
¡Crea recomendaciones \"Para ti\" usando IA en Fastly!
 Navegar:870
Navegar:870
Olvídate de las exageraciones; ¿Dónde está aportando valor real la IA? Utilicemos la computación de punta para aprovechar el poder de la IA y crear experiencias de usuario más inteligentes que también sean rápidas, seguras y confiables.
Las recomendaciones están en todas partes y todo el mundo sabe que personalizar las experiencias web las hace más atractivas y exitosas. Mi página de inicio de Amazon sabe que me gustan los muebles para el hogar, los utensilios de cocina y, ahora mismo, la ropa de verano:
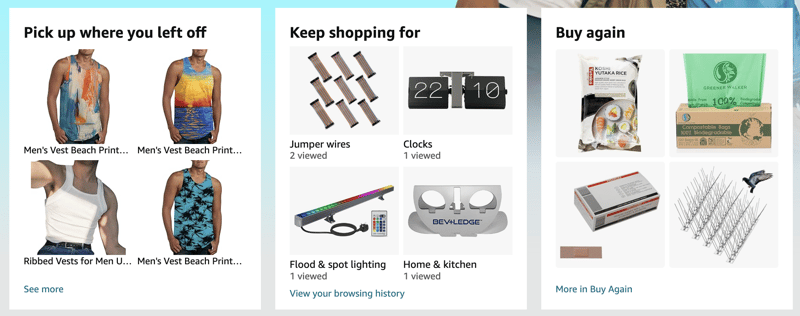
Hoy en día, la mayoría de las plataformas te hacen elegir entre ser rápido o personalizado. En Fastly, creemos que tú (y tus usuarios) merecéis tener ambas cosas. Si cada vez que su servidor web genera una página, solo es adecuada para un usuario final, no podrá beneficiarse del almacenamiento en caché, que es lo que hacen bien las redes perimetrales como Fastly.
Entonces, ¿cómo puedes beneficiarte del almacenamiento en caché perimetral y, al mismo tiempo, personalizar el contenido? Hemos escrito mucho antes sobre cómo dividir solicitudes complejas de clientes en múltiples solicitudes de backend más pequeñas y almacenables en caché, y encontrará tutoriales, ejemplos de código y demostraciones en el tema de personalización en nuestro centro de desarrolladores.
Pero ¿qué pasa si quieres ir más allá y generar los datos de personalización en el borde? El "borde": los servidores de Fastly que gestionan el tráfico de su sitio web, son el punto más cercano al usuario final que todavía está bajo su control. Un excelente lugar para producir contenido específico para un usuario.
El caso de uso "Para ti"
Las recomendaciones de productos son inherentemente transitorias, específicas de un usuario individual y es probable que cambien con frecuencia. Pero tampoco es necesario que persistan: normalmente no necesitamos saber qué le hemos recomendado a cada persona, sólo si un algoritmo en particular logra una mejor conversión que otro. Algunos algoritmos de recomendación necesitan acceso a una gran cantidad de datos estatales, como qué usuarios son más similares a usted y su historial de compras o calificaciones, pero a menudo esos datos son fáciles de pregenerar en masa.
Básicamente, generar recomendaciones generalmente no crea una transacción, no necesita ningún bloqueo en su almacén de datos y utiliza datos de entrada que están disponibles inmediatamente desde la sesión del usuario actual o creados en un proceso de compilación fuera de línea.
¡Parece que podemos generar recomendaciones en el borde!
