 Titelseite > Programmierung > Ich habe mit Streamlit in Snowflake (SiS) eine App zur Überprüfung der Tokenanzahl erstellt.
Titelseite > Programmierung > Ich habe mit Streamlit in Snowflake (SiS) eine App zur Überprüfung der Tokenanzahl erstellt.
Ich habe mit Streamlit in Snowflake (SiS) eine App zur Überprüfung der Tokenanzahl erstellt.
 Durchsuche:133
Durchsuche:133
Einführung
Hallo, ich bin Vertriebsingenieur bei Snowflake. Einige meiner Erfahrungen und Experimente möchte ich in verschiedenen Beiträgen mit Ihnen teilen. In diesem Artikel zeige ich Ihnen, wie Sie mit Streamlit in Snowflake eine App erstellen, um die Anzahl der Token zu überprüfen und die Kosten für Cortex LLM abzuschätzen.
Hinweis: Dieser Beitrag stellt meine persönlichen Ansichten dar und nicht die von Snowflake.
Was ist Streamlit in Snowflake (SiS)?
Streamlit ist eine Python-Bibliothek, die es Ihnen ermöglicht, Web-UIs mit einfachem Python-Code zu erstellen, sodass kein HTML/CSS/JavaScript erforderlich ist. Beispiele finden Sie in der App Gallery.
Streamlit in Snowflake ermöglicht Ihnen die Entwicklung und Ausführung von Streamlit-Webanwendungen direkt auf Snowflake. Es ist einfach mit nur einem Snowflake-Konto zu verwenden und eignet sich hervorragend für die Integration von Snowflake-Tabellendaten in Web-Apps.
Über Streamlit in Snowflake (Offizielle Snowflake-Dokumentation)
Was ist Schneeflocken-Cortex?
Snowflake Cortex ist eine Suite generativer KI-Funktionen in Snowflake. Mit Cortex LLM können Sie mithilfe einfacher Funktionen in SQL oder Python große Sprachmodelle aufrufen, die auf Snowflake ausgeführt werden.
Large Language Model (LLM)-Funktionen (Snowflake Cortex) (Offizielle Snowflake-Dokumentation)
Funktionsübersicht
Bild
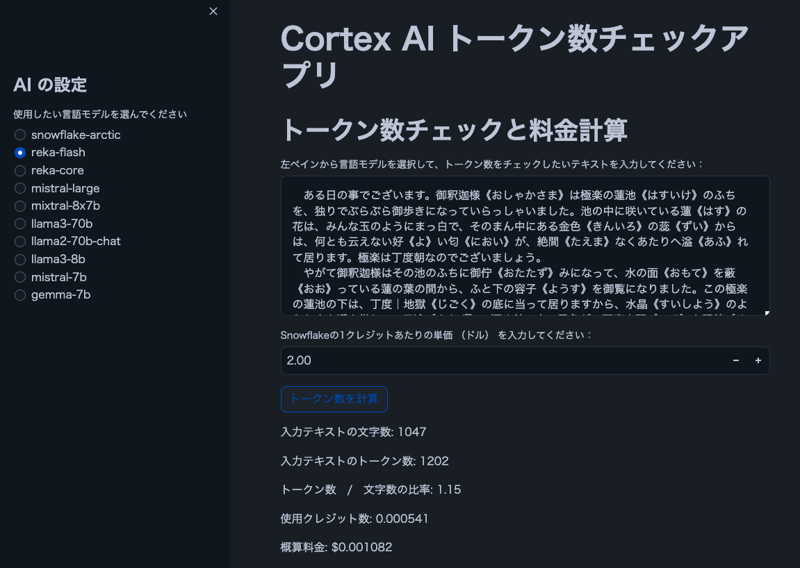
Hinweis: Der Text im Bild stammt aus „The Spider's Thread“ von Ryunosuke Akutagawa.
Merkmale
- Benutzer können ein Cortex-LLM-Modell auswählen
- Zeichen- und Tokenanzahl für vom Benutzer eingegebenen Text anzeigen
- Zeigen Sie das Verhältnis von Token zu Zeichen an
- Berechnen Sie die geschätzten Kosten basierend auf den Snowflake-Guthabenpreisen
Hinweis: Cortex LLM-Preistabelle (PDF)
Voraussetzungen
- Snowflake-Konto mit Cortex LLM-Zugriff
- snowflake-ml-python 1.1.2 oder höher
Hinweis: Verfügbarkeit der Cortex LLM-Region (offizielle Snowflake-Dokumentation)
Quellcode
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
Abschluss
Diese App erleichtert die Schätzung der Kosten für LLM-Workloads, insbesondere beim Umgang mit Sprachen wie Japanisch, bei denen häufig eine Lücke zwischen der Zeichenanzahl und der Tokenanzahl besteht. Ich hoffe, Sie finden es nützlich!
Ankündigungen
Was gibt es Neues bei Snowflake? Updates auf X
Ich teile die Neuigkeiten von Snowflake zu X. Bitte folgen Sie uns, wenn Sie interessiert sind!
