o la duración de una forma u otra:
1. Latencia de MySQL
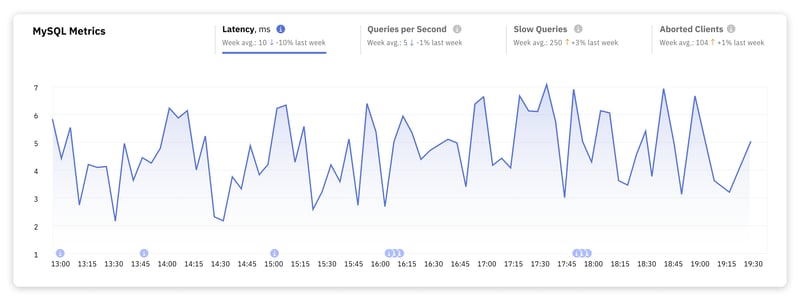
La latencia mide el tiempo que lleva ejecutar una consulta, desde el momento en que se envía una consulta a la base de datos hasta que la base de datos responde. La latencia influye directamente en cómo los usuarios perciben su aplicación.
Para la mayoría de las aplicaciones web, lograr una latencia en el rango de unos pocos milisegundos hasta aproximadamente 10 milisegundos para las operaciones de bases de datos se considera excelente. Este rango garantiza una experiencia de usuario perfecta, ya que el retraso es prácticamente imperceptible para el usuario final.
Una vez que la latencia alcanza la marca de 100 milisegundos y más para consultas simples a moderadamente complejas, los usuarios comienzan a notar un retraso. Esto puede resultar problemático cuando la retroalimentación inmediata es fundamental, como en el envío de formularios, consultas de búsqueda o carga de contenido dinámico.
Para obtener más información sobre la latencia de MySQL
2. Rendimiento
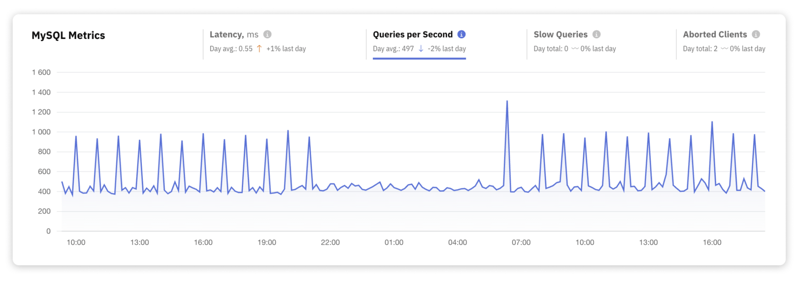
El rendimiento, cuantificado como consultas por segundo (QPS), mide la eficiencia de su base de datos y su capacidad para gestionar cargas de trabajo. Un alto rendimiento significa un sistema de base de datos bien optimizado que puede manejar volúmenes importantes de consultas de manera eficiente. El bajo rendimiento puede indicar cuellos de botella en el rendimiento o limitaciones de recursos.
Lograr un alto rendimiento normalmente implica una combinación de consultas SQL optimizadas, recursos de hardware adecuados (CPU, memoria y subsistemas de IO rápidos) y configuraciones de bases de datos optimizadas.
Para obtener más información sobre el rendimiento
3. Recuento de consultas lentas
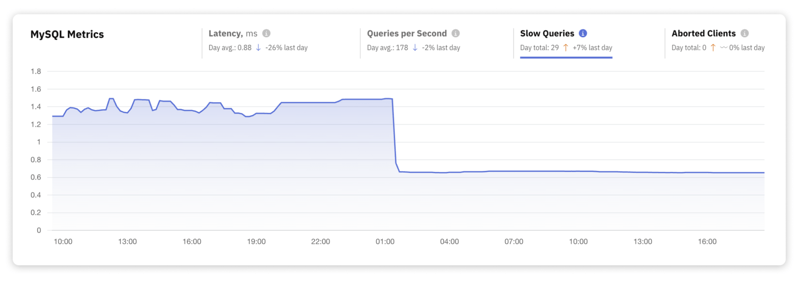
Las consultas lentas son esencialmente solicitudes de bases de datos que superan un umbral de tiempo de ejecución predefinido. Puede ajustar este umbral para adaptarlo a sus objetivos de rendimiento específicos o puntos de referencia operativos. Realizar un seguimiento del recuento de consultas lentas es la forma de identificar las consultas que necesitan optimización.
La identificación y el registro de estas consultas lentas se llevan a cabo en slow_query_log, un archivo dedicado creado para almacenar detalles sobre las consultas que no cumplen con los estándares de rendimiento establecidos.
