
Go sync.Pool und die Mechanismen dahinter
 Durchsuche:492
Durchsuche:492
Dies ist ein Auszug aus dem Beitrag; Der vollständige Beitrag ist hier verfügbar: https://victoriametrics.com/blog/go-sync-pool/
Dieser Beitrag ist Teil einer Serie über den Umgang mit Parallelität in Go:
- Go sync.Mutex: Normal- und Hungermodus
- Go sync.WaitGroup und das Ausrichtungsproblem
- Go sync.Pool und die Mechanismen dahinter (Wir sind hier)
- Go sync.Cond, der am meisten übersehene Synchronisierungsmechanismus
Im VictoriaMetrics-Quellcode verwenden wir häufig sync.Pool, und es passt ehrlich gesagt hervorragend zu unserem Umgang mit temporären Objekten, insbesondere Bytepuffern oder Slices.
Es wird häufig in der Standardbibliothek verwendet. Zum Beispiel im Paket „encoding/json“:
package json
var encodeStatePool sync.Pool
// An encodeState encodes JSON into a bytes.Buffer.
type encodeState struct {
bytes.Buffer // accumulated output
ptrLevel uint
ptrSeen map[any]struct{}
}
In diesem Fall wird sync.Pool verwendet, um *encodeState-Objekte wiederzuverwenden, die den Prozess der Codierung von JSON in einen bytes.Buffer übernehmen.
Anstatt diese Objekte nach jeder Verwendung einfach wegzuwerfen, was dem Garbage Collector nur mehr Arbeit machen würde, verstecken wir sie in einem Pool (sync.Pool). Wenn wir das nächste Mal etwas Ähnliches brauchen, nehmen wir es einfach aus dem Pool, anstatt etwas völlig Neues zu machen.
Im Paket net/http finden Sie auch mehrere sync.Pool-Instanzen, die zur Optimierung von E/A-Vorgängen verwendet werden:
package http
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
Wenn der Server Anforderungstexte liest oder Antworten schreibt, kann er schnell einen vorab zugewiesenen Leser oder Schreiber aus diesen Pools abrufen und zusätzliche Zuweisungen überspringen. Darüber hinaus sind die beiden Autorenpools *bufioWriter2kPool und *bufioWriter4kPool so eingerichtet, dass sie unterschiedliche Schreibanforderungen erfüllen.
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2
Okay, das ist genug vom Intro.
Heute befassen wir uns mit dem, worum es bei sync.Pool geht, mit der Definition, wie es verwendet wird, was unter der Haube vor sich geht und mit allem, was Sie sonst noch wissen möchten.
Übrigens, wenn Sie etwas Praktischeres wollen, gibt es einen guten Artikel unserer Go-Experten, der zeigt, wie wir sync.Pool in VictoriaMetrics verwenden: Techniken zur Leistungsoptimierung in Zeitreihendatenbanken: sync.Pool für CPU-gebundene Vorgänge
Was ist sync.Pool?
Um es einfach auszudrücken: sync.Pool in Go ist ein Ort, an dem Sie temporäre Objekte für die spätere Wiederverwendung aufbewahren können.
Aber hier ist die Sache: Sie haben keine Kontrolle darüber, wie viele Objekte im Pool bleiben, und alles, was Sie dort hineinlegen, kann jederzeit und ohne Vorwarnung entfernt werden, und Sie werden wissen, warum, wenn Sie den letzten Abschnitt lesen.
Der gute Punkt ist, dass der Pool threadsicher aufgebaut ist, sodass mehrere Goroutinen gleichzeitig darauf zugreifen können. Keine große Überraschung, wenn man bedenkt, dass es Teil des Synchronisierungspakets ist.
"Aber warum machen wir uns die Mühe, Objekte wiederzuverwenden?"
Wenn viele Goroutinen gleichzeitig ausgeführt werden, benötigen diese häufig ähnliche Objekte. Stellen Sie sich vor, go f() mehrmals gleichzeitig auszuführen.
Wenn jede Goroutine ihre eigenen Objekte erstellt, kann die Speichernutzung schnell ansteigen und dies stellt eine Belastung für den Garbage Collector dar, da er alle diese Objekte bereinigen muss, sobald sie nicht mehr benötigt werden.
Diese Situation erzeugt einen Zyklus, in dem eine hohe Parallelität zu einer hohen Speichernutzung führt, was dann den Garbage Collector verlangsamt. sync.Pool soll dabei helfen, diesen Teufelskreis zu durchbrechen.
type Object struct {
Data []byte
}
var pool sync.Pool = sync.Pool{
New: func() any {
return &Object{
Data: make([]byte, 0, 1024),
}
},
}
Um einen Pool zu erstellen, können Sie eine New()-Funktion bereitstellen, die ein neues Objekt zurückgibt, wenn der Pool leer ist. Diese Funktion ist optional. Wenn Sie sie nicht angeben, gibt der Pool nur Null zurück, wenn er leer ist.