Englische Version
Snowflake What's New Bot (englische Version)
https://x.com/snow_new_en
Japanische Version
Snowflake What's New Bot (japanische Version)
https://x.com/snow_new_jp
Änderungsverlauf
(20240914) Erster Beitrag
Originaler japanischer Artikel
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 Jenseits von „if“-Anweisungen: Wo sonst kann ein Typ mit einer expliziten „bool“-Konvertierung ohne Umwandlung verwendet werden?Kontextuelle Konvertierung in bool ohne Umwandlung zulässigIhre Klasse definiert eine explizite Konvertierung in bool, sodass Sie ihre Instanz „t“ dir...Programmierung Veröffentlicht am 29.12.2024
Jenseits von „if“-Anweisungen: Wo sonst kann ein Typ mit einer expliziten „bool“-Konvertierung ohne Umwandlung verwendet werden?Kontextuelle Konvertierung in bool ohne Umwandlung zulässigIhre Klasse definiert eine explizite Konvertierung in bool, sodass Sie ihre Instanz „t“ dir...Programmierung Veröffentlicht am 29.12.2024 -
Was ist mit dem Spaltenversatz in Bootstrap 4 Beta passiert?Bootstrap 4 Beta: Die Entfernung und Wiederherstellung des SpaltenversatzesBootstrap 4 führte in seiner Beta-1-Version wesentliche Änderungen an der A...Programmierung Veröffentlicht am 29.12.2024
-
Wie behebt man „Unsachgemäß konfiguriert: Fehler beim Laden des MySQLdb-Moduls“ in Django unter macOS?MySQL falsch konfiguriert: Das Problem mit relativen PfadenBeim Ausführen von python manage.py runserver in Django kann der folgende Fehler auftreten:...Programmierung Veröffentlicht am 29.12.2024
-
Verwendung von WebSockets in Go für EchtzeitkommunikationDas Erstellen von Apps, die Echtzeitaktualisierungen erfordern – wie Chat-Anwendungen, Live-Benachrichtigungen oder Tools für die Zusammenarbeit – erf...Programmierung Veröffentlicht am 29.12.2024
-
Wie kann ich mit MySQL Benutzer mit den heutigen Geburtstagen finden?So identifizieren Sie Benutzer mit den heutigen Geburtstagen mithilfe von MySQLUm mithilfe von MySQL festzustellen, ob heute der Geburtstag eines Benu...Programmierung Veröffentlicht am 29.12.2024
-
Wie kombiniere ich zwei assoziative Arrays in PHP und behalte dabei eindeutige IDs bei und verarbeite doppelte Namen?Kombinieren assoziativer Arrays in PHPIn PHP ist das Kombinieren zweier assoziativer Arrays zu einem einzigen Array eine häufige Aufgabe. Betrachten S...Programmierung Veröffentlicht am 29.12.2024
-
Wie kann ich Klassenattribute in React bedingt anwenden?Bedingtes Anwenden von Klassenattributen in ReactIn React ist es üblich, Elemente basierend auf Requisiten anzuzeigen oder auszublenden, die von überg...Programmierung Veröffentlicht am 28.12.2024
-
Wie führe ich Systembefehle aus und interagiere mit anderen Anwendungen in Java?Prozesse in Java ausführenIn Java ist die Fähigkeit, Prozesse zu starten, eine entscheidende Funktion für die Ausführung von Systembefehlen und die In...Programmierung Veröffentlicht am 28.12.2024
-
Wie kann ich mehrzeilige String-Literale in C++ erstellen?Mehrzeilige String-Literale in C In C ist die Definition eines mehrzeiligen String-Literals nicht so einfach wie in einigen anderen Sprachen wie Perl....Programmierung Veröffentlicht am 28.12.2024
-
Wie kann ich Daten mit eindeutigen Datensätzen präzise verknüpfen, um den Verlust von Informationen zu vermeiden?Eindeutige Datensätze effektiv pivotierenPivot-Abfragen spielen eine entscheidende Rolle bei der Umwandlung von Daten in ein Tabellenformat und ermögl...Programmierung Veröffentlicht am 27.12.2024
-
Warum ignorieren C und C++ Array-Längen in Funktionssignaturen?Übergabe von Arrays an Funktionen in C und C Frage:Warum tun C und C-Compiler erlauben Array-Längendeklarationen in Funktionssignaturen, z. B. int dis...Programmierung Veröffentlicht am 26.12.2024
-
Wie kann ich Akzente in MySQL entfernen, um die Autovervollständigungssuche zu verbessern?Entfernen von Akzenten in MySQL für eine effiziente AutovervollständigungssucheBei der Verwaltung einer großen Datenbank mit Ortsnamen ist es wichtig,...Programmierung Veröffentlicht am 26.12.2024
-
Wie implementiert man zusammengesetzte Fremdschlüssel in MySQL?Implementieren zusammengesetzter Fremdschlüssel in SQLEin gängiges Datenbankdesign beinhaltet die Herstellung von Beziehungen zwischen Tabellen mithil...Programmierung Veröffentlicht am 26.12.2024
-
Warum sind meine JComponents in Java hinter einem Hintergrundbild versteckt?Debuggen von durch Hintergrundbild verdeckten JComponentsBei der Arbeit mit JComponents wie JLabels in einer Java-Anwendung ist es wichtig, das richti...Programmierung Veröffentlicht am 26.12.2024
-
Wie konvertiert man alle Arten von intelligenten Anführungszeichen in PHP?Konvertieren Sie alle Arten von intelligenten Anführungszeichen in PHPIntelligente Anführungszeichen sind typografische Zeichen, die anstelle normaler...Programmierung Veröffentlicht am 26.12.2024















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