Un ejemplo del mundo real
Echemos un vistazo al sitio web del Museo de Arte Metropolitano de Nueva York:
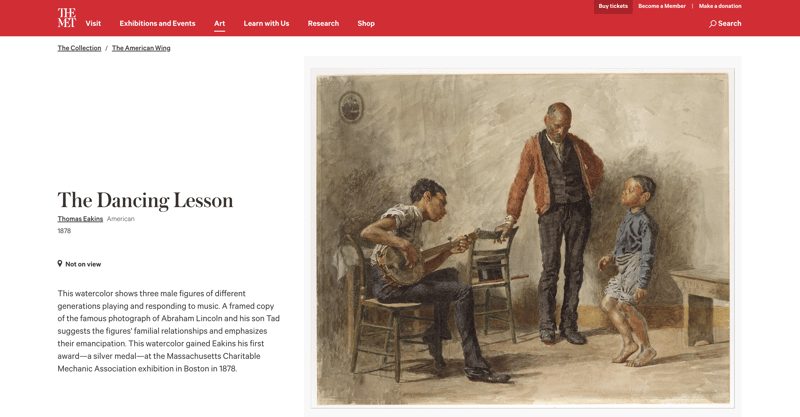
Cada uno de los aproximadamente 500.000 objetos de la colección del Met tiene una página con una imagen e información al respecto. También tiene esta lista de objetos relacionados:
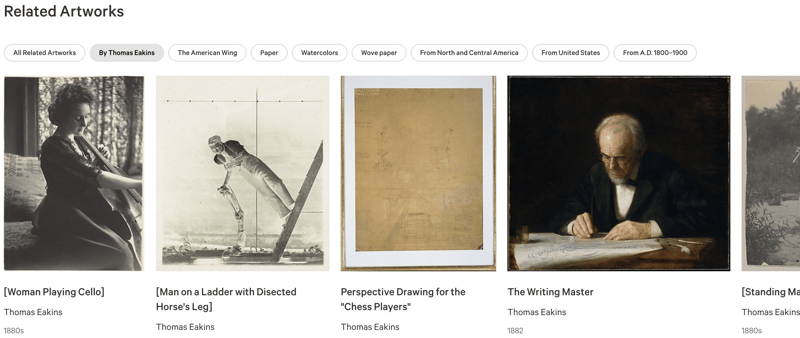
Esto parece utilizar un sistema de facetado bastante sencillo para generar estas relaciones, mostrándome otras obras de arte del mismo artista, u otros objetos en la misma ala del museo, o que también están hechos de papel o se originan en la misma período de tiempo.
Lo bueno de este sistema (¡desde la perspectiva del desarrollador!) es que, dado que solo se basa en un objeto de entrada, se puede generar previamente en la página.
¿Qué pasa si queremos aumentar esto con una selección de recomendaciones que se basan en el historial de navegación personal del usuario final mientras navega por el sitio web del Met, y no solo en este objeto?
Agregar recomendaciones personalizadas
Hay muchas maneras en que podemos hacer esto, pero quería intentar usar un modelo de lenguaje, ya que la IA está sucediendo en este momento, y es realmente diferente de la forma en que parece funcionar el mecanismo existente de obras de arte relacionadas del Met. trabajar. Este es el plan:
- Descargue el conjunto de datos de recopilación de acceso abierto del Met.
- Ejecútelo a través de un modelo de lenguaje para crear incrustaciones de vectores: listas de números adecuados para tareas de aprendizaje automático.
- Crea un motor de búsqueda de similitudes eficaz para el medio millón de vectores resultantes (que representan las obras de arte del Met) y cárgalo en la tienda KV para que podamos usarlo desde Fastly Compute.
Una vez que hayamos hecho todo eso, deberíamos poder, mientras navegas por el sitio web del Met:
- Realiza un seguimiento de las obras de arte que visitas en una cookie.
- Busca los vectores correspondientes a esas obras de arte.
- Calcule un vector promedio que represente sus intereses de navegación.
- Conéctelo a nuestro motor de búsqueda de similitudes para encontrar las obras de arte más similares.
- Carga detalles sobre esas obras de arte desde la API de objetos del Met y aumenta la página con recomendaciones personalizadas.
Et voilà, recomendaciones personalizadas:

Está bien, analicemos eso.
