
Conecte AI/ML con su solución de análisis adaptativo
 Navegar:875
Navegar:875
En el panorama de datos actual, las empresas enfrentan una serie de desafíos diferentes. Uno de ellos es realizar análisis sobre una capa de datos unificada y armonizada disponible para todos los consumidores. Una capa que puede ofrecer las mismas respuestas a las mismas preguntas independientemente del dialecto o herramienta que se utilice.
InterSystems IRIS Data Platform responde a esto con un complemento de Adaptive Analytics que puede ofrecer esta capa semántica unificada. Hay muchos artículos en DevCommunity sobre su uso a través de herramientas de BI. Este artículo cubrirá la parte de cómo consumirlo con IA y también cómo recuperar algunos conocimientos.
Vayamos paso a paso...
¿Qué es el Análisis Adaptativo?
Puedes encontrar fácilmente alguna definición en el sitio web de la comunidad de desarrolladores
En pocas palabras, puede entregar datos en forma estructurada y armonizada a varias herramientas de su elección para su posterior consumo y análisis. Ofrece las mismas estructuras de datos a varias herramientas de BI. Pero... ¡también puede ofrecer las mismas estructuras de datos a sus herramientas de IA/ML!
Adaptive Analytics tiene un componente adicional llamado AI-Link que construye este puente entre la IA y la BI.
¿Qué es exactamente AI-Link?
Es un componente de Python que está diseñado para permitir la interacción programática con la capa semántica con el fin de optimizar las etapas clave del flujo de trabajo de aprendizaje automático (ML) (por ejemplo, ingeniería de funciones).
Con AI-Link puedes:
- acceder mediante programación a funciones de su modelo de datos analíticos;
- realizar consultas, explorar dimensiones y medidas;
- alimenta las canalizaciones de ML; ... y devolver los resultados a su capa semántica para que otros los consuman nuevamente (por ejemplo, a través de Tableau o Excel).
Como se trata de una biblioteca de Python, se puede utilizar en cualquier entorno de Python. Incluyendo cuadernos.
Y en este artículo daré un ejemplo sencillo de cómo llegar a la solución Adaptive Analytics de Jupyter Notebook con la ayuda de AI-Link.
Aquí está el repositorio de git que tendrá el Notebook completo como ejemplo: https://github.com/v23ent/aa-hands-on
Requisitos previos
Los pasos adicionales suponen que se han completado los siguientes requisitos previos:
- Solución de Analytics Adaptable en funcionamiento (con IRIS Data Platform como Data Warehouse)
- Jupyter Notebook en funcionamiento
- Se puede establecer conexión entre 1. y 2.
Paso 1: Configuración
Primero, instalemos los componentes necesarios en nuestro entorno. Esto descargará algunos paquetes necesarios para que funcionen los pasos siguientes.
'atscale': este es nuestro paquete principal para conectarnos
'profeta' - paquete que necesitaremos para hacer predicciones
pip install atscale prophet
Luego necesitaremos importar clases clave que representen algunos conceptos clave de nuestra capa semántica.
Cliente - clase que usaremos para establecer una conexión con Adaptive Analytics;
Proyecto: clase para representar proyectos dentro de Adaptive Analytics;
DataModel - clase que representará nuestro cubo virtual;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
Paso 2: Conexión
Ahora deberíamos estar listos para establecer una conexión con nuestra fuente de datos.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Continúe y especifique los detalles de conexión de su instancia de Adaptive Analytics. Una vez que se le solicite la organización, responda en el cuadro de diálogo y luego ingrese su contraseña de la instancia de AtScale.
Con la conexión establecida, deberás seleccionar tu proyecto de la lista de proyectos publicados en el servidor. Obtendrá la lista de proyectos como un mensaje interactivo y la respuesta debe ser el ID entero del proyecto. Y luego el modelo de datos se selecciona automáticamente si es el único.
project = client.select_project() data_model = project.select_data_model()
Paso 3: Explora tu conjunto de datos
Hay varios métodos preparados por AtScale en la biblioteca de componentes AI-Link. Permiten explorar el catálogo de datos que tiene, consultar datos e incluso recuperar algunos datos. La documentación de AtScale tiene una extensa referencia de API que describe todo lo que está disponible.
