 Página delantera > Programación > Flujo de trabajo completo de aprendizaje automático con Scikit-Learn: predicción de los precios de la vivienda en California
Página delantera > Programación > Flujo de trabajo completo de aprendizaje automático con Scikit-Learn: predicción de los precios de la vivienda en California
Flujo de trabajo completo de aprendizaje automático con Scikit-Learn: predicción de los precios de la vivienda en California
 Navegar:589
Navegar:589
Introducción
En este artículo, demostraremos un flujo de trabajo completo de un proyecto de aprendizaje automático utilizando Scikit-Learn. Construiremos un modelo para predecir los precios de la vivienda en California en función de diversas características, como el ingreso medio, la antigüedad de la vivienda y el número promedio de habitaciones. Este proyecto lo guiará a través de cada paso del proceso, incluida la carga de datos, la exploración, la capacitación del modelo, la evaluación y la visualización de resultados. Ya sea un principiante que busca comprender los conceptos básicos o un profesional experimentado que busca un repaso, este artículo le brindará información valiosa sobre la aplicación práctica de las técnicas de aprendizaje automático.
Proyecto de predicción del precio de la vivienda en California
1. Introducción
El mercado inmobiliario de California es conocido por sus características únicas y su dinámica de precios. En este proyecto, nuestro objetivo es desarrollar un modelo de aprendizaje automático para predecir los precios de la vivienda en función de varias características. Usaremos el conjunto de datos de vivienda de California, que incluye varios atributos, como ingreso medio, antigüedad de la vivienda, habitaciones promedio y más.
2. Importación de bibliotecas
En esta sección, importaremos las bibliotecas necesarias para la manipulación y visualización de datos y la construcción de nuestro modelo de aprendizaje automático.
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.datasets import fetch_california_housing
3. Cargando el conjunto de datos
Cargaremos el conjunto de datos de Vivienda de California y crearemos un DataFrame para organizar los datos. La variable objetivo, que es el precio de la vivienda, se agregará como una nueva columna.
# Load the California Housing dataset california = fetch_california_housing() df = pd.DataFrame(california.data, columns=california.feature_names) df['PRICE'] = california.target
4. Seleccionar muestras aleatoriamente
Para que el análisis sea manejable, seleccionaremos aleatoriamente 700 muestras del conjunto de datos para nuestro estudio.
# Randomly Selecting 700 Samples df_sample = df.sample(n=700, random_state=42)
5. Mirando nuestros datos
Esta sección proporcionará una descripción general del conjunto de datos, mostrando las primeras cinco filas para comprender las características y la estructura de nuestros datos.
# Overview of the data
print("First five rows of the dataset:")
print(df_sample.head())
Producción
First five rows of the dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude \
20046 1.6812 25.0 4.192201 1.022284 1392.0 3.877437 36.06
3024 2.5313 30.0 5.039384 1.193493 1565.0 2.679795 35.14
15663 3.4801 52.0 3.977155 1.185877 1310.0 1.360332 37.80
20484 5.7376 17.0 6.163636 1.020202 1705.0 3.444444 34.28
9814 3.7250 34.0 5.492991 1.028037 1063.0 2.483645 36.62
Longitude PRICE
20046 -119.01 0.47700
3024 -119.46 0.45800
15663 -122.44 5.00001
20484 -118.72 2.18600
9814 -121.93 2.78000
Mostrar información del marco de datos
print(df_sample.info())
Producción
Index: 700 entries, 20046 to 5350 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 700 non-null float64 1 HouseAge 700 non-null float64 2 AveRooms 700 non-null float64 3 AveBedrms 700 non-null float64 4 Population 700 non-null float64 5 AveOccup 700 non-null float64 6 Latitude 700 non-null float64 7 Longitude 700 non-null float64 8 PRICE 700 non-null float64 dtypes: float64(9) memory usage: 54.7 KB
Mostrar estadísticas resumidas
print(df_sample.describe())
Producción
MedInc HouseAge AveRooms AveBedrms Population \
count 700.000000 700.000000 700.000000 700.000000 700.000000
mean 3.937653 28.855714 5.404192 1.079266 1387.422857
std 2.085831 12.353313 1.848898 0.236318 1027.873659
min 0.852700 2.000000 2.096692 0.500000 8.000000
25% 2.576350 18.000000 4.397751 1.005934 781.000000
50% 3.480000 30.000000 5.145295 1.047086 1159.500000
75% 4.794625 37.000000 6.098061 1.098656 1666.500000
max 15.000100 52.000000 36.075472 5.273585 8652.000000
AveOccup Latitude Longitude PRICE
count 700.000000 700.000000 700.000000 700.000000
mean 2.939913 35.498243 -119.439729 2.082073
std 0.745525 2.123689 1.956998 1.157855
min 1.312994 32.590000 -124.150000 0.458000
25% 2.457560 33.930000 -121.497500 1.218500
50% 2.834524 34.190000 -118.420000 1.799000
75% 3.326869 37.592500 -118.007500 2.665500
max 7.200000 41.790000 -114.590000 5.000010
6. Dividir el conjunto de datos en conjuntos de entrenamiento y de prueba
Separaremos el conjunto de datos en características (X) y la variable objetivo (y) y luego lo dividiremos en conjuntos de entrenamiento y prueba para el entrenamiento y evaluación del modelo.