Creando el conjunto de datos
El conjunto de datos sin procesar del Met es un CSV con muchas columnas y se ve así:
Object Number,Is Highlight,Is Timeline Work,Is Public Domain,Object ID,Gallery Number,Department,AccessionYear,Object Name,Title,Culture,Period,Dynasty,Reign,Portfolio,Constituent ID,Artist Role,Artist Prefix,Artist Display Name,Artist Display Bio,Artist Suffix,Artist Alpha Sort,Artist Nationality,Artist Begin Date,Artist End Date,Artist Gender,Artist ULAN URL,Artist Wikidata URL,Object Date,Object Begin Date,Object End Date,Medium,Dimensions,Credit Line,Geography Type,City,State,County,Country,Region,Subregion,Locale,Locus,Excavation,River,Classification,Rights and Reproduction,Link Resource,Object Wikidata URL,Metadata Date,Repository,Tags,Tags AAT URL,Tags Wikidata URL 1979.486.1,False,False,False,1,,The American Wing,1979,Coin,One-dollar Liberty Head Coin,,,,,,16429,Maker," ",James Barton Longacre,"American, Delaware County, Pennsylvania 1794–1869 Philadelphia, Pennsylvania"," ","Longacre, James Barton",American,1794 ,1869 ,,http://vocab.getty.edu/page/ulan/500011409,https://www.wikidata.org/wiki/Q3806459,1853,1853,1853,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1979",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/1,,,"Metropolitan Museum of Art, New York, NY",,, 1980.264.5,False,False,False,2,,The American Wing,1980,Coin,Ten-dollar Liberty Head Coin,,,,,,107,Maker," ",Christian Gobrecht,1785–1844," ","Gobrecht, Christian",American,1785 ,1844 ,,http://vocab.getty.edu/page/ulan/500077295,https://www.wikidata.org/wiki/Q5109648,1901,1901,1901,Gold,Dimensions unavailable,"Gift of Heinz L. Stoppelmann, 1980",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/2,,,"Metropolitan Museum of Art, New York, NY",,,
Lo suficientemente simple como para transformarlo en dos columnas, un ID y una cadena:
id,description 1,"One-dollar Liberty Head Coin; Type: Coin; Artist: James Barton Longacre; Medium: Gold; Date: 1853; Credit: Gift of Heinz L. Stoppelmann, 1979" 2,"Ten-dollar Liberty Head Coin; Type: Coin; Artist: Christian Gobrecht; Medium: Gold; Date: 1901; Credit: Gift of Heinz L. Stoppelmann, 1980" 3,"Two-and-a-Half Dollar Coin; Type: Coin; Medium: Gold; Date: 1927; Credit: Gift of C. Ruxton Love Jr., 1967"
Ahora podemos usar el paquete de transformadores del conjunto de herramientas Hugging Face AI y generar incrustaciones de cada una de estas descripciones. Usamos el modelo de transformadores de oraciones/todo MiniLM-L12-v2 y utilizamos el análisis de componentes principales (PCA) para reducir los vectores resultantes a 5 dimensiones. Eso te da algo como:
[
{
"id": 1,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
{
"id": 2,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
…
]
Tenemos medio millón de estos, por lo que no es posible almacenar este conjunto de datos completo en la memoria de la aplicación perimetral. Y queremos realizar un tipo personalizado de búsqueda de similitud sobre estos datos, que es algo que un almacén de valores-clave tradicional no ofrece. Dado que estamos creando una experiencia en tiempo real, también queremos evitar tener que buscar medio millón de vectores a la vez.
Entonces, particionemos los datos. Podemos utilizar la agrupación de KMeans para agrupar vectores que sean similares entre sí. Dividimos los datos en 500 grupos de diferentes tamaños y calculamos un punto central llamado "vector centroide" para cada uno de esos grupos. Si trazaste este espacio vectorial en dos dimensiones y lo ampliaste, podría verse así:
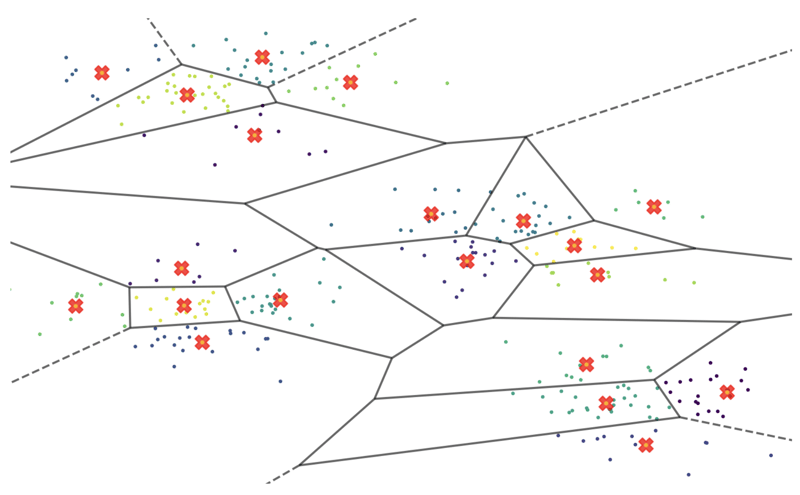
Las cruces rojas son los puntos centrales matemáticos de cada grupo de vectores, llamados centroides. Pueden funcionar como guías para nuestro espacio de medio millón de vectores. Por ejemplo, si queremos encontrar los 10 vectores más similares a un vector A dado, primero podemos buscar el centroide más cercano (entre 500) y luego realizar nuestra búsqueda solo dentro de su grupo correspondiente: ¡un área mucho más manejable!
