 Página delantera > Programación > Creación de una aplicación RAG con LlamaIndex.ts y Azure OpenAI: ¡comenzando!
Página delantera > Programación > Creación de una aplicación RAG con LlamaIndex.ts y Azure OpenAI: ¡comenzando!
Creación de una aplicación RAG con LlamaIndex.ts y Azure OpenAI: ¡comenzando!
 Navegar:854
Navegar:854
A medida que la IA continúa dando forma a la forma en que trabajamos e interactuamos con la tecnología, muchas empresas buscan formas de aprovechar sus propios datos dentro de aplicaciones inteligentes. Si ha utilizado herramientas como ChatGPT o Azure OpenAI, ya está familiarizado con cómo la IA generativa puede mejorar los procesos y mejorar las experiencias de los usuarios. Sin embargo, para obtener respuestas verdaderamente personalizadas y relevantes, sus aplicaciones deben incorporar sus datos de propiedad exclusiva.
Aquí es donde entra en juego la generación aumentada de recuperación (RAG), que proporciona un enfoque estructurado para integrar la recuperación de datos con respuestas impulsadas por IA. Con marcos como LlamaIndex, puede incorporar fácilmente esta capacidad a sus soluciones, liberando todo el potencial de sus datos comerciales.
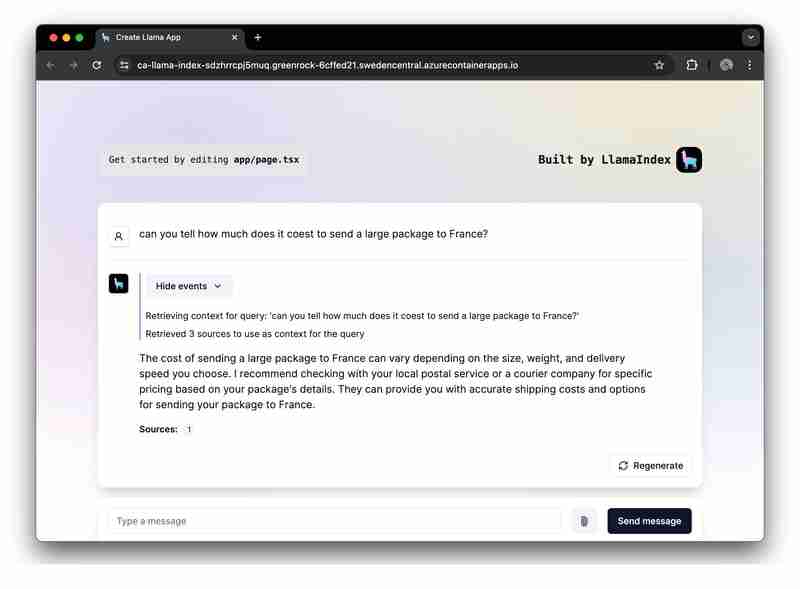
¿Quieres ejecutar y explorar rápidamente la aplicación? Haga clic aquí.
¿Qué es RAG - Generación aumentada de recuperación?
Retrieval-Augmented Generation (RAG) es un marco de red neuronal que mejora la generación de texto de IA al incluir un componente de recuperación para acceder a información relevante e integrar sus propios datos. Consta de dos partes principales:
- Retriever: un modelo de recuperador denso (por ejemplo, basado en BERT) que busca en un gran corpus de documentos para encontrar pasajes relevantes o información relacionada con una consulta determinada.
- Generador: Un modelo de secuencia a secuencia (por ejemplo, basado en BART o T5) que toma la consulta y el texto recuperado como entrada y genera una respuesta coherente y enriquecida contextualmente.
El recuperador encuentra documentos relevantes y el generador los utiliza para crear respuestas más precisas e informativas. Esta combinación permite que el modelo RAG aproveche el conocimiento externo de manera efectiva, mejorando la calidad y relevancia del texto generado.
¿Cómo implementa LlamaIndex RAG?
Para implementar un sistema RAG usando LlamaIndex, sigue estos pasos generales:
Ingestión de datos:
- Cargue sus documentos en LlamaIndex.ts utilizando un cargador de documentos como SimpleDirectoryReader, que ayuda a importar datos de diversas fuentes como PDF, API o bases de datos SQL.
- Divida documentos grandes en partes más pequeñas y manejables usando SentenceSplitter.
Creación de índice:
- Cree un índice vectorial de estos fragmentos de documentos utilizando VectorStoreIndex, lo que permite búsquedas de similitudes eficientes basadas en incrustaciones.
- Opcionalmente, para conjuntos de datos complejos, utilice técnicas de recuperación recursiva para administrar datos estructurados jerárquicamente y recuperar secciones relevantes según las consultas de los usuarios.
Configuración del motor de consultas:
- Convierta el índice vectorial en un motor de consulta usando asQueryEngine con parámetros como similitudTopK para definir cuántos documentos principales se deben recuperar.