Im obigen Snippet besteht das Ziel darin, die Object-Strukturinstanz wiederzuverwenden, insbesondere den darin enthaltenen Slice.
Die Wiederverwendung des Slice trägt dazu bei, unnötiges Wachstum zu reduzieren.
Wenn das Slice beispielsweise während der Verwendung auf 8192 Bytes anwächst, können Sie seine Länge auf Null zurücksetzen, bevor Sie es wieder in den Pool einfügen. Das zugrunde liegende Array hat immer noch eine Kapazität von 8192. Wenn Sie es also das nächste Mal benötigen, stehen diese 8192 Bytes zur Wiederverwendung bereit.
func (o *Object) Reset() {
o.Data = o.Data[:0]
}
func main() {
testObject := pool.Get().(*Object)
// do something with testObject
testObject.Reset()
pool.Put(testObject)
}
Der Ablauf ist ziemlich klar: Sie holen sich ein Objekt aus dem Pool, verwenden es, setzen es zurück und legen es dann wieder in den Pool ein. Das Zurücksetzen des Objekts kann entweder vor dem Zurücklegen oder direkt nach der Entnahme aus dem Pool erfolgen, ist jedoch nicht zwingend erforderlich, sondern eine gängige Praxis.
Wenn Sie kein Fan der Verwendung von Typzusicherungen pool.Get().(*Object) sind, gibt es mehrere Möglichkeiten, dies zu vermeiden:
- Verwenden Sie eine dedizierte Funktion, um das Objekt aus dem Pool abzurufen:
func getObjectFromPool() *Object {
obj := pool.Get().(*Object)
return obj
}
- Erstellen Sie Ihre eigene generische Version von sync.Pool:
type Pool[T any] struct {
sync.Pool
}
func (p *Pool[T]) Get() T {
return p.Pool.Get().(T)
}
func (p *Pool[T]) Put(x T) {
p.Pool.Put(x)
}
func NewPool[T any](newF func() T) *Pool[T] {
return &Pool[T]{
Pool: sync.Pool{
New: func() interface{} {
return newF()
},
},
}
}
Der generische Wrapper bietet Ihnen eine typsicherere Möglichkeit, mit dem Pool zu arbeiten und Typzusicherungen zu vermeiden.
Beachten Sie bitte, dass aufgrund der zusätzlichen Indirektionsebene ein wenig Mehraufwand entsteht. In den meisten Fällen ist dieser Overhead minimal, aber wenn Sie sich in einer sehr CPU-empfindlichen Umgebung befinden, ist es eine gute Idee, Benchmarks durchzuführen, um zu sehen, ob es sich lohnt.
Aber Moment, es steckt noch mehr dahinter.
sync.Pool und Allocation Trap
Wenn Sie aus vielen früheren Beispielen, einschließlich denen in der Standardbibliothek, bemerkt haben, ist das, was wir im Pool speichern, normalerweise nicht das Objekt selbst, sondern ein Zeiger auf das Objekt.
Lassen Sie mich anhand eines Beispiels erklären, warum:
var pool = sync.Pool{
New: func() any {
return []byte{}
},
}
func main() {
bytes := pool.Get().([]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Wir verwenden einen Pool von []Byte. Wenn Sie einen Wert an eine Schnittstelle übergeben, kann dies im Allgemeinen (wenn auch nicht immer) dazu führen, dass der Wert auf dem Heap platziert wird. Dies geschieht auch hier, nicht nur bei Slices, sondern bei allem, was Sie an pool.Put() übergeben und das kein Zeiger ist.
Wenn Sie die Escape-Analyse verwenden:
// escape analysis $ go build -gcflags=-m bytes escapes to heap
Nun, ich sage nicht, dass unsere variablen Bytes auf den Heap verschoben werden, ich würde sagen: „Der Wert der Bytes entweicht über die Schnittstelle auf den Heap“.
Um wirklich zu verstehen, warum dies geschieht, müssen wir uns mit der Funktionsweise der Escape-Analyse befassen (was wir möglicherweise in einem anderen Artikel tun werden). Wenn wir jedoch einen Zeiger auf pool.Put() übergeben, gibt es keine zusätzliche Zuweisung:
var pool = sync.Pool{
New: func() any {
return new([]byte)
},
}
func main() {
bytes := pool.Get().(*[]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
Führen Sie die Escape-Analyse erneut aus. Sie werden sehen, dass es keine Escapes mehr auf den Heap gibt. Wenn Sie mehr wissen möchten, gibt es ein Beispiel im Go-Quellcode.
sync.Pool-Interna
Bevor wir uns damit befassen, wie sync.Pool tatsächlich funktioniert, lohnt es sich, sich mit den Grundlagen des PMG-Planungsmodells von Go vertraut zu machen. Dies ist wirklich das Rückgrat, warum sync.Pool so effizient ist.
