 Página delantera > Programación > Uso de las bibliotecas Python de faker y pandas para crear datos sintéticos para pruebas
Página delantera > Programación > Uso de las bibliotecas Python de faker y pandas para crear datos sintéticos para pruebas
Uso de las bibliotecas Python de faker y pandas para crear datos sintéticos para pruebas
 Navegar:227
Navegar:227
Introducción:
Las pruebas exhaustivas son esenciales para las aplicaciones basadas en datos, pero a menudo dependen de tener los conjuntos de datos correctos, que pueden no siempre estar disponibles. Ya sea que esté desarrollando aplicaciones web, modelos de aprendizaje automático o sistemas backend, los datos realistas y estructurados son cruciales para una validación adecuada y garantizar un rendimiento sólido. La adquisición de datos del mundo real puede verse limitada debido a preocupaciones de privacidad, restricciones de licencia o simplemente la falta de disponibilidad de datos relevantes. Aquí es donde los datos sintéticos se vuelven valiosos.
En este blog, exploraremos cómo se puede utilizar Python para generar datos sintéticos para diferentes escenarios, que incluyen:
- Tablas interrelacionadas: que representan relaciones de uno a muchos.
- Datos jerárquicos: se utilizan a menudo en estructuras organizativas.
- Relaciones complejas: como relaciones de muchos a muchos en los sistemas de inscripción.
Aprovecharemos las bibliotecas faker y pandas para crear conjuntos de datos realistas para estos casos de uso.
Ejemplo 1: creación de datos sintéticos para clientes y pedidos (relación uno a muchos)
En muchas aplicaciones, los datos se almacenan en varias tablas con relaciones de clave externa. Generemos datos sintéticos para los clientes y sus pedidos. Un cliente puede realizar varios pedidos, lo que representa una relación de uno a muchos.
Generando la tabla de clientes
La tabla Clientes contiene información básica como CustomerID, nombre y dirección de correo electrónico.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
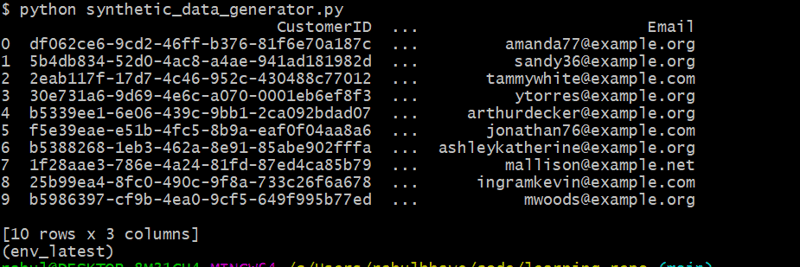
Este código genera 10 clientes aleatorios que utilizan Faker para crear nombres y direcciones de correo electrónico realistas.
Generando la tabla de pedidos
Ahora generamos la tabla Pedidos, donde cada pedido se asocia a un cliente a través de CustomerID.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
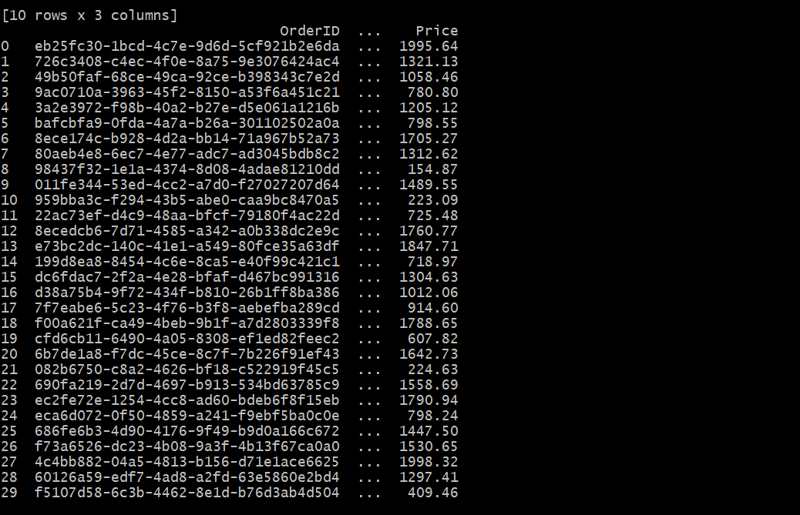
En este caso, la tabla Pedidos vincula cada pedido a un cliente mediante el CustomerID. Cada cliente puede realizar varios pedidos, formando una relación de uno a muchos.