- Para configuraciones más avanzadas, cree un sistema de múltiples agentes donde cada agente sea responsable de documentos específicos y un agente de alto nivel coordine el proceso de recuperación general.
Recuperación y Generación:
- Implemente la canalización RAG definiendo una función objetiva que recupere fragmentos de documentos relevantes en función de las consultas de los usuarios.
- Utilice RetrieverQueryEngine para realizar la recuperación real y el procesamiento de consultas, con pasos de posprocesamiento opcionales, como volver a clasificar los documentos recuperados utilizando herramientas como CohereRerank.
Como ejemplo práctico, proporcionamos una aplicación de muestra para demostrar una implementación RAG completa utilizando Azure OpenAI.
Aplicación práctica de muestra de RAG
Ahora nos centraremos en crear una aplicación RAG utilizando LlamaIndex.ts (la implementación TypeScipt de LlamaIndex) y Azure OpenAI, y la implementaremos como aplicaciones web sin servidor en Azure Container Apps.
Requisitos para ejecutar la muestra
- Azure Developer CLI (azd): una herramienta de línea de comandos para implementar fácilmente toda su aplicación, incluidos el backend, el frontend y las bases de datos.
- Cuenta de Azure: Necesitará una cuenta de Azure para implementar la aplicación. Obtenga una cuenta de Azure gratuita con algunos créditos para comenzar.
Encontrarás el proyecto de introducción en GitHub. Te recomendamos bifurcar esta plantilla para que puedas editarla libremente cuando sea necesario:

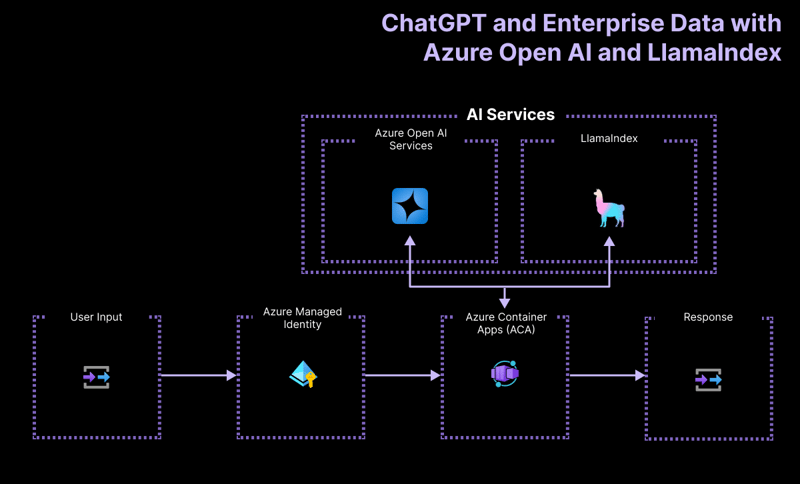
Arquitectura de alto nivel
La aplicación del proyecto de introducción se basa en la siguiente arquitectura:
- Azure OpenAI: el proveedor de IA que procesa las consultas del usuario.
- LlamaIndex.ts: el marco que ayuda a ingerir, transformar y vectorizar contenido (PDF) y crear un índice de búsqueda.
- Azure Container Apps: el entorno de contenedor donde se aloja la aplicación sin servidor.
- Identidad administrada de Azure: garantiza una seguridad de primer nivel y elimina la necesidad de manejar credenciales y claves API.
Para obtener más detalles sobre qué recursos se implementan, consulte la carpeta infra disponible en todos nuestros ejemplos.
Ejemplos de flujos de trabajo de usuario
La aplicación de muestra contiene lógica para dos flujos de trabajo:
-
Ingestión de datos: los datos se recuperan, se vectorizan y se crean índices de búsqueda. Si desea agregar más archivos como PDF o Word, aquí es donde debe agregarlos.
npm run generate
Atendiendo solicitudes de aviso: la aplicación recibe avisos del usuario, los envía a Azure OpenAI y aumenta estos avisos utilizando el índice vectorial como recuperador.
Ejecutando la muestra
Antes de ejecutar la muestra, asegúrese de haber aprovisionado los recursos de Azure necesarios.
Para ejecutar la plantilla de GitHub en GitHub Codespace, simplemente haga clic en
En tu instancia de Codespaces, inicia sesión en tu cuenta de Azure, desde tu terminal:
azd auth login
Aprovisione, empaquete e implemente la aplicación de muestra en Azure mediante un solo comando:
azd up
Para ejecutar y probar la aplicación localmente, instale las dependencias de npm y ejecute la aplicación:
npm install npm run dev
La aplicación se ejecutará en el puerto 3000 de tu instancia de Codespaces o en http://localhost:3000 de tu navegador.
