 Página delantera > Programación > Evaluación de un modelo de clasificación de aprendizaje automático
Página delantera > Programación > Evaluación de un modelo de clasificación de aprendizaje automático
Evaluación de un modelo de clasificación de aprendizaje automático
 Navegar:479
Navegar:479
Describir
- ¿Cuál es el objetivo de la evaluación del modelo?
- ¿Cuál es el propósito de la evaluación de modelos y cuáles son algunos? ¿Procedimientos de evaluación comunes?
- ¿Cuál es el uso de la precisión de la clasificación y cuáles son sus ¿Limitaciones?
- ¿Cómo describe una matriz de confusión el desempeño de un clasificador?
- ¿Qué métricas se pueden calcular a partir de una matriz de confusión?
Eel objetivo de la evaluación de modelos es responder a la pregunta;
¿cómo elijo entre diferentes modelos?
El proceso de evaluación de un aprendizaje automático ayuda a determinar qué tan confiable y efectivo es el modelo para su aplicación. Esto implica evaluar diferentes factores como su rendimiento, métricas y precisión para las predicciones o la toma de decisiones.
No importa qué modelo elijas usar, necesitas una forma de elegir entre modelos: diferentes tipos de modelos, parámetros de ajuste y características. También necesita un procedimiento de evaluación del modelo para estimar qué tan bien se generalizará un modelo a datos invisibles. Por último, necesita un procedimiento de evaluación que combine con su procedimiento para cuantificar el rendimiento de su modelo.
Antes de continuar, revisemos algunos de los diferentes procedimientos de evaluación de modelos y cómo funcionan.
Procedimientos de evaluación modelo y cómo operan.
-
Capacitación y pruebas sobre los mismos datos
- Recompensa los modelos demasiado complejos que "se ajustan demasiado" a los datos de entrenamiento y no necesariamente se generalizarán
-
División de entrenamiento/prueba
- Dividir el conjunto de datos en dos partes, para que el modelo pueda entrenarse y probarse con diferentes datos
- Mejor estimación del rendimiento fuera de la muestra, pero sigue siendo una estimación de "alta varianza"
- Útil por su rapidez, sencillez y flexibilidad
-
Validación cruzada K-fold
- Cree sistemáticamente divisiones de tren/prueba "K" y promedie los resultados juntos
- Estimación aún mejor del rendimiento fuera de la muestra
- Se ejecuta "K" veces más lento que la división tren/prueba.
De lo anterior podemos deducir que:
Entrenar y probar con los mismos datos es una causa clásica de sobreajuste en el que se construye un modelo demasiado complejo que no se generalizará a nuevos datos y que en realidad no es útil.
Train_Test_Split proporciona una estimación mucho mejor del rendimiento fuera de muestra.
La validación cruzada de K veces funciona mejor al dividir sistemáticamente las pruebas del tren K y promediar los resultados juntos.
En resumen, train_tests_split sigue siendo rentable para la validación cruzada debido a su velocidad y simplicidad, y eso es lo que usaremos en esta guía tutorial.
Métricas de evaluación del modelo:
Siempre necesitará una métrica de evaluación que acompañe el procedimiento elegido, y su elección de métrica depende del problema que esté abordando. Para problemas de clasificación, puede utilizar la precisión de clasificación. Pero nos centraremos en otras métricas importantes de evaluación de clasificación en esta guía.
Antes de conocer nuevas métricas de evaluación, revisemos la precisión de la clasificación y hablemos sobre sus fortalezas y debilidades.
Precisión de clasificación
Hemos elegido el conjunto de datos de diabetes de los indios Pima para este tutorial, que incluye los datos de salud y el estado de diabetes de 768 pacientes.
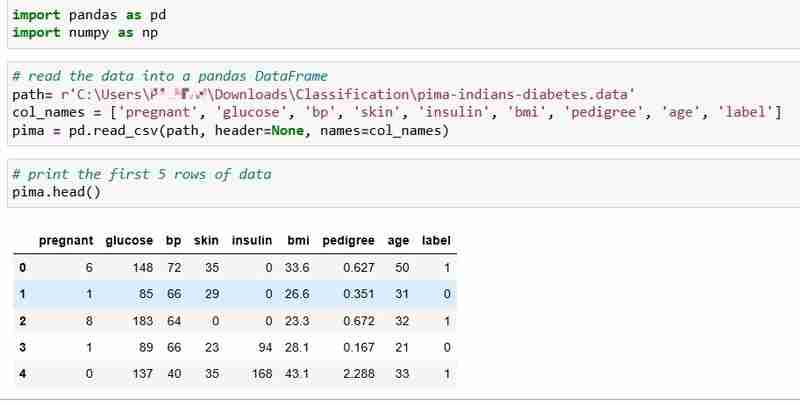
Leamos los datos e imprimamos las primeras 5 filas de los datos. La columna de la etiqueta indica 1 si el paciente tiene diabetes y 0 si el paciente no tiene diabetes, y pretendemos responder la pregunta:
Pregunta: ¿Podemos predecir el estado de diabetes de un paciente según sus mediciones de salud?