Ejemplo 2: Generación de datos jerárquicos para departamentos y empleados
Los datos jerárquicos se utilizan a menudo en entornos organizacionales, donde los departamentos tienen varios empleados. Simulemos una organización con departamentos, cada uno de los cuales tiene varios empleados.
Generando la tabla de departamentos
La tabla Departamentos contiene el ID de departamento, el nombre y el administrador únicos de cada departamento.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
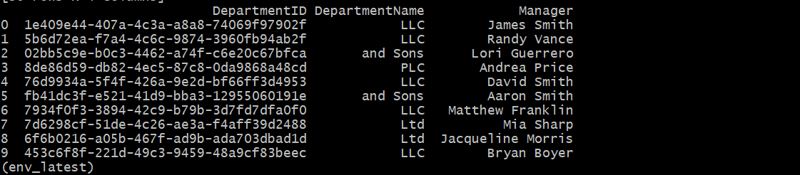
Generando la tabla de empleados
A continuación, generamos la tabla de Empleados, donde cada empleado está asociado con un departamento a través de DepartmentID.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
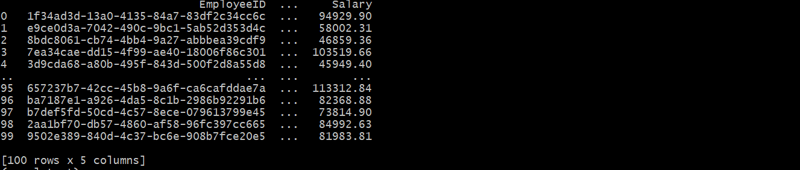
Esta estructura jerárquica vincula a cada empleado con un departamento a través del ID de departamento, formando una relación padre-hijo.
Ejemplo 3: Simulación de relaciones de muchos a muchos para inscripciones en cursos
En ciertos escenarios, existen relaciones de muchos a muchos, donde una entidad se relaciona con muchas otras. Simulemos esto con estudiantes que se inscriben en varios cursos, donde cada curso tiene varios estudiantes.
Generando la tabla de cursos
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
Generando la tabla de estudiantes
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
Generando la tabla de inscripciones a cursos
La tabla de inscripciones en cursos captura la relación de muchos a muchos entre estudiantes y cursos.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
En este ejemplo, creamos una tabla de vinculación para representar relaciones de muchos a muchos entre estudiantes y cursos.
Conclusión:
Al utilizar Python y bibliotecas como Faker y Pandas, puede generar conjuntos de datos sintéticos diversos y realistas para satisfacer una variedad de necesidades de prueba. En este blog, cubrimos:
- Tablas interrelacionadas: demuestran una relación de uno a muchos entre clientes y pedidos.
- Datos jerárquicos: ilustrando una relación padre-hijo entre departamentos y empleados.
- Relaciones complejas: simulación de relaciones de muchos a muchos entre estudiantes y cursos.
Estos ejemplos sientan las bases para generar datos sintéticos adaptados a sus necesidades. Otras mejoras, como la creación de relaciones más complejas, la personalización de datos para bases de datos específicas o el escalado de conjuntos de datos para pruebas de rendimiento, pueden llevar la generación de datos sintéticos al siguiente nivel.
Estos ejemplos proporcionan una base sólida para generar datos sintéticos. Sin embargo, se pueden realizar más mejoras para aumentar la complejidad y la especificidad, como por ejemplo:
- Datos específicos de la base de datos: personalización de la generación de datos para diferentes sistemas de bases de datos (p. ej., SQL frente a NoSQL).
- Relaciones más complejas: creación de interdependencias adicionales, como relaciones temporales, jerarquías de múltiples niveles o restricciones únicas.
- Escalar datos: Generar conjuntos de datos más grandes para pruebas de rendimiento o pruebas de estrés, garantizando que el sistema pueda manejar condiciones del mundo real a escala. Al generar datos sintéticos adaptados a sus necesidades, puede simular condiciones realistas para desarrollar, probar y optimizar aplicaciones sin depender de conjuntos de datos confidenciales o difíciles de adquirir.