Para obtener más información sobre el recuento de consultas lentas
4. Clientes abortados
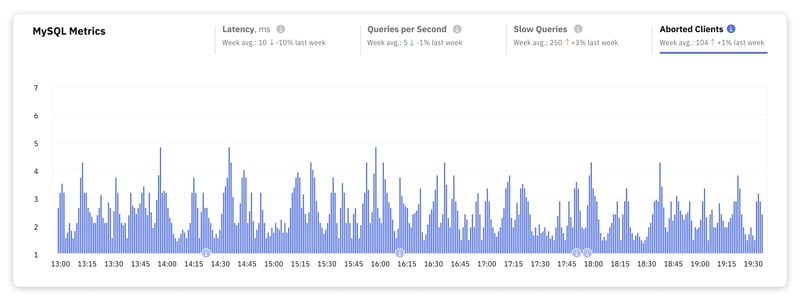
Esta métrica cuenta la cantidad de conexiones que se cancelaron porque el cliente no cerró correctamente la conexión. Un gran número de clientes abortados puede indicar una variedad de causas:
- Latencia de red y fluctuación que provocan tiempos de espera
- Límites de capacidad del servidor que provocan rechazos de conexión
- Contención de recursos entre consultas
- Ineficiencias derivadas de consultas de larga duración
- Configuraciones erróneas en la configuración de MySQL
- Errores de la aplicación que provocan desconexiones prematuras
Para obtener más información sobre clientes cancelados
5. Uso de la CPU
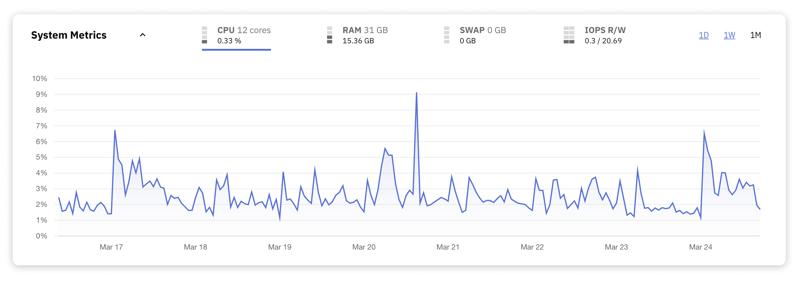
La CPU es el cerebro de su servidor. Ejecuta comandos y realiza cálculos que permiten que su base de datos almacene, recupere, modifique y elimine datos. Vigilar de cerca el uso de la CPU ayuda a garantizar que el servidor tenga suficiente potencia de procesamiento para manejar su carga de trabajo. El uso elevado de CPU puede ser una señal reveladora de que un servidor sobrecargado lucha por mantenerse al día con las demandas que se le imponen.
Aquí hay algunas pautas generales a considerar para el uso de la CPU:
50-70% sostenido: en este nivel, su CPU maneja una carga de trabajo de moderada a pesada de manera efectiva, pero todavía hay algo de margen para cargas máximas. Es un rango saludable para servidores en funcionamiento normal.
70-90 % sostenido: cuando el uso de la CPU cae constantemente dentro de este rango, indica una carga de trabajo elevada que deja un espacio limitado para manejar las demandas máximas. Debes monitorear el servidor de cerca.
Más del 90 % sostenido: este es un fuerte indicador de que el servidor se acerca a su capacidad o está en su capacidad. Es probable que se produzcan problemas de rendimiento notables, incluidos tiempos de respuesta de consultas lentos y posibles tiempos de espera. Es fundamental investigar la causa e implementar optimizaciones o escalar los recursos en consecuencia.
Nota: Los picos ocasionales por encima de estos umbrales pueden no necesariamente indicar un problema, ya que las bases de datos están diseñadas para manejar cargas variables. La palabra clave es sostenido. El uso elevado y sostenido es una señal de que su servidor está bajo una presión significativa.
6. Uso de RAM
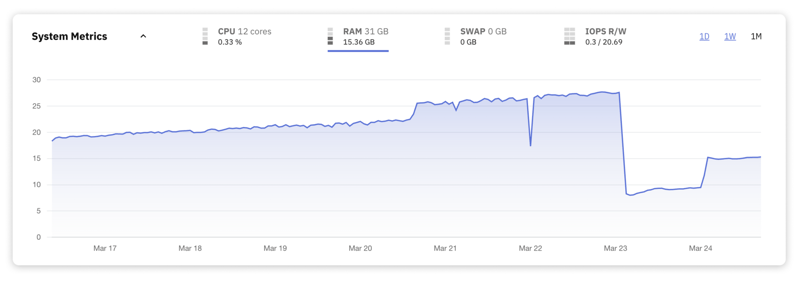
La RAM es un recurso clave para las bases de datos, ya que almacena datos e índices activos, lo que permite un acceso rápido y un procesamiento de consultas eficiente. La gestión adecuada del uso de RAM garantiza que la base de datos pueda manejar cargas de trabajo de manera eficiente, optimizando tanto las operaciones de recuperación como de manipulación de datos.