Ahora tenemos 500 conjuntos de datos pequeños y un índice que asigna puntos centroides al conjunto de datos relevante. A continuación, para permitir el rendimiento en tiempo real, queremos precompilar los gráficos de búsqueda para que no necesitemos inicializarlos y construirlos en tiempo de ejecución, y podamos usar el menor tiempo de CPU posible. Un algoritmo de vecino más cercano realmente rápido es Hierarchical Navigable Small Worlds (HNSW), y tiene una implementación pura de Rust, que estamos usando para escribir nuestra aplicación perimetral. Entonces, escribimos una pequeña aplicación Rust independiente para construir las estructuras gráficas HNSW para cada conjunto de datos, y luego usamos bincode para exportar la memoria de la estructura instanciada a un blob binario.
Ahora, esos blobs binarios se pueden cargar en el almacén KV, codificarlos con el índice del clúster y el índice del clúster se puede incluir en nuestra aplicación perimetral.
Esta arquitectura nos permite cargar partes del índice de búsqueda en la memoria a pedido. Y como nunca tendremos que buscar más de unos pocos miles de vectores a la vez, nuestras búsquedas siempre serán económicas y rápidas.
Construyendo la aplicación perimetral
La aplicación que ejecutamos en el borde necesita manejar varios tipos de solicitudes:
- Páginas HTML: Las obtenemos de metmuseum.org y transformamos la respuesta para agregar etiquetas
- Los recursos de script y estilo de Fastly a los que hacen referencia esas etiquetas adicionales, que podemos ofrecer directamente desde el binario de la aplicación perimetral.
- El punto final del recomendador, que genera y devuelve las recomendaciones ** Todas las demás solicitudes (no HTML): Imágenes y los propios scripts y hojas de estilo del Met, que representamos directamente desde su dominio sin modificaciones.
Inicialmente creamos esta aplicación en JavaScript, pero terminamos portando la parte del recomendador a Rust porque nos gustó la implementación de HNSW en distancia instantánea.
El JavaScript del lado del cliente hace algunas cosas interesantes:
- Al utilizar IntersectionObserver, activamos un evento cuando el usuario se desplaza hacia abajo en la página hasta la sección de objetos relacionados. Esta es una API súper eficiente que es mucho mejor que usar métodos más antiguos como onscroll.
- Realice una búsqueda en nuestro punto final API de recomendaciones especiales (que luego podemos manejar en el borde y devolver información del objeto)
- Componga algo de HTML utilizando una plantilla integrada en una función del lado del cliente
- Agregue ese HTML a la página y mueva el observador de intersección al nuevo elemento para que, a medida que se desplaza por las recomendaciones, sigamos cargando más.
De esta manera, podemos entregar la carga útil HTML principal sin invocar nuestro algoritmo de recomendación, pero las recomendaciones se entregan lo suficientemente rápido como para que podamos cargarlas a medida que se desplaza y es casi seguro que estarán allí cuando llegue a ellas.
Me gusta hacer las cosas de esta manera porque lograr que el usuario tenga esa primera vista en la mitad superior de la página lo más rápido posible es absolutamente primordial. Cualquier cosa que no puedas ver a menos que te desplaces se puede cargar más tarde, y especialmente si se trata de una pieza compleja de contenido personalizado: no tiene sentido generarlo si el usuario no planea desplazarse.
Pensamientos finales
Así que ahora tienes lo mejor de ambos mundos: la capacidad de ofrecer contenido altamente personalizado, que casi nunca requiere ningún bloqueo para recuperar el origen, y una carga útil HTML optimizada que se procesa increíblemente rápido, lo que permite que tu aplicación disfrute de una escalabilidad prácticamente ilimitada y cercana. resiliencia perfecta.
No es una solución perfecta. Sería fantástico si Fastly ofreciera más funciones de nivel superior para exponer datos perimetrales a través de mecanismos de consulta distintos de una simple búsqueda de claves (¡háganos saber si eso le ayudaría!) y este mecanismo específico tiene fallas obvias, si tengo intereses separados en dos o más cosas muy diferentes (por ejemplo, pinturas al óleo del siglo XIX y ánforas romanas antiguas). Recibiría recomendaciones que serían el "punto medio" semántico teórico entre ellas, lo que no es un resultado muy útil.
Aún así, es de esperar que esto demuestre el principio de que descubrir cómo trabajar en el borde a menudo genera enormes beneficios en términos de escalabilidad, rendimiento y resiliencia.