# Splitting the dataset into Train and Test sets
X = df_sample.drop('PRICE', axis=1) # Features
y = df_sample['PRICE'] # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
7. Entrenamiento modelo
En esta sección, crearemos y entrenaremos un modelo de regresión lineal utilizando los datos de entrenamiento para conocer la relación entre las características y los precios de la vivienda.
# Creating and training the Linear Regression model lr = LinearRegression() lr.fit(X_train, y_train)
8. Evaluación del modelo
Haremos predicciones en el conjunto de prueba y calcularemos el error cuadrático medio (MSE) y los valores de R cuadrado para evaluar el rendimiento del modelo.
# Making predictions on the test set
y_pred = lr.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
print(f"\nLinear Regression Mean Squared Error: {mse}")
Producción
Linear Regression Mean Squared Error: 0.3699851092128846
9. Visualización de valores reales frente a valores previstos
Aquí, crearemos un DataFrame para comparar los precios reales de la vivienda con los precios previstos generados por nuestro modelo.
# Displaying Actual vs Predicted Values
results = pd.DataFrame({'Actual Prices': y_test.values, 'Predicted Prices': y_pred})
print("\nActual vs Predicted:")
print(results)
Producción
Actual vs Predicted:
Actual Prices Predicted Prices
0 0.87500 0.887202
1 1.19400 2.445412
2 5.00001 6.249122
3 2.78700 2.743305
4 1.99300 2.794774
.. ... ...
135 1.62100 2.246041
136 3.52500 2.626354
137 1.91700 1.899090
138 2.27900 2.731436
139 1.73400 2.017134
[140 rows x
2 columns]
10. Visualizando los resultados
En la sección final, visualizaremos la relación entre los precios reales y previstos de la vivienda utilizando un diagrama de dispersión para evaluar visualmente el rendimiento del modelo.
# Visualizing the Results
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue')
plt.xlabel('Actual Prices')
plt.ylabel('Predicted Prices')
plt.title('Actual vs Predicted House Prices')
# Draw the ideal line
plt.plot([0, 6], [0, 6], color='red', linestyle='--')
# Set limits to minimize empty space
plt.xlim(y_test.min() - 1, y_test.max() 1)
plt.ylim(y_test.min() - 1, y_test.max() 1)
plt.grid()
plt.show()
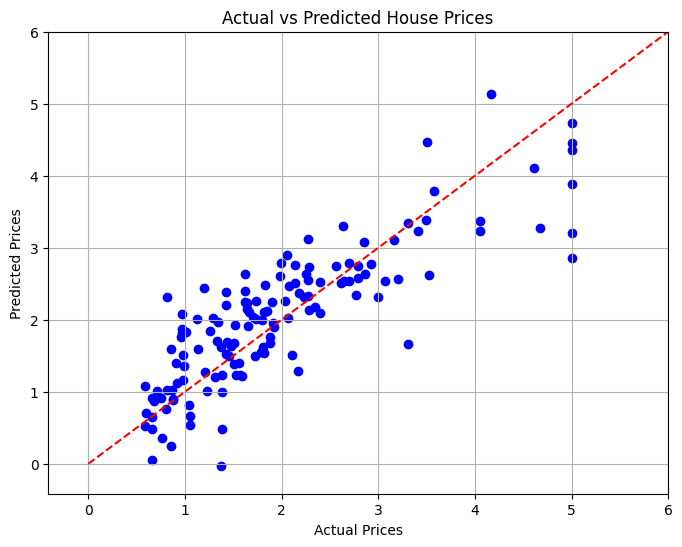
Conclusión
En este proyecto, desarrollamos un modelo de regresión lineal para predecir los precios de la vivienda en California en función de varias características. Se calculó el error cuadrático medio para evaluar el rendimiento del modelo, lo que proporcionó una medida cuantitativa de la precisión de la predicción. A través de la visualización, pudimos ver qué tan bien se desempeñó nuestro modelo en comparación con los valores reales.