Aquí hay algunas pautas generales a considerar para el uso de RAM:
: este rango generalmente se considera seguro e indica que hay suficiente memoria disponible tanto para las operaciones actuales de la base de datos como para picos de carga de trabajo adicionales.
70-85% de utilización – Cuando el uso de RAM cae constantemente dentro de este rango, sugiere que la base de datos está haciendo un buen uso de la memoria disponible pero está comenzando a alcanzar el umbral para un monitoreo cuidadoso. . Mantenerse en este rango durante las horas pico puede limitar el margen para manejar aumentos repentinos de la demanda.
85-90% de utilización – En este rango, el servidor se está acercando a su capacidad de memoria. La utilización elevada de la memoria puede provocar un aumento de la E/S del disco a medida que el sistema comienza a intercambiar datos hacia y desde el disco. Considere esto como una señal de advertencia de que es necesario optimizar la carga de trabajo o ampliar la memoria física del servidor.
>95% de utilización – Operar con un uso de RAM del 95% o más es fundamental y es probable que cause problemas de rendimiento. En este nivel, el servidor puede recurrir con frecuencia al intercambio, lo que provoca graves ralentizaciones y potencialmente provoca tiempos de espera para las aplicaciones cliente. Se requiere una acción inmediata de su parte.
7. Uso de intercambio
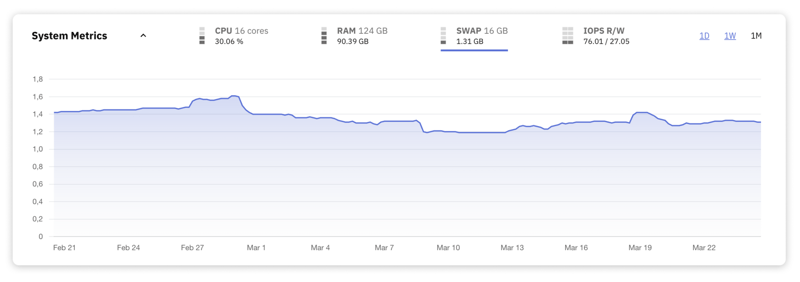
El espacio SWAP se utiliza cuando la RAM física de su base de datos se utiliza por completo, lo que permite que el sistema descargue algunos de los datos a los que se accede con menos frecuencia al almacenamiento en disco. Si bien este mecanismo es un amortiguador útil contra errores de falta de memoria, confiar en SWAP puede afectar gravemente el rendimiento debido a los tiempos de acceso significativamente más lentos en comparación con la RAM.
Lo ideal es que un servidor MySQL tenga un uso SWAP bajo o mínimo. Esto indica que la base de datos está funcionando dentro de su RAM disponible.
El uso elevado de SWAP es una señal de alerta que indica que la memoria física del servidor es insuficiente para su carga de trabajo, lo que lo obliga a depender del espacio en disco para las operaciones de datos de rutina. Debe tomar medidas inmediatas para solucionar este problema, optimizando las demandas de memoria de la aplicación o aumentando la RAM del servidor.
8. Operaciones de entrada/salida por segundo (IOPS)
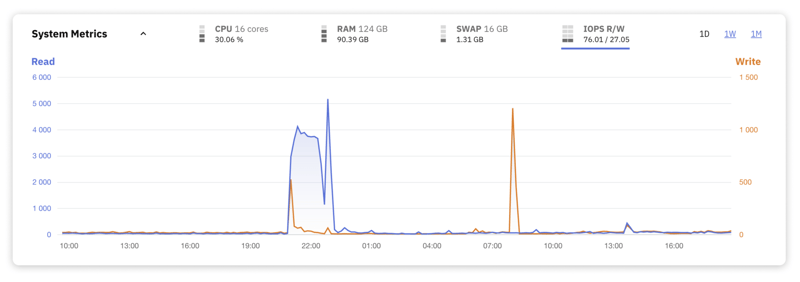
La métrica de operaciones de entrada/salida por segundo (IOPS) indica con qué intensidad interactúa su base de datos con su sistema de almacenamiento subyacente, también conocido como el disco. Los niveles altos de IOPS significan una gran carga de datos que se transfieren hacia y desde los medios de almacenamiento, lo que, si bien indica una base de datos ocupada, también puede resaltar posibles cuellos de botella en el rendimiento del disco.