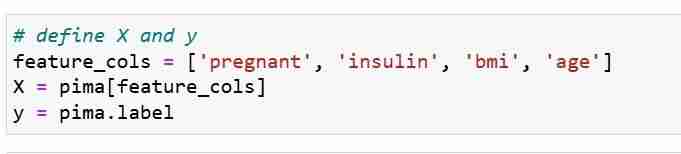
Definimos nuestras métricas de características X y el vector de respuesta Y. Usamos train_test_split para dividir X e Y en un conjunto de entrenamiento y prueba.
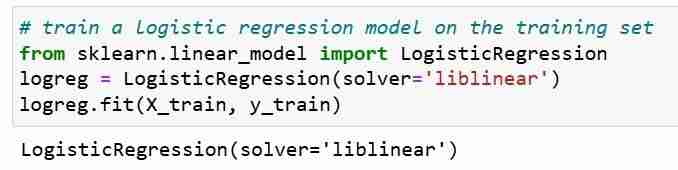
A continuación, entrenamos un modelo de regresión logística en un conjunto de entrenamiento. Durante el paso de ajuste, el objeto del modelo logreg aprende la relación entre X_train e Y_train. Finalmente hacemos predicciones de clase para los conjuntos de prueba.

Ahora que hemos hecho predicciones para el conjunto de pruebas, podemos calcular la precisión de la clasificación, que es simplemente el porcentaje de predicciones correctas.
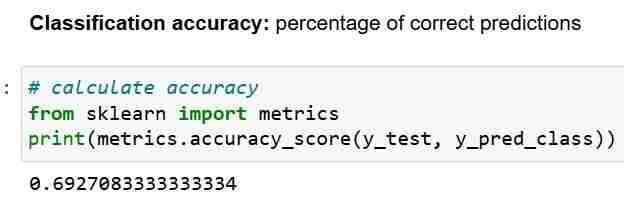
Sin embargo, cada vez que utilice la precisión de la clasificación como métrica de evaluación, es importante compararla con la precisión nula, que es la precisión que se puede lograr prediciendo siempre la clase más frecuente.

Precisión nula responde a la pregunta; Si mi modelo fuera a predecir la clase predominante el 100 por ciento de las veces, ¿con qué frecuencia será correcto? En el escenario anterior, el 32% de y_test son 1 (unidades). En otras palabras, un modelo tonto que predice que los pacientes tienen diabetes acertaría el 68% de las veces (que son los ceros). Esto proporciona una línea de base contra la cual podríamos querer medir nuestra regresión logística. modelo.
Cuando comparamos la precisión nula de 68% y la precisión del modelo de 69%, nuestro modelo no se ve muy bien. Esto demuestra una debilidad de la precisión de la clasificación como métrica de evaluación del modelo. La precisión de la clasificación no nos dice nada sobre la distribución subyacente de la prueba.
En resumen:
- La precisión de la clasificación es la métrica de clasificación más fácil de entender
- Pero no le indica la distribución subyacente de los valores de respuesta
- Y no te dice qué "tipos" de errores está cometiendo tu clasificador.
Veamos ahora la matriz de confusión.
Matriz de confusión
La matriz de confusión es una tabla que describe el rendimiento de un modelo de clasificación.
Es útil para ayudarle a comprender el rendimiento de su clasificador, pero no es una métrica de evaluación del modelo; entonces no puedes decirle a scikit que aprenda a elegir el modelo con la mejor matriz de confusión. Sin embargo, hay muchas métricas que se pueden calcular a partir de la matriz de confusión y que se pueden usar directamente para elegir entre modelos.
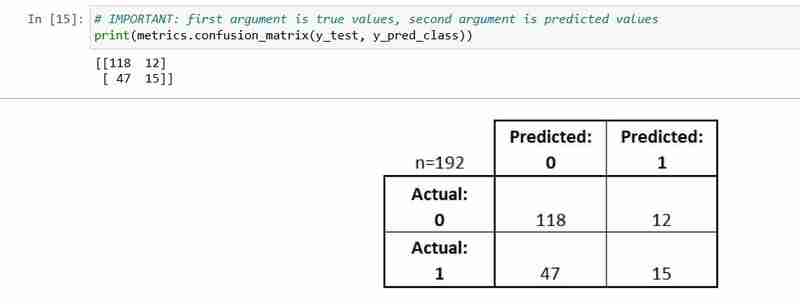
- Cada observación en el conjunto de pruebas está representada en exactamente un cuadro
- Es una matriz de 2x2 porque hay 2 clases de respuesta
- El formato que se muestra aquí es no universal
Expliquemos algunas de sus terminologías básicas.