Primero veamos cuál es nuestro conjunto de datos llamando a algunos métodos de data_model:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
La salida debería verse así
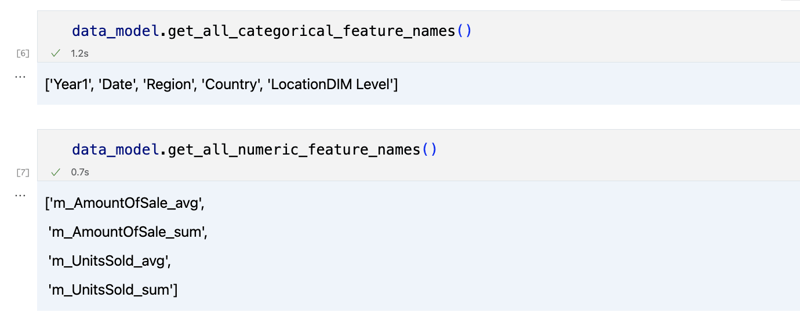
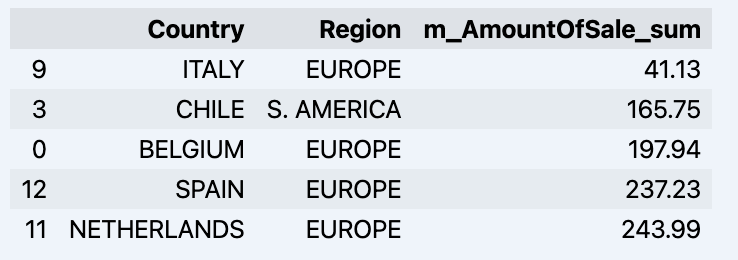
Una vez que hayamos mirado un poco a nuestro alrededor, podemos consultar los datos reales que nos interesan utilizando el método 'get_data'. Devolverá un DataFrame de pandas que contiene los resultados de la consulta.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
Que mostrará tu datadrame:
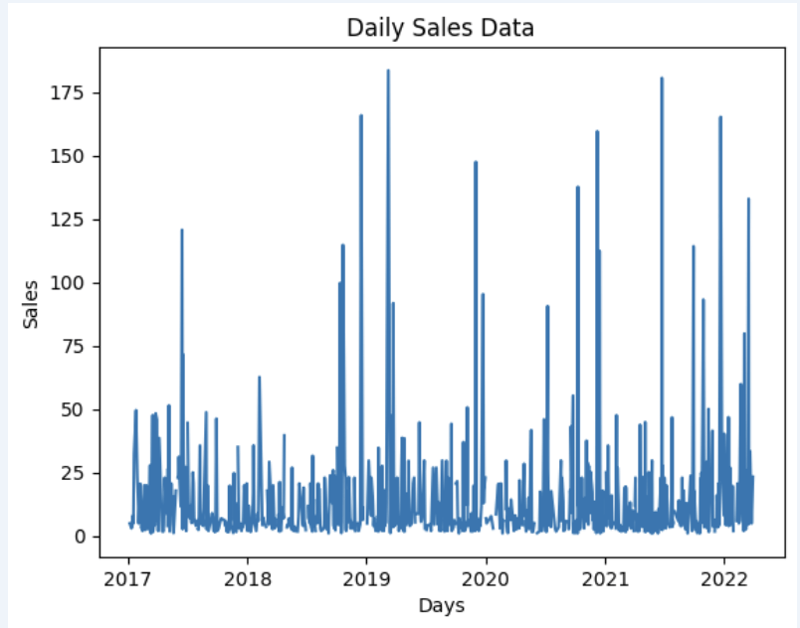
Preparemos un conjunto de datos y mostrémoslo rápidamente en el gráfico
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
Producción:
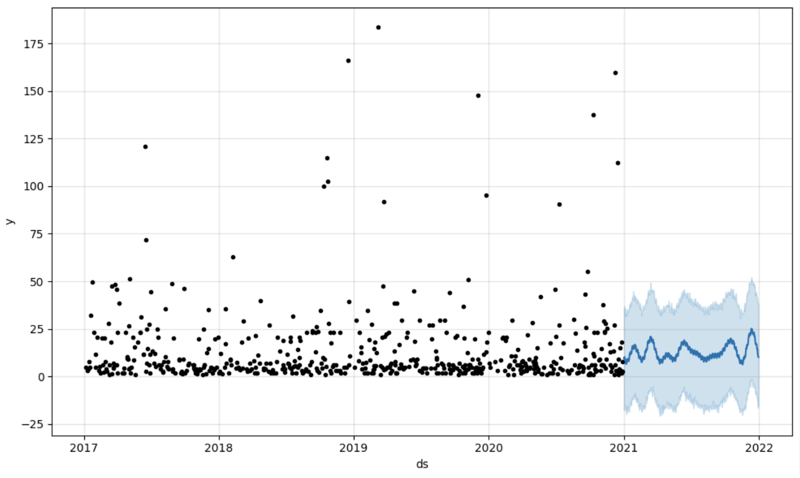
Paso 4: Predicción
El siguiente paso sería obtener algo de valor del puente AI-Link. ¡Hagamos una predicción simple!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Aquí obtenemos 2 conjuntos de datos diferentes: para entrenar nuestro modelo y probarlo.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
Y luego creamos otro marco de datos para acomodar nuestra predicción y mostrarla en el gráfico
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
Producción:
Paso 5: Reescritura
Una vez que tengamos nuestra predicción en su lugar, podemos volver a colocarla en el almacén de datos y agregar un agregado a nuestro modelo semántico para reflejarlo para otros consumidores. La predicción estaría disponible a través de cualquier otra herramienta de BI para analistas de BI y usuarios empresariales.