Algunos factores clave que influyen en las IOPS incluyen:
- El tipo de medio de almacenamiento, donde los SSD suelen superar en velocidad a los HDD
- Configuraciones RAID, que pueden optimizarse para operaciones de lectura o escritura
- Las demandas específicas de la carga de trabajo de la base de datos, ya sea de lectura intensa o de escritura intensiva
- El nivel de simultaneidad y eficacia de las estrategias de almacenamiento en caché
Estrategia Integral de Releem para la Gestión de Bases de Datos
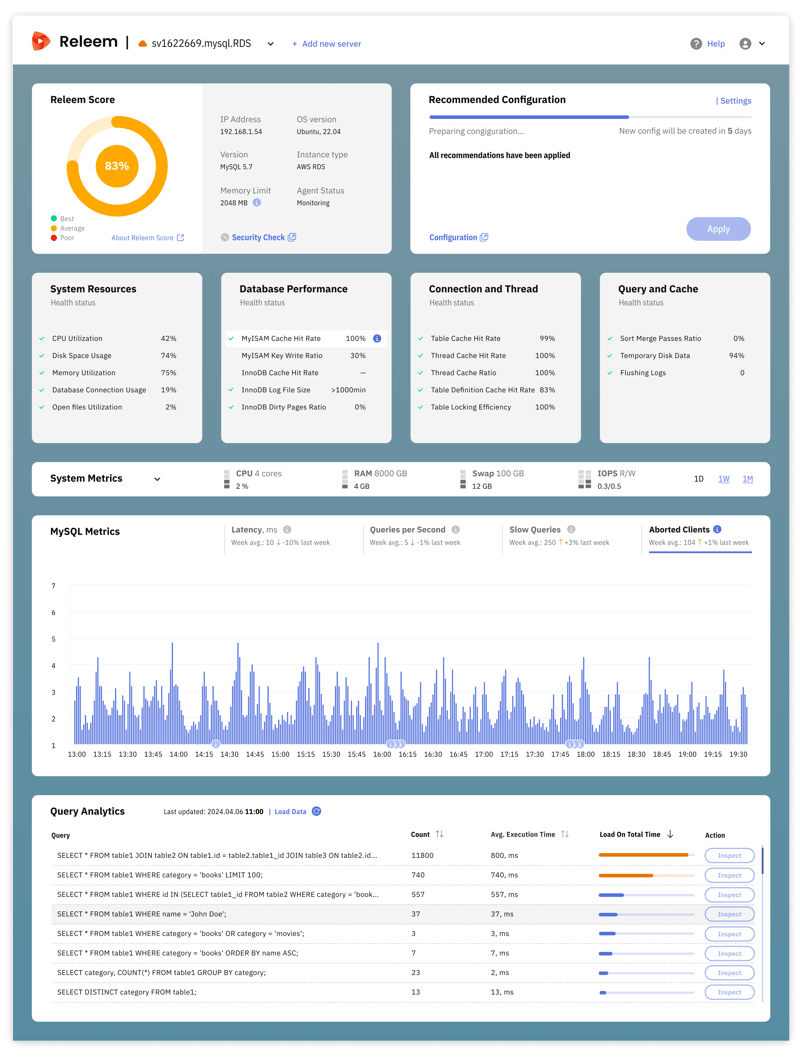
El enfoque de Releem para el monitoreo del rendimiento de MySQL consiste en mantener un ojo atento a los detalles importantes. Esta estrategia incluye un seguimiento diligente de las 8 métricas mencionadas (latencia de MySQL, rendimiento, consultas lentas, clientes abortados, CPU, RAM, uso de SWAP e IOPS), todo dentro del marco del Método RED. Al integrar este monitoreo como parte de los controles de estado dos veces al día (¡19 métricas!), Releem ayuda a que su base de datos alcance y mantenga altos niveles de rendimiento, confiabilidad y escalabilidad.
Más allá de simplemente controlar el rendimiento de MySQL, Releem va un paso más allá al ofrecer sugerencias de configuración personalizadas destinadas a solucionar cualquier problema descubierto durante el monitoreo. A esta función la llamamos Piloto automático para MySQL. Por ejemplo, si tiene problemas con una latencia alta, Releem le proporcionará información útil para volver a alinear sus números de latencia. Nuestro objetivo final es eliminar la necesidad de supervisión manual con un software potente e intuitivo que maneja todas las complejidades de la gestión de bases de datos de las que usted preferiría no preocuparse.
