 Página delantera > Programación > Extracción de datos de archivos PDF complicados con Google Gemini en líneas de Python
Página delantera > Programación > Extracción de datos de archivos PDF complicados con Google Gemini en líneas de Python
Extracción de datos de archivos PDF complicados con Google Gemini en líneas de Python
 Navegar:942
Navegar:942
En esta guía, te mostraré cómo extraer datos estructurados de archivos PDF utilizando modelos de visión y lenguaje (VLM) como Gemini Flash o GPT-4o.
Gemini, la última serie de modelos de visión y lenguaje de Google, ha demostrado un rendimiento de vanguardia en la comprensión de textos e imágenes. Esta capacidad multimodal mejorada y su larga ventana de contexto lo hacen particularmente útil para procesar datos PDF visualmente complejos con los que tienen problemas los modelos de extracción tradicionales, como figuras, gráficos, tablas y diagramas.
Al hacerlo, puede crear fácilmente su propia herramienta de extracción de datos para archivos visuales y extracción web. Así es como:
La larga ventana de contexto y la capacidad multimodal de Gemini lo hacen particularmente útil para procesar datos PDF visualmente complejos donde los modelos de extracción tradicionales tienen dificultades.
Configurando su entorno
Antes de sumergirnos en la extracción, configuremos nuestro entorno de desarrollo. Esta guía asume que tiene Python instalado en su sistema. De lo contrario, descárguelo e instálelo desde https://www.python.org/downloads/
⚠️ Tenga en cuenta que, si no desea utilizar Python, puede utilizar la plataforma en la nube en thepi.pe para cargar sus archivos y descargar el resultado como CSV sin escribir ningún código.
Instalar las bibliotecas necesarias
Abre tu terminal o símbolo del sistema y ejecuta los siguientes comandos:
pip install git https://github.com/emcf/thepipe pip install pandas
Para aquellos nuevos en Python, pip es el instalador de paquetes para Python, y estos comandos descargarán e instalarán las bibliotecas necesarias.
Configure su clave API
Para usar thepipe, necesitas una clave API.
Descargo de responsabilidad: Si bien thepi.pe es una herramienta gratuita de código abierto, la API tiene un costo de aproximadamente $0,00002 por token. Si desea evitar dichos costos, consulte las instrucciones de configuración local en GitHub. Tenga en cuenta que aún tendrá que pagarle al proveedor de LLM de su elección.
A continuación se explica cómo obtenerlo y configurarlo:
- Visita https://thepi.pe/platform/
- Crea una cuenta o inicia sesión
- Encuentre su clave API en la página de configuración

Ahora, debe configurar esto como una variable de entorno. El proceso varía dependiendo de tu sistema operativo:
- Copia la clave API desde el menú de configuración de la Plataformapi.pe
Para Windows:
- Busque "Variables de entorno" en el menú Inicio
- Haga clic en "Editar las variables de entorno del sistema"
- Haga clic en el botón "Variables de entorno"
- En "Variables de usuario", haga clic en "Nuevo"
- Establece el nombre de la variable como THEPIPE_API_KEY y el valor como tu clave API
- Haga clic en "Aceptar" para guardar
Para macOS y Linux:
Abra su terminal y agregue esta línea a su archivo de configuración de shell (por ejemplo, ~/.bashrc o ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
Luego, recarga tu configuración:
source ~/.bashrc # or ~/.zshrc
Definición de su esquema de extracción
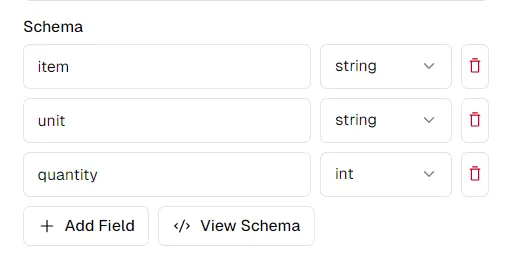
La clave para una extracción exitosa es definir un esquema claro para los datos que desea extraer. Digamos que estamos extrayendo datos de un documento de lista de cantidades:

Un ejemplo de una página del documento de lista de cantidades. Los datos de cada página son independientes de las otras páginas, por lo que hacemos nuestra extracción "por página". Hay varios datos para extraer por página, por lo que configuramos las extracciones múltiples en Verdadero
Al observar los nombres de las columnas, es posible que deseemos extraer un esquema como este:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
Puedes modificar el esquema a tu gusto en la Plataforma pi.pe. Al hacer clic en "Ver esquema", obtendrá un esquema que puede copiar y pegar para usarlo con la API de Python
Extraer datos de archivos PDF
Ahora, usemos extract_from_file para extraer datos de un PDF:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
Aquí tenemos chunking_method="chunk_by_page" porque queremos enviar cada página al modelo de IA individualmente (el PDF es demasiado grande para alimentarlo todo a la vez). También configuramos multiple_extractions=True porque cada una de las páginas PDF contiene varias filas de datos. Así es como se ve una página del PDF:
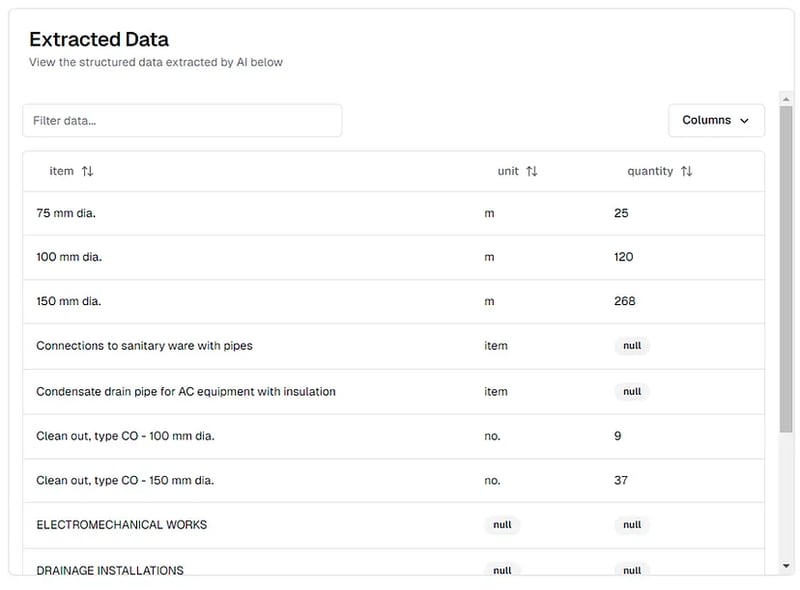
Los resultados de la extracción del PDF de la Lista de Cantidades vistos en la Plataforma pi.pe
Procesando los resultados
Los resultados de la extracción se devuelven como una lista de diccionarios. Podemos procesar estos resultados para crear un DataFrame de pandas:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
Esto crea un DataFrame con toda la información extraída, incluido el contenido textual y descripciones de elementos visuales como figuras y tablas.
Exportar a diferentes formatos
Ahora que tenemos nuestros datos en un DataFrame, podemos exportarlos fácilmente a varios formatos. Aquí hay algunas opciones:
Exportar a Excel
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
Esto crea un archivo de Excel llamado "extracted_research_data.xlsx" con una hoja llamada "Datos de investigación". El parámetro index=False evita que el índice del DataFrame se incluya como una columna independiente.
Exportar a CSV
Si prefieres un formato más simple, puedes exportar a CSV:
df.to_csv("extracted_research_data.csv", index=False)
Esto crea un archivo CSV que se puede abrir en Excel o en cualquier editor de texto.
Notas finales
La clave para una extracción exitosa radica en definir un esquema claro y utilizar las capacidades multimodales del modelo de IA. A medida que se sienta más cómodo con estas técnicas, podrá explorar funciones más avanzadas, como métodos de fragmentación personalizados, indicaciones de extracción personalizadas e integración del proceso de extracción en canales de datos más grandes.