La predicción en sí se colocará en nuestro almacén de datos y se almacenará allí.
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
Aleta
¡Eso es!
¡Buena suerte con tus predicciones!
-
 ¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-04-27
¿Puedo migrar mi cifrado de MCRYPT a OpenSSL y descifrar datos cifrados de MCRYPT usando OpenSSL?actualizando mi biblioteca de cifrado de MCRYP En OpenSSL, ¿es posible descifrar datos encriptados con MCRYPT? Dos publicaciones diferentes propo...Programación Publicado el 2025-04-27 -
¿Por qué las imágenes todavía tienen fronteras en Chrome? `Border: Ninguno;` Solución inválidaeliminando el borde de la imagen en Chrome un problema frecuente encontrado cuando se trabaja con imágenes en Chrome e IE9 es la apariencia de...Programación Publicado el 2025-04-27
-
La diferencia entre el procesamiento de sobrecarga de la función PHP y C ++PHP Función sobrecarga: desentrañar el enigma desde una perspectiva C como un desarrollador de C experimentado en el ámbito de PHP, puede encont...Programación Publicado el 2025-04-27
-
¿Cómo repetir eficientemente los caracteres de cadena para la sangría en C#?repitiendo una cadena para la indentación al sangrar una cadena basada en la profundidad de un elemento, es conveniente tener una forma eficie...Programación Publicado el 2025-04-27
-
¿Necesito eliminar explícitamente las asignaciones de montón en C ++ antes de la salida del programa?deleción explícita en c a pesar de la salida del programa cuando trabajan con la asignación de memoria dinámica en c, los desarrolladores a me...Programación Publicado el 2025-04-27
-
Fit de objeto: la cubierta falla en IE y Edge, ¿cómo solucionar?Object-Fit: la portada falla en IE y Edge, ¿cómo solucionar? utilizando objeto-fit: cover; en CSS para mantener la altura de imagen consistent...Programación Publicado el 2025-04-27
-
¿Cómo puedo configurar PyTesseract para el reconocimiento de un solo dígito con salida de solo número?pytesSeract OCR con reconocimiento de un solo dígito y restricciones numéricas en el contexto de pytasseract, configurando el tesseract para r...Programación Publicado el 2025-04-27
-
¿Cómo analizar las matrices JSON en ir usando el paquete `JSON`?Parsing Json Matray en Go con el paquete JSON Problema: ¿Cómo puede analizar una cadena JSON que representa una matriz en ir usando el paque...Programación Publicado el 2025-04-27
-
¿Cómo puedo mantener la representación de celda JTable personalizada después de la edición de la celda?manteniendo la representación de la celda JTable después de la edición de celda en una jtable, implementar capacidades de representación y edi...Programación Publicado el 2025-04-27
-
¿Cómo crear una animación CSS suave de izquierda-derecha para un DIV dentro de su contenedor?animación CSS genérica para el movimiento de derecha izquierda En este artículo, exploraremos la creación de una animación genérica de CSS par...Programación Publicado el 2025-04-27
-
Python forma eficiente de eliminar las etiquetas HTML del textoeliminando las etiquetas HTML en Python para una representación textual prístina manipular las respuestas HTML a menudo implica extraer conten...Programación Publicado el 2025-04-27
-
¿Cuándo usar "Prueba" en lugar de "IF" para detectar valores variables en Python?usando "Prueba" vs. "Si" para probar el valor variable en Python en Python, hay situaciones en las que es posible que necesi...Programación Publicado el 2025-04-27
-
¿Por qué las expresiones de Lambda requieren variables "finales" o "válidas finales" en Java?Las expresiones lambda requieren variables "finales" o "efectivamente finales" El mensaje de error "variable utilizad...Programación Publicado el 2025-04-27
-
¿Cómo insertar o actualizar eficientemente filas basadas en dos condiciones en MySQL?solución: La respuesta se encuentra en la sintaxis de la actualización de clave duplicada de MySQL. Esta potente característica permite una mani...Programación Publicado el 2025-04-27
-
¿Cómo evitar presentaciones duplicadas después de la actualización del formulario?evitando las presentaciones duplicadas con el manejo de actualización en el desarrollo web, es común encontrar el problema de los envíos dupli...Programación Publicado el 2025-04-27















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









