 Titelseite > Programmierung > Bildsegmentierung beherrschen: Wie traditionelle Techniken auch im digitalen Zeitalter glänzen
Titelseite > Programmierung > Bildsegmentierung beherrschen: Wie traditionelle Techniken auch im digitalen Zeitalter glänzen
Bildsegmentierung beherrschen: Wie traditionelle Techniken auch im digitalen Zeitalter glänzen
 Durchsuche:343
Durchsuche:343
Einführung
Bildsegmentierung, eines der grundlegendsten Verfahren in der Bildverarbeitung, ermöglicht es einem System, verschiedene Bereiche innerhalb eines Bildes zu zerlegen und zu analysieren. Ob es um Objekterkennung, medizinische Bildgebung oder autonomes Fahren geht, die Segmentierung ist es, die Bilder in sinnvolle Teile zerlegt.
Obwohl Deep-Learning-Modelle bei dieser Aufgabe immer beliebter werden, sind traditionelle Techniken in der digitalen Bildverarbeitung immer noch leistungsstark und praktisch. Zu den in diesem Beitrag besprochenen Ansätzen gehören Schwellenwertbildung, Kantenerkennung, bereichsbasiertes Clustering und die Implementierung eines bekannten Datensatzes für die Analyse von Zellbildern, des MIVIA HEp-2-Bilddatensatzes.
MIVIA HEp-2-Bilddatensatz
Der MIVIA HEp-2-Bilddatensatz besteht aus einer Reihe von Bildern der Zellen, die zur Analyse des Musters antinukleärer Antikörper (ANA) durch HEp-2-Zellen verwendet werden. Es besteht aus 2D-Bildern, die mittels Fluoreszenzmikroskopie aufgenommen wurden. Dadurch eignet es sich sehr gut für Segmentierungsaufgaben, vor allem für medizinische Bildanalysen, bei denen die Erkennung zellulärer Regionen am wichtigsten ist.
Kommen wir nun zu den Segmentierungstechniken, die zur Verarbeitung dieser Bilder verwendet werden, und vergleichen deren Leistung anhand der F1-Ergebnisse.
1. Schwellenwertsegmentierung
Thresholding ist der Prozess, bei dem Graustufenbilder basierend auf Pixelintensitäten in Binärbilder umgewandelt werden. Im MIVIA HEp-2-Datensatz ist dieser Prozess bei der Zellextraktion aus dem Hintergrund nützlich. Es ist relativ einfach und effektiv, insbesondere mit der Otsu-Methode, da sie den optimalen Schwellenwert selbst berechnet.
Otsus Methode ist eine automatische Schwellenwertmethode, bei der versucht wird, den besten Schwellenwert zu finden, um die minimale Varianz innerhalb der Klasse zu erzielen und dadurch die beiden Klassen zu trennen: Vordergrund (Zellen) und Hintergrund. Die Methode untersucht das Bildhistogramm und berechnet den perfekten Schwellenwert, bei dem die Summe der Pixelintensitätsvarianzen in jeder Klasse minimiert wird.
# Thresholding Segmentation
def thresholding(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return thresh
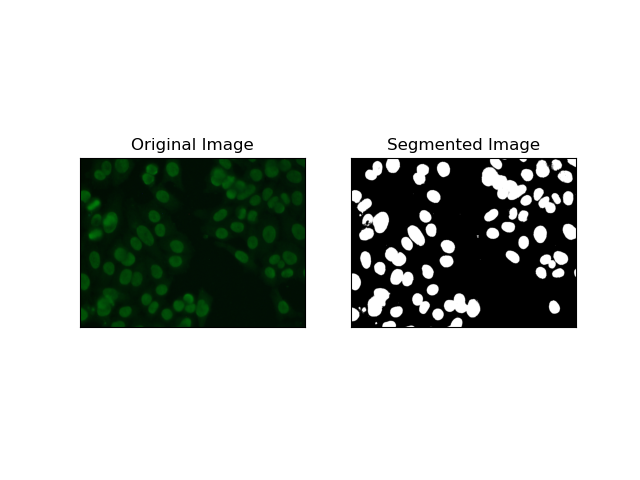
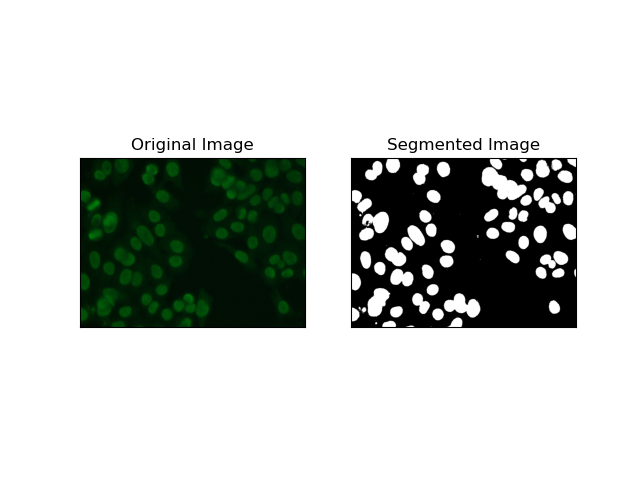
2. Kantenerkennungssegmentierung
Die Kantenerkennung bezieht sich auf die Identifizierung von Grenzen von Objekten oder Regionen, wie z. B. Zellkanten im MIVIA HEp-2-Datensatz. Von den vielen verfügbaren Methoden zur Erkennung abrupter Intensitätsänderungen ist der Canny Edge Detector die beste und daher am besten geeignete Methode zur Erkennung von Zellgrenzen.