Conclusión
Esta guía demostró cómo crear una aplicación RAG (generación aumentada de recuperación) sin servidor utilizando LlamaIndex.ts y Azure OpenAI, implementada en Microsoft Azure. Si sigue esta guía, podrá aprovechar la infraestructura de Azure y las capacidades de LlamaIndex para crear potentes aplicaciones de IA que brinden respuestas contextualmente enriquecidas basadas en sus datos.
Estamos entusiasmados de ver lo que creas con esta aplicación de introducción. No dudes en bifurcarlo y darle Me gusta al repositorio de GitHub para recibir las últimas actualizaciones y funciones.
-
 Revelando si mysql_real_escape_string puede evitar la inyección de SQLlimitaciones de mysql_real_escape_string mysql_real_escape_string La función en PHP se ha criticado por no proporcionar protección contra la i...Programación Publicado el 2025-04-12
Revelando si mysql_real_escape_string puede evitar la inyección de SQLlimitaciones de mysql_real_escape_string mysql_real_escape_string La función en PHP se ha criticado por no proporcionar protección contra la i...Programación Publicado el 2025-04-12 -
¿Cómo eliminar los emojis de las cuerdas en Python: una guía para principiantes para solucionar errores comunes?Eliminación de emojis de las cadenas en python el código de python proporcionado para eliminar emojis falla porque contiene errores de sintaxi...Programación Publicado el 2025-04-12
-
¿Cómo redirigir múltiples tipos de usuarios (estudiantes, maestros y administradores) a sus respectivas actividades en una aplicación Firebase?rojo: cómo redirigir múltiples tipos de usuarios a las actividades respectivas Comprender el problema en una aplicación de votación basada...Programación Publicado el 2025-04-12
-
¿Puedes usar CSS para la salida de la consola de color en Chrome y Firefox?que muestra los colores en la console JavaScript es posible usar la consola de Chrome para mostrar texto coloreado, como rojo para errores, na...Programación Publicado el 2025-04-12
-
Python crea eficientemente archivos XML: ElementTree, CelementTree o LXML?cómo crear archivos xml en python ]] para crear archivos xml en python, considere las siguientes opciones: elementtree (recomendado) [&] [&] ...Programación Publicado el 2025-04-12
-
¿Cómo puedo personalizar las optimizaciones de compilación en el compilador GO?Personalización de optimizaciones de compilación En compilador GO El proceso de compilación predeterminado en Go sigue una estrategia de optim...Programación Publicado el 2025-04-12
-
¿Java permite múltiples tipos de devolución: una mirada más cercana a los métodos genéricos?múltiples tipos de retorno en java: una concepción errónea indicada en el reino de la programación de java, una firma de método de método pued...Programación Publicado el 2025-04-12
-
¿Cómo puedo unir tablas de bases de datos con diferentes números de columnas?tablas combinadas con diferentes columnas ]] puede encontrar desafíos al intentar fusionar las tablas de la base de datos con diferentes column...Programación Publicado el 2025-04-12
-
¿Cómo puedo iterar e imprimir sincrónicamente los valores de dos matrices de igual tamaño en PHP?iterando e imprimiendo los valores de dos matrices del mismo tamaño cuando se crea un Selectbox usando dos matrices de igual tamaño, uno que con...Programación Publicado el 2025-04-12
-
¿Por qué el DateTime de PHP :: Modify ('+1 mes') produce resultados inesperados?modificando meses con php datetime: descubrir el comportamiento previsto cuando se trabaja con la clase de datetime de PHP, suma o ritir meses...Programación Publicado el 2025-04-12
-
¿Cómo puedo ejecutar los comandos del aviso del sistema, incluidos los cambios en el directorio, en Java?Ejecutar comandos del aviso del sistema en java problema: en ejecución de los comandos del aviso a través de java puede ser desafiante. Au...Programación Publicado el 2025-04-12
-
Python Leer el archivo CSV UnicodeDeCodeError Ultimate Solutionunicode decode error en el archivo csv lectura al intentar leer un archivo csv en python usando el modulo CSV incorporado, (unicodeScal No se ...Programación Publicado el 2025-04-12
-
¿Cómo puedo concatenar de forma segura los textos y los valores al construir consultas SQL en GO?concatenando texto y valores en go sql consultas al construir una consulta sql de texto en go, hay ciertas reglas de sintaxis a seguir cuando ...Programación Publicado el 2025-04-12
-
¿Cómo se extraen un elemento aleatorio de una matriz en PHP?Selección aleatoria de una matriz en php, la obtención de un elemento aleatorio de una matriz se puede lograr con facilidad. Considere la siguie...Programación Publicado el 2025-04-12
-
¿Cómo implementar una función hash genérica para tuplas en colecciones desordenadas?Función hash genérica para tuplas en colecciones no ordenadas los contenedores std :: unordened_map y std :: unordened_set proporcionan una mi...Programación Publicado el 2025-04-12















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