Es gibt einen guten Artikel, der das PMG-Modell mit einigen Bildern aufschlüsselt: PMG-Modelle in Go
Wenn Sie sich heute faul fühlen und nach einer vereinfachten Zusammenfassung suchen, bin ich für Sie da:
PMG steht für P (logische pProzessoren), M (mMaschinen-Threads) und G (gOroutinen). Der entscheidende Punkt ist, dass auf jedem logischen Prozessor (P) jeweils nur ein Maschinenthread (M) laufen kann. Und damit eine Goroutine (G) ausgeführt werden kann, muss sie an einen Thread (M) angehängt werden.
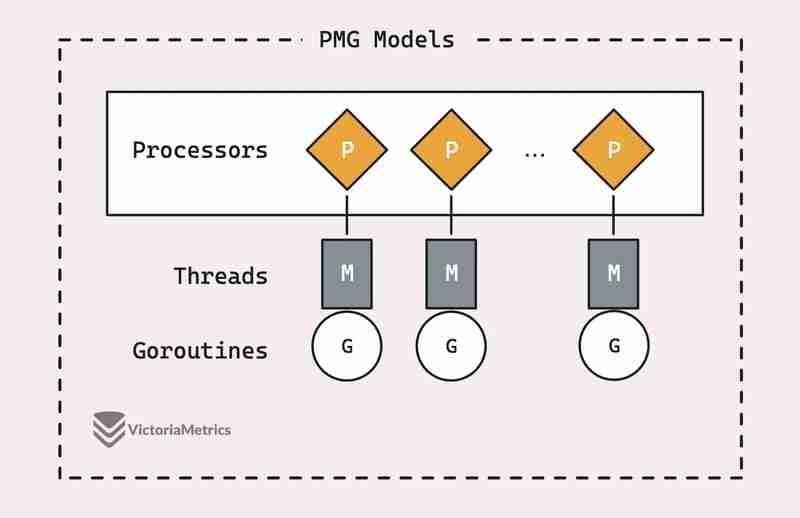
Das lässt sich auf zwei wichtige Punkte reduzieren:
- Wenn Sie über n logische Prozessoren (P) verfügen, können Sie bis zu n Goroutinen parallel ausführen, solange mindestens n Maschinenthreads (M) verfügbar sind.
- Es kann jeweils nur eine Goroutine (G) auf einem einzelnen Prozessor (P) ausgeführt werden. Wenn also ein P1 mit einem G beschäftigt ist, kann kein anderer G auf diesem P1 laufen, bis der aktuelle G entweder blockiert wird, fertig ist oder etwas anderes passiert, das ihn freigibt.
Aber die Sache ist die, ein sync.Pool in Go ist nicht nur ein großer Pool, sondern besteht tatsächlich aus mehreren „lokalen“ Pools, von denen jeder an einen bestimmten Prozessorkontext oder P, also die Laufzeit von Go, gebunden ist jederzeit verwalten.
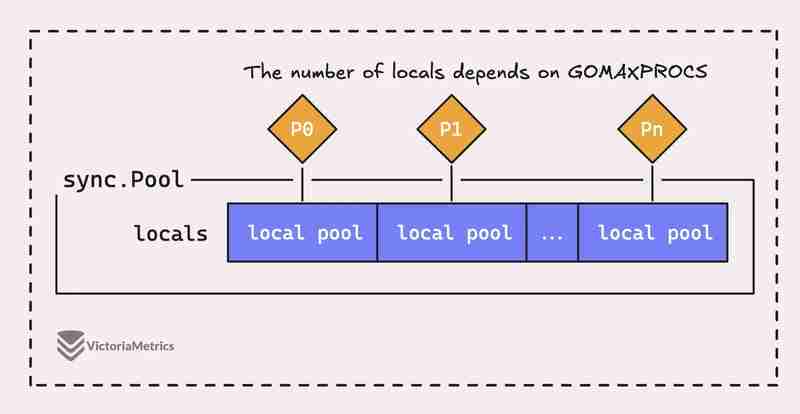
Wenn eine Goroutine, die auf einem Prozessor (P) läuft, ein Objekt aus dem Pool benötigt, überprüft sie zunächst ihren eigenen P-lokalen Pool, bevor sie woanders sucht.