Releem tiene una amplia compatibilidad, por lo que ya sea que utilice Percona, MySQL o MariaDB para su sistema de administración de bases de datos, Releem puede ayudarlo. Consulte la lista oficial de sistemas compatibles aquí.
Para una exploración en profundidad de cada métrica y las mejores prácticas para el monitoreo y optimización de la base de datos MySQL, considere visitar Releem.com.
-
 ¿Cómo crear una cadena aleatoria de 5 caracteres con una duplicación mínima?Generación de 5 caracteres aleatorios con duplicación mínimaPara crear una cadena aleatoria de 5 caracteres con duplicación mínima, uno de los enfoque...Programación Publicado el 2024-11-06
¿Cómo crear una cadena aleatoria de 5 caracteres con una duplicación mínima?Generación de 5 caracteres aleatorios con duplicación mínimaPara crear una cadena aleatoria de 5 caracteres con duplicación mínima, uno de los enfoque...Programación Publicado el 2024-11-06 -
¿Cómo manejar firmas de métodos idénticos en diferentes paquetes en Go?Manejo de interfaces con firmas de métodos idénticas en diferentes paquetesEn Go, cuando se trata de múltiples interfaces con la misma firma de método...Programación Publicado el 2024-11-06
-
¿Cómo puedo completar un menú desplegable en cascada con jQuery para una mejor compatibilidad y experiencia de usuario?Rellenar un menú desplegable en cascada con jQueryEn el ámbito del desarrollo de formularios, los menús desplegables en cascada se utilizan con frecue...Programación Publicado el 2024-11-06
-
Comprensión del operador de extensión en JavaScript: una guía sencilla para principiantesIntroducción JavaScript es un lenguaje de programación divertido y una de sus características más interesantes es el operador de extensión. S...Programación Publicado el 2024-11-06
-
Dominar las operaciones CRUD con OpenSearch en Python: una guía prácticaOpenSearch, an open-source alternative to Elasticsearch, is a powerful search and analytics engine built to handle large datasets with ease. In this b...Programación Publicado el 2024-11-06
-
Concepto importante del marco frappe || cómo dominar el frappéPara dominar Frappe, hay varios conceptos y áreas clave en los que centrarse. Aquí hay un desglose de los más importantes: 1. Tipos de documen...Programación Publicado el 2024-11-06
-
¿Cómo resolver conflictos de eventos del mouse para arrastrar y soltar en JLabel?Eventos de mouse de JLabel para arrastrar y soltar: resolución de conflictos de eventos de mousePara habilitar la funcionalidad de arrastrar y soltar ...Programación Publicado el 2024-11-06
-
Fragmentación de bases de datos en MySQL: una guía completaEl control eficiente del rendimiento y el escalado surge a medida que las bases de datos se vuelven más grandes y complejas. La fragmentación de bases...Programación Publicado el 2024-11-06
-
¿Cómo convertir objetos de fecha y hora de Python a segundos?Conversión de objetos de fecha y hora a segundos en PythonCuando se trabaja con objetos de fecha y hora en Python, a menudo resulta necesario converti...Programación Publicado el 2024-11-06
-
¿Cómo optimizar eficazmente las operaciones CRUD utilizando el método firstOrNew() de Laravel Eloquent?Optimizando operaciones CRUD con Laravel EloquentCuando se trabaja con una base de datos en Laravel, es común insertar o actualizar registros. Para lo...Programación Publicado el 2024-11-06
-
¿Por qué la anulación de parámetros de métodos en PHP viola estándares estrictos?Anulación de parámetros de método en PHP: una violación de estándares estrictosEn la programación orientada a objetos, el principio de sustitución de ...Programación Publicado el 2024-11-06
-
¿Qué biblioteca PHP proporciona una prevención superior de inyección SQL: PDO o mysql_real_escape_string?PDO vs. mysql_real_escape_string: una guía completaEl escape de consultas es crucial para prevenir inyecciones de SQL. Si bien mysql_real_escape_strin...Programación Publicado el 2024-11-06
-
Comenzando con React: una hoja de ruta para principiantes¡Hola a todos! ? Acabo de comenzar mi viaje hacia el aprendizaje de React.js. Ha sido una aventura emocionante (¡y a veces desafiante!), y quería com...Programación Publicado el 2024-11-06
-
¿Cómo puedo hacer referencia a valores internos dentro de un objeto JavaScript?Cómo hacer referencia a valores internos dentro de un objeto JavaScriptEn JavaScript, acceder a valores dentro de un objeto que hacen referencia a otr...Programación Publicado el 2024-11-06















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