Si te gusta el artículo, compártelo con tus amigos y colegas. Puedes conectarte conmigo en LinkedIn para discutir más ideas.
-
 ¿Cuál es la diferencia entre funciones anidadas y cierres en Python?Funciones anidadas vs. cierres en python mientras las funciones anidadas en Python se asemejan superficialmente a los cierres, son distintos f...Programación Publicado el 2025-04-27
¿Cuál es la diferencia entre funciones anidadas y cierres en Python?Funciones anidadas vs. cierres en python mientras las funciones anidadas en Python se asemejan superficialmente a los cierres, son distintos f...Programación Publicado el 2025-04-27 -
¿Cómo analizar los números en notación exponencial usando decimal.parse ()?analizando un número de la notación exponencial cuando intenta analizar una cadena expresada en notación exponencial usando decimal.parse (&qu...Programación Publicado el 2025-04-27
-
¿Cómo crear variables dinámicas en Python?Dynamic Variable Creation en python La capacidad de crear variables dinámicamente puede ser una herramienta poderosa, especialmente cuando se ...Programación Publicado el 2025-04-27
-
Método XML de análisis de PHP simple con colon de espacio de nombresanalizando xml con las colons de espacio de nombres en php simplexml encuentra dificultades al analizar XML que contiene etiquetas con colons,...Programación Publicado el 2025-04-27
-
¿Cómo redirigir múltiples tipos de usuarios (estudiantes, maestros y administradores) a sus respectivas actividades en una aplicación Firebase?rojo: cómo redirigir múltiples tipos de usuarios a las actividades respectivas Comprender el problema en una aplicación de votación basada...Programación Publicado el 2025-04-27
-
Resuelve la excepción \\ "Valor de cadena \\" cuando MySQL inserta emojiresolviendo una excepción de valor de cadena incorrecta al insertar emOJi Al intentar insertar una cadena que contenga caracteres emOJi en una b...Programación Publicado el 2025-04-27
-
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-04-27
-
Implementación dinámica reflectante de la interfaz GO para la exploración del método RPCReflection para la implementación de la interfaz dinámica en Go Reflection In GO es una herramienta poderosa que permite la inspección y manip...Programación Publicado el 2025-04-27
-
`console.log` muestra el motivo de la excepción de valor de objeto modificadoobjetos y console.log: una rareza desordenada cuando trabaja con objetos y console.log, puede encontrar un comportamiento peculiar. Desenvuelv...Programación Publicado el 2025-04-27
-
Razones por las cuales Python no informa errores al corte de la subconjuntos de hiperescopioSubstring Sliting con índice fuera de rango: dualidad y secuencias vacías en Python, acceder a elementos de una secuencia utilizando el operad...Programación Publicado el 2025-04-27
-
¿Cómo simplificar el análisis de JSON en PHP para matrices multidimensionales?Parsing JSON con php tratando de analizar los datos JSON en PHP puede ser un desafío, especialmente cuando se trata de matrices multidimensional...Programación Publicado el 2025-04-27
-
¿Cómo convertir una columna Pandas DataFrame a formato de fecha y hora de filtrar por fecha?transformar la columna Pandas DataFrame en formato de Datetime escenario: datos dentro de un marco de datos PANDAS a menudo existe en varios...Programación Publicado el 2025-04-27
-
Causas y soluciones para la falla de detección de cara: Error -215Error manejo: resolución "error: (-215)! Vacía () en function detectMultiscale" en openCV cuando intente utilizar el método detectar...Programación Publicado el 2025-04-27
-
¿Qué método para declarar múltiples variables en JavaScript es más mantenible?declarando múltiples variables en JavaScript: explorando dos métodos en JavaScript, los desarrolladores a menudo encuentran la necesidad de de...Programación Publicado el 2025-04-27
-
Método de corriente efectiva para cadenas de Java que no son vacías y no son nulasCompre 1.6 y más tarde, el método isEtimty () proporciona una forma concisa de verificar el vacío: if (str! = Null &&! Str.isEmEmEmEnty () o...Programación Publicado el 2025-04-27















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