-
 Guía para resolver problemas de Cors en Spring Security 4.1 y superiorSpring Security Cors Filter: Solución de problemas de problemas comunes Al integrar la seguridad de la primavera en un proyecto existente, pue...Programación Publicado el 2025-04-27
Guía para resolver problemas de Cors en Spring Security 4.1 y superiorSpring Security Cors Filter: Solución de problemas de problemas comunes Al integrar la seguridad de la primavera en un proyecto existente, pue...Programación Publicado el 2025-04-27 -
¿Cómo enviar una solicitud de publicación en bruto con Curl en PHP?Cómo enviar una solicitud de publicación sin procesar usando curl en php en php, Curl es una biblioteca popular para enviar solicitudes HTTP. ...Programación Publicado el 2025-04-27
-
¿Por qué Java no puede crear matrices genéricas?Error de creación de matriz genérica [&] pregunta: cuando intentan crear una variedad de clases genéricas usando una expresión como: Publi...Programación Publicado el 2025-04-27
-
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-04-27
-
¿Cómo puedo personalizar las optimizaciones de compilación en el compilador GO?Personalización de optimizaciones de compilación En compilador GO El proceso de compilación predeterminado en Go sigue una estrategia de optim...Programación Publicado el 2025-04-27
-
¿Cómo extraer elementos de la matriz 2D? Usando el índice de otra matrizusando la matriz numpy como índices para la 2nd dimension de otra matriz para extraer elementos específicos de una 2D basada en los índices pr...Programación Publicado el 2025-04-27
-
¿Cómo puedo mantener la representación de celda JTable personalizada después de la edición de la celda?manteniendo la representación de la celda JTable después de la edición de celda en una jtable, implementar capacidades de representación y edi...Programación Publicado el 2025-04-27
-
¿Qué método es más eficiente para la detección de Point-in-Polygon: Ray Tracing o Matplotlib \ 's Rath.Contains_Points?Detección eficiente de Point-in-Polygon en python determinando si un punto se encuentra dentro de un polígono es una tarea frecuente en la geome...Programación Publicado el 2025-04-27
-
Resuelve la excepción \\ "Valor de cadena \\" cuando MySQL inserta emojiresolviendo una excepción de valor de cadena incorrecta al insertar emOJi Al intentar insertar una cadena que contenga caracteres emOJi en una b...Programación Publicado el 2025-04-27
-
¿Cómo se extraen un elemento aleatorio de una matriz en PHP?Selección aleatoria de una matriz en php, la obtención de un elemento aleatorio de una matriz se puede lograr con facilidad. Considere la siguie...Programación Publicado el 2025-04-27
-
¿Por qué Microsoft Visual C ++ no implementa correctamente la instanciación de la plantilla de dos fases?El misterio de la plantilla de dos fases "roto" instanciación en Microsoft Visual c declaración de problemas: usuarios comúnmente ...Programación Publicado el 2025-04-27
-
¿Cómo envía Android los datos de publicación al servidor PHP?enviando datos de publicaciones en android introducción Este artículo aborda la necesidad de enviar datos de publicación a un script de PH...Programación Publicado el 2025-04-27
-
¿Por qué cesan la ejecución de JavaScript cuando se usa el botón de retroceso de Firefox?Problema de historial de navegación: JavaScript deja de ejecutar después de usar el botón de retroceso de Firefox Los usuarios de Firefox pued...Programación Publicado el 2025-04-26
-
¿Cómo implementar una función hash genérica para tuplas en colecciones desordenadas?Función hash genérica para tuplas en colecciones no ordenadas los contenedores std :: unordened_map y std :: unordened_set proporcionan una mi...Programación Publicado el 2025-04-26
-
¿Cómo acceder dinámicamente a las variables globales en JavaScript?Acceder a variables globales dinámicamente por nombre en javascript a las variables globales durante el tiempo de ejecución puede ser un requisi...Programación Publicado el 2025-04-26















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