Der vollständige Beitrag ist hier verfügbar: https://victoriametrics.com/blog/go-sync-pool/
-
 Eine neue Art, beim Hacktoberfest mitzuwirken: Direkt bei Frontend AIDas Hacktoberfest ist zurück und dieses Jahr bietet Entwicklern eine aufregende neue Möglichkeit zur Teilnahme. Anstelle der herkömmlichen GitHub-Pull...Programmierung Veröffentlicht am 07.11.2024
Eine neue Art, beim Hacktoberfest mitzuwirken: Direkt bei Frontend AIDas Hacktoberfest ist zurück und dieses Jahr bietet Entwicklern eine aufregende neue Möglichkeit zur Teilnahme. Anstelle der herkömmlichen GitHub-Pull...Programmierung Veröffentlicht am 07.11.2024 -
Warum gibt „cout“ „1“ aus, wenn ein Funktionszeiger ohne Klammern verwendet wird?Warum gibt „eine Funktion aus, ohne sie aufzurufen (nicht f(), sondern f;). Immer 1 drucken?“In diesem Code versucht der Code, eine Funktion namens pr...Programmierung Veröffentlicht am 07.11.2024
-
Machen Sie Ihre Webseite schnellerWas ist ein DOM? Was frisst es? Das DOM (Document Object Model) ist die Basis für Webseiten und deren Entwicklung. Es handelt sich um eine Pr...Programmierung Veröffentlicht am 07.11.2024
-
erfordern Vs-Import in JavaScriptIch erinnere mich, als ich mit dem Codieren begann, sah ich einige JS-Dateien, die require() verwendeten, um Module und andere Dateien mit import zu i...Programmierung Veröffentlicht am 07.11.2024
-
Bereitstellen einer Vite/React-Anwendung mit Bildern: Eine vollständige AnleitungDie Bereitstellung einer Vite/React-Anwendung auf GitHub Pages ist ein aufregender Meilenstein, aber der Prozess kann manchmal mit unerwarteten Heraus...Programmierung Veröffentlicht am 07.11.2024
-
Wie ich API-Aufrufe in meiner React-App optimiert habeAls React-Entwickler sehen wir uns oft mit Szenarien konfrontiert, in denen mehrere schnelle Zustandsänderungen mit einer API synchronisiert werden mü...Programmierung Veröffentlicht am 07.11.2024
-
Lass uns gehen!Warum Sie GO ausprobieren sollten Go ist eine schnelle, leichte und statisch typisierte kompilierte Sprache, die sich perfekt für die Erstell...Programmierung Veröffentlicht am 06.11.2024
-
Wie kodiere ich PNG-Bilder als Base64 für CSS-Daten-URIs?Verwenden der Base64-Codierung für PNG-Bilder in CSS-Daten-URIsUm PNG-Bilder mithilfe von Daten-URIs in CSS-Stylesheets einzubetten, werden die PNG-Da...Programmierung Veröffentlicht am 06.11.2024
-
Responsives JavaScript-Karussell für stündliche API-DatenI almost mistook an incomplete solution for a finished one and moved on to work on other parts of my weather app! While working on the carousel that w...Programmierung Veröffentlicht am 06.11.2024
-
Was sind die Hauptunterschiede zwischen PHP und JavaScript für die Webentwicklung?PHP vs. JavaScript: serverseitig vs. clientseitig PHP erfüllt eine andere Rolle als JavaScript. PHP läuft serverseitig. Der Server führt die ...Programmierung Veröffentlicht am 06.11.2024
-
Wie kann ich Struktur- und Klassenmitglieder in C++ durchlaufen, um zur Laufzeit auf deren Namen und Werte zuzugreifen?Iterieren über Struktur- und KlassenmitgliederIn C ist es möglich, durch die Mitglieder einer Struktur oder Klasse zu iterieren, um deren Namen abzuru...Programmierung Veröffentlicht am 06.11.2024
-
Item Vermeiden Sie Float und Double, wenn genaue Antworten erforderlich sindProblem mit Float und Double: Entwickelt für wissenschaftliche und mathematische Berechnungen, führt binäre Gleitkomma-Arithmetik durch. Nicht geeigne...Programmierung Veröffentlicht am 06.11.2024
-
Verwendung von WebSockets in Go für EchtzeitkommunikationDas Erstellen von Apps, die Echtzeit-Updates erfordern – wie Chat-Anwendungen, Live-Benachrichtigungen oder Tools für die Zusammenarbeit – erfordert e...Programmierung Veröffentlicht am 06.11.2024
-
Wie führe ich Selenium Webdriver mit Proxy in Python aus?Ausführen von Selenium Webdriver mithilfe eines Proxys in PythonWenn Sie versuchen, ein Selenium Webdriver-Skript als Python-Skript zu exportieren und...Programmierung Veröffentlicht am 06.11.2024
-
Wann funktioniert das || Operator als Standardoperator in JavaScript fungieren?Den Zweck des || verstehen Operator mit nicht-booleschen Operanden in JavaScriptIn JavaScript ist das || Der Operator wird oft als logischer ODER-Oper...Programmierung Veröffentlicht am 06.11.2024















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