- Verdaderos Positivos (TP): nosotros correctamente predijimos que ellos tienen diabetes
- Verdaderos negativos (TN): nosotros correctamente predijimos que ellos no tienen diabetes
- Falsos positivos (FP): nosotros predijimos incorrectamente que ellos tienen diabetes (un "error de tipo I")
- Falsos negativos (FN): nosotros predijimos incorrectamente que ellos no tienen diabetes (un "error de tipo II")
Veamos cómo podemos calcular las métricas
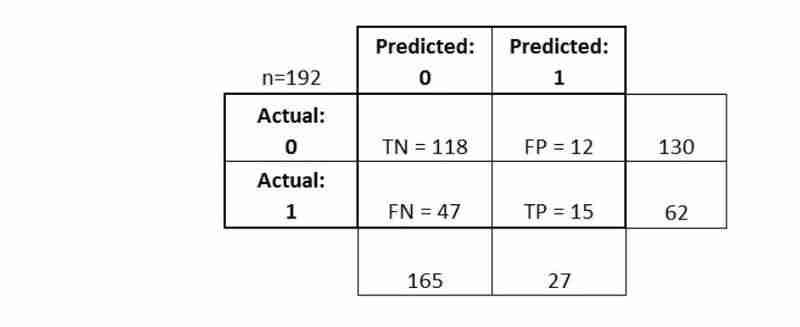


En conclusión:
- La matriz de confusión le brinda una imagen más completa de cómo se está desempeñando su clasificador
- También le permite calcular varias métricas de clasificación, y estas métricas pueden guiar su selección de modelo
-
 ¿Cómo recuperar eficientemente la última fila para cada identificador único en PostgreSQL?postgresql: extrayendo la última fila para cada identificador único en postgresql, puede encontrar situaciones en las que necesita extraer la ...Programación Publicado el 2025-07-13
¿Cómo recuperar eficientemente la última fila para cada identificador único en PostgreSQL?postgresql: extrayendo la última fila para cada identificador único en postgresql, puede encontrar situaciones en las que necesita extraer la ...Programación Publicado el 2025-07-13 -
Causas y soluciones para la falla de detección de cara: Error -215Error manejo: resolución "error: (-215)! Vacía () en function detectMultiscale" en openCV cuando intente utilizar el método detectar...Programación Publicado el 2025-07-13
-
Implementación dinámica reflectante de la interfaz GO para la exploración del método RPCReflection para la implementación de la interfaz dinámica en Go Reflection In GO es una herramienta poderosa que permite la inspección y manip...Programación Publicado el 2025-07-13
-
¿Cómo recuperar la última biblioteca jQuery de Google API?recuperando la última biblioteca jQuery de Google APIS La URL de jQuery proporcionada en la pregunta es para la versión 1.2.6. Para recuperar ...Programación Publicado el 2025-07-13
-
¿Cómo resolver las discrepancias de la ruta del módulo en el mod utilizando la Directiva Reemplazar?Superación del módulo Discrepancia en el mod Al utilizar el mod, es posible encontrar un conflicto en el que un paquete de terceros importe ot...Programación Publicado el 2025-07-13
-
¿Cómo establecer dinámicamente las claves en los objetos JavaScript?cómo crear una clave dinámica para una variable de objeto JavaScript al intentar crear una clave dinámica para un objeto JavaScript, usando esta...Programación Publicado el 2025-07-13
-
¿Cómo puedo concatenar de forma segura los textos y los valores al construir consultas SQL en GO?concatenando texto y valores en go sql consultas al construir una consulta sql de texto en go, hay ciertas reglas de sintaxis a seguir cuando ...Programación Publicado el 2025-07-13
-
Método XML de análisis de PHP simple con colon de espacio de nombresanalizando xml con las colons de espacio de nombres en php simplexml encuentra dificultades al analizar XML que contiene etiquetas con colons,...Programación Publicado el 2025-07-13
-
Método para convertir correctamente los caracteres LATIN1 en UTF8 en UTF8 MySQL Tableconverse los caracteres latin1 en una tabla utf8 a utf8 ha encontrado un problema donde los caracteres con diacrísos "mysql_set_charset (...Programación Publicado el 2025-07-13
-
Python forma eficiente de eliminar las etiquetas HTML del textoeliminando las etiquetas HTML en Python para una representación textual prístina manipular las respuestas HTML a menudo implica extraer conten...Programación Publicado el 2025-07-13
-
¿Cómo pasar punteros exclusivos como función o parámetros de constructor en C ++?Gestión de punteros únicos como parámetros en constructores y funciones únicos indicadores ( unique_ptr ) para que los principios de la propieda...Programación Publicado el 2025-07-13
-
¿Cómo puedo ejecutar múltiples declaraciones SQL en una sola consulta usando nodo-mysql?múltiple consulta de consulta en nodo-mysql en node.js, la pregunta surge al ejecutar múltiples estaciones sql en una sola consulta utilizando...Programación Publicado el 2025-07-13
-
Python Leer el archivo CSV UnicodeDeCodeError Ultimate Solutionunicode decode error en el archivo csv lectura al intentar leer un archivo csv en python usando el modulo CSV incorporado, (unicodeScal No se ...Programación Publicado el 2025-07-13
-
Spark DataFrame Consejos para agregar columnas constantescreando una columna constante en un Spark DataFrame agregando una columna constante a un Spark DataFrame con un valor arbitrario que se aplica...Programación Publicado el 2025-07-13
-
¿Cómo puede usar los datos de Group by para pivotar en MySQL?pivotando resultados de consulta usando el grupo mySQL mediante en una base de datos relacional, los datos giratorios se refieren al reorganiz...Programación Publicado el 2025-07-13















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









