
ETL: extraer el nombre de una persona del texto
 Navegar:891
Navegar:891
Digamos que queremos eliminar chicagomusiccompass.com.
Como puedes ver, tiene varias tarjetas, cada una de las cuales representa un evento. Ahora, veamos el siguiente:
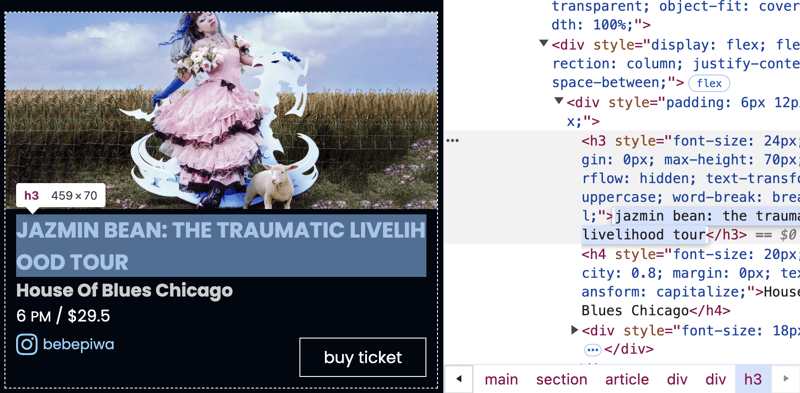
Observa que el nombre del evento es:
jazmin bean: the traumatic livelihood tour
Así que ahora la pregunta es: ¿Cómo extraemos el nombre del artista del texto?
Como ser humano, puedo decir "fácilmente" que jazmin bean es el artista; simplemente consulte su página wiki. Pero escribir código para extraer ese nombre puede resultar complicado.
Podríamos pensar: "Oye, cualquier cosa antes de : debería ser el nombre del artista", lo cual parece inteligente, ¿verdad? Funciona para este caso, pero ¿qué pasa con este?
happy hour on the patio: kathryn & chris
Aquí, el orden está invertido. Podríamos seguir agregando lógica para manejar diferentes casos, pero pronto terminaremos con un montón de reglas que son frágiles y probablemente no cubrirán todo.
Ahí es donde los modelos de reconocimiento de entidades nombradas (NER) resultan útiles. Son de código abierto y pueden ayudarnos a extraer nombres del texto. No detectará todos los casos, pero la mayoría de las veces nos proporcionarán la información que necesitamos.
Con este enfoque, la extracción se vuelve mucho más fácil. Me decanto por Python porque la comunidad en torno al aprendizaje automático en Python es simplemente inmejorable.
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = "jazmin bean: the traumatic livelihood tour"
labels = ["person", "bands", "projects"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
Que genera la salida:
jazmin bean => person
Ahora, echemos un vistazo a ese otro caso:
happy hour on the patio: kathryn & chris
Producción:
kathryn => person chris => person
fuente-GLiNER
Impresionante, ¿verdad? No más lógica tediosa para extraer nombres, solo use un modelo. Claro, no cubrirá todos los casos posibles, pero para mi proyecto, este nivel de flexibilidad funciona bien. Si necesita más precisión, siempre puede:
- Prueba con un modelo diferente
- Contribuir al modelo existente
- Bifurca el proyecto y modifícalo para que se ajuste a tus necesidades
Conclusión
Como desarrollador de software, es muy recomendable mantenerse actualizado con las herramientas en el espacio de aprendizaje automático. No todo se puede resolver simplemente con programación y lógica; algunos desafíos se abordan mejor utilizando modelos y estadísticas.