¡Cuéntanos qué creas en community.fastly.com!
-
 ¿Cómo puedo leer eficientemente un archivo grande en orden inverso usando Python?leyendo un archivo en orden inverso en python si está trabajando con un archivo grande y necesita leer su contenido desde la última línea hast...Programación Publicado el 2025-04-30
¿Cómo puedo leer eficientemente un archivo grande en orden inverso usando Python?leyendo un archivo en orden inverso en python si está trabajando con un archivo grande y necesita leer su contenido desde la última línea hast...Programación Publicado el 2025-04-30 -
¿Cómo omitir los bloques de sitios web con las solicitudes de Python y los agentes de usuarios falsos?cómo simular el comportamiento del navegador con las solicitudes de Python y los agentes de usuario falsos La biblioteca de solicitudes de Pyt...Programación Publicado el 2025-04-30
-
¿Por qué no muestra imágenes de Firefox utilizando la propiedad CSS `Content`?Mostrando imágenes con URL de contenido en Firefox Se ha encontrado un problema cuando ciertos navegadores, específicamente Firefox, no muestr...Programación Publicado el 2025-04-30
-
Resolver el error MySQL 1153: el paquete excede el límite 'max_allowed_packet'MySql Error 1153: la solución de problemas obtuvo un paquete más grande que 'max_allowed_packet' bytes frente al error enigmático mysq...Programación Publicado el 2025-04-30
-
Por qué HTML no puede imprimir números y soluciones de páginano puedo imprimir números de página en las páginas html? Descripción del problema: a pesar de investigar extensamente, los números de página ...Programación Publicado el 2025-04-30
-
Python forma eficiente de eliminar las etiquetas HTML del textoeliminando las etiquetas HTML en Python para una representación textual prístina manipular las respuestas HTML a menudo implica extraer conten...Programación Publicado el 2025-04-30
-
¿Cómo resolver el error "No se puede adivinar el tipo de archivo, usar la aplicación/flujo de octet ..." en Appengine?Appengine Static File mime type Override en Appengine, los manejadores de archivos estáticos ocasionalmente pueden exceso del tipo de MIME cor...Programación Publicado el 2025-04-30
-
¿Cómo pasar punteros exclusivos como función o parámetros de constructor en C ++?Gestión de punteros únicos como parámetros en constructores y funciones únicos indicadores ( únicos_ptr ) mantenga el principal de la propiedad ...Programación Publicado el 2025-04-30
-
¿Por qué las expresiones de Lambda requieren variables "finales" o "válidas finales" en Java?Las expresiones lambda requieren variables "finales" o "efectivamente finales" El mensaje de error "variable utilizad...Programación Publicado el 2025-04-30
-
¿Cómo combinar datos de tres tablas MySQL en una nueva tabla?mysql: creando una nueva tabla de datos y columnas de tres tablas pregunta: ¿cómo puedo crear una nueva tabla que combine los datos selecci...Programación Publicado el 2025-04-30
-
La diferencia entre el procesamiento de sobrecarga de la función PHP y C ++PHP Función sobrecarga: desentrañar el enigma desde una perspectiva C como un desarrollador de C experimentado en el ámbito de PHP, puede encont...Programación Publicado el 2025-04-30
-
¿Necesito eliminar explícitamente las asignaciones de montón en C ++ antes de la salida del programa?deleción explícita en c a pesar de la salida del programa cuando trabajan con la asignación de memoria dinámica en c, los desarrolladores a me...Programación Publicado el 2025-04-30
-
¿Por qué no `cuerpo {margen: 0; } `¿Siempre elimina el margen superior en CSS?abordando la eliminación del margen del cuerpo en css para desarrolladores web novatos, eliminar el margen del elemento corporal puede ser una...Programación Publicado el 2025-04-30
-
¿Pueden los parámetros de la plantilla en la función consteval C ++ 20 depender de los parámetros de la función?ConsteVal Functions and Template Parámetros Dependientes de los argumentos de función en C 17, un parámetro de plantilla no puede depender de ...Programación Publicado el 2025-04-30
-
¿Cómo puedo iterar e imprimir sincrónicamente los valores de dos matrices de igual tamaño en PHP?iterando e imprimiendo los valores de dos matrices del mismo tamaño cuando se crea un Selectbox usando dos matrices de igual tamaño, uno que con...Programación Publicado el 2025-04-30















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