Este proyecto demuestra el poder del aprendizaje automático en el análisis inmobiliario y puede servir como base para técnicas de modelado predictivo más avanzadas.
-
 ¿Por qué no aparece mi imagen de fondo CSS?Solución de problemas: css La imagen de fondo que no aparece ha encontrado un problema en el que su imagen de fondo no se carga a pesar de las...Programación Publicado el 2025-04-05
¿Por qué no aparece mi imagen de fondo CSS?Solución de problemas: css La imagen de fondo que no aparece ha encontrado un problema en el que su imagen de fondo no se carga a pesar de las...Programación Publicado el 2025-04-05 -
¿Cómo puedo manejar los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP?manejando los nombres de archivo UTF-8 en las funciones del sistema de archivos de PHP al crear carpetas que contienen caracteres UTF-8 utiliz...Programación Publicado el 2025-04-05
-
¿Cómo se extraen un elemento aleatorio de una matriz en PHP?Selección aleatoria de una matriz en php, la obtención de un elemento aleatorio de una matriz se puede lograr con facilidad. Considere la siguie...Programación Publicado el 2025-04-05
-
¿Cómo puedo unir tablas de bases de datos con diferentes números de columnas?tablas combinadas con diferentes columnas ]] puede encontrar desafíos al intentar fusionar las tablas de la base de datos con diferentes column...Programación Publicado el 2025-04-05
-
¿Cómo puedo ejecutar los comandos del aviso del sistema, incluidos los cambios en el directorio, en Java?Ejecutar comandos del aviso del sistema en java problema: en ejecución de los comandos del aviso a través de java puede ser desafiante. Au...Programación Publicado el 2025-04-05
-
¿Cómo puedo personalizar las optimizaciones de compilación en el compilador GO?Personalización de optimizaciones de compilación En compilador GO El proceso de compilación predeterminado en Go sigue una estrategia de optim...Programación Publicado el 2025-04-05
-
¿Cómo corregir \ "mysql_config no encontrado \" error al instalar mysql-python en Ubuntu/Linux?mysql-python Error de instalación: "mysql_config no encontrado" intentando instalar mysql-python en ubuntu/linux box puede encontrar...Programación Publicado el 2025-04-05
-
¿Cómo resolver el error \ "Uso no válido de la función de grupo \" en MySQL al encontrar el recuento máximo?cómo recuperar el recuento máximo usando mysql en mysql, puede que pueda un problema al intentar encontrar el recuento máximo de valores agrup...Programación Publicado el 2025-04-05
-
¿Cómo puedo leer eficientemente un archivo grande en orden inverso usando Python?leyendo un archivo en orden inverso en python si está trabajando con un archivo grande y necesita leer su contenido desde la última línea hast...Programación Publicado el 2025-04-05
-
¿Cómo convertir una columna Pandas DataFrame a formato de fecha y hora de filtrar por fecha?transformar la columna Pandas DataFrame en formato de Datetime escenario: datos dentro de un marco de datos PANDAS a menudo existe en varios...Programación Publicado el 2025-04-05
-
¿Cómo crear una animación CSS suave de izquierda-derecha para un DIV dentro de su contenedor?animación CSS genérica para el movimiento de derecha izquierda En este artículo, exploraremos la creación de una animación genérica de CSS par...Programación Publicado el 2025-04-05
-
¿Cómo puedo manejar múltiples cargas de archivos con FormData ()?Manejo de múltiples cargas de archivo con formdata () Cuando se trabaja con entradas de archivos, a menudo es necesario manejar múltiples carg...Programación Publicado el 2025-04-05
-
¿Cómo usar correctamente las consultas como los parámetros PDO?usando consultas similares en pdo al intentar implementar una consulta similar en PDO, puede encontrar problemas como el que se describe en la...Programación Publicado el 2025-04-05
-
¿Cómo eliminar los emojis de las cuerdas en Python: una guía para principiantes para solucionar errores comunes?Eliminación de emojis de las cadenas en python el código de python proporcionado para eliminar emojis falla porque contiene errores de sintaxi...Programación Publicado el 2025-04-05
-
¿Cómo puede definir variables en plantillas de cuchilla de laravel elegantemente?Definición de variables en plantillas de Blade Laravel con elegancia Comprender cómo asignar variables en plantillas de cuchillas es crucial p...Programación Publicado el 2025-04-05















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