-
 Optimización del código Python utilizando el módulo cProfile y PyPy: una guía completaIntroducción Como desarrolladores de Python, a menudo nos concentramos en hacer que nuestro código funcione antes de preocuparnos por optimiz...Programación Publicado el 2024-11-07
Optimización del código Python utilizando el módulo cProfile y PyPy: una guía completaIntroducción Como desarrolladores de Python, a menudo nos concentramos en hacer que nuestro código funcione antes de preocuparnos por optimiz...Programación Publicado el 2024-11-07 -
Lo que aprendí la semana pasada (Reactividad en JavaScript básico: use el patrón Proxy para activar eventos cuando cambie el estado de la aplicación. (Curso de maestría en frontend:...Programación Publicado el 2024-11-07
-
¿Cómo puedo ejecutar mi aplicación Java como servicio en un sistema Linux?Navegación por los servicios del sistema Linux: ejecución de aplicaciones Java como serviciosEn el ámbito de la administración del sistema Linux, admi...Programación Publicado el 2024-11-07
-
Cómo crear una versión específica de un proyecto angular sin instalar Angular CLI¿Estás trabajando con Angular y necesitas configurar proyectos con diferentes versiones de Angular? ¡Aquí hay una guía sencilla para crear proyectos d...Programación Publicado el 2024-11-07
-
¿Cómo se invierte la dirección del texto en CSS?Cómo invertir la dirección del texto en CSSAl trabajar con texto, puede haber situaciones en las que necesites invertir su dirección, de modo que fluy...Programación Publicado el 2024-11-07
-
Cómo eliminar el prefijo \"data-\" de cadenas con JavaScriptEliminar prefijos de cadenas: eliminar "datos-"Muchas tareas de programación implican manipular cadenas. Una tarea común es eliminar partes ...Programación Publicado el 2024-11-07
-
## Cómo perfilar eficazmente el uso de la memoria PHP: alternativas y mejores prácticas de XdebugAnálisis del consumo de memoria de PHPBusca una manera de examinar el uso de memoria de una página PHP. Específicamente, su objetivo es determinar la ...Programación Publicado el 2024-11-07
-
Cómo se renderizan los componentes en un DOM virtual y cómo optimizar el renderizadoAl crear aplicaciones web modernas, actualizar eficientemente la UI (interfaz de usuario) es esencial para mantener las aplicaciones rápidas y recepti...Programación Publicado el 2024-11-07
-
Operaciones CRUD: ¿Qué son y cómo puedo utilizarlas?Operaciones CRUD: ¿Qué son y cómo puedo utilizarlas? Las operaciones CRUD (Crear, Leer, Actualizar y Eliminar) son fundamentales para cualqui...Programación Publicado el 2024-11-07
-
Presentamos el paquete de utilidades Java gratuitoUn conjunto de herramientas de programación rápido y fácil de usar para el desarrollador backend de Java En mi vida profesional como administrador y d...Programación Publicado el 2024-11-07
-
¿Cómo recuperar claves de matriz en un bucle PHP Foreach para matrices anidadas?PHP: Recuperar claves de matriz en el bucle ForeachEn PHP, iterar sobre una matriz asociativa usando el bucle foreach proporciona acceso a ambos valor...Programación Publicado el 2024-11-07
-
¿Cómo convertir caracteres Latin1 a UTF-8 en una tabla MySQL?Convierta caracteres Latin1 en una tabla UTF8 a UTF8Ha identificado que sus scripts PHP carecían de la función mysql_set_charset necesaria para garant...Programación Publicado el 2024-11-07
-
Cómo utilizar la API de Zapcap (API para subtítulos)Integrar la API de ZapCap para el procesamiento automatizado de video en sus sistemas existentes es un proceso sencillo diseñado para minimizar la com...Programación Publicado el 2024-11-07
-
Explorar componentes de arranqueBootstrap 5, uno de los frameworks front-end más populares, ofrece una variedad de componentes y utilidades útiles que ayudan a los desarrolladores a ...Programación Publicado el 2024-11-07
-
Simplifique la gestión de SVG: convierta rutas en un único archivo JS de constantesAl crear aplicaciones React.js, administrar los íconos SVG de manera eficiente es crucial. Los SVG brindan la escalabilidad y flexibilidad necesarias...Programación Publicado el 2024-11-07















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