Canny Edge Detector ist ein mehrstufiger Algorithmus, der Kanten erkennen kann, indem er Bereiche mit starken Intensitätsgradienten erkennt. Der Prozess umfasst die Glättung mit einem Gaußschen Filter, die Berechnung von Intensitätsgradienten, die Anwendung einer nicht-maximalen Unterdrückung zur Eliminierung von Störreaktionen und eine abschließende doppelte Schwellenwertoperation zur Beibehaltung nur hervorstechender Kanten.
# Edge Detection Segmentation
def edge_detection(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Gaussian blur
gray = cv.GaussianBlur(gray, (3, 3), 0)
# Calculate lower and upper thresholds for Canny edge detection
sigma = 0.33
v = np.median(gray)
lower = int(max(0, (1.0 - sigma) * v))
upper = int(min(255, (1.0 sigma) * v))
# Apply Canny edge detection
edges = cv.Canny(gray, lower, upper)
# Dilate the edges to fill gaps
kernel = np.ones((5, 5), np.uint8)
dilated_edges = cv.dilate(edges, kernel, iterations=2)
# Clean the edges using morphological opening
cleaned_edges = cv.morphologyEx(dilated_edges, cv.MORPH_OPEN, kernel, iterations=1)
# Find connected components and filter out small components
num_labels, labels, stats, _ = cv.connectedComponentsWithStats(
cleaned_edges, connectivity=8
)
min_size = 500
filtered_mask = np.zeros_like(cleaned_edges)
for i in range(1, num_labels):
if stats[i, cv.CC_STAT_AREA] >= min_size:
filtered_mask[labels == i] = 255
# Find contours of the filtered mask
contours, _ = cv.findContours(
filtered_mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE
)
# Create a filled mask using the contours
filled_mask = np.zeros_like(gray)
cv.drawContours(filled_mask, contours, -1, (255), thickness=cv.FILLED)
# Perform morphological closing to fill holes
final_filled_image = cv.morphologyEx(
filled_mask, cv.MORPH_CLOSE, kernel, iterations=2
)
# Dilate the final filled image to smooth the edges
final_filled_image = cv.dilate(final_filled_image, kernel, iterations=1)
return final_filled_image
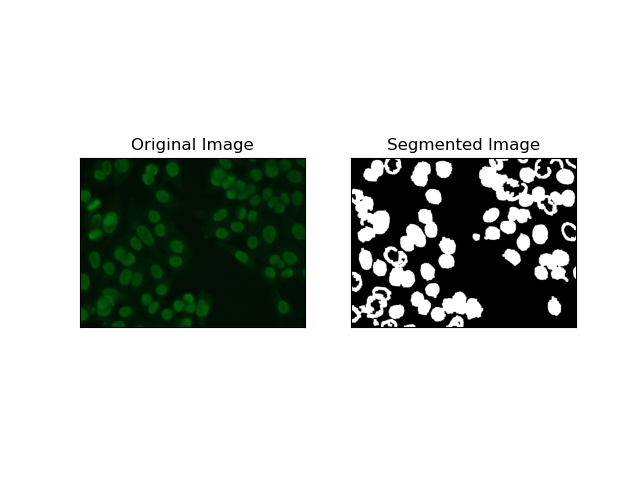
3. Regionsbasierte Segmentierung
Regionsbasierte Segmentierung gruppiert ähnliche Pixel in Regionen, abhängig von bestimmten Kriterien wie Intensität oder Farbe. Die Technik der Watershed-Segmentierung kann zur Segmentierung von HEp-2-Zellbildern verwendet werden, um die Regionen zu erkennen, die Zellen darstellen; Es betrachtet Pixelintensitäten als topografische Oberfläche und umreißt unterscheidende Regionen.
Watershed-Segmentierung behandelt die Intensitäten von Pixeln als topografische Oberfläche. Der Algorithmus identifiziert „Becken“, in denen er lokale Minima identifiziert, und überflutet diese Becken dann schrittweise, um bestimmte Regionen zu vergrößern. Diese Technik ist sehr nützlich, wenn man sich berührende Objekte trennen möchte, etwa im Fall von Zellen in mikroskopischen Bildern, sie kann jedoch rauschempfindlich sein. Der Prozess kann durch Marker gesteuert werden und eine Übersegmentierung kann oft reduziert werden.
# Region-Based Segmentation
def region_based(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
_, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV cv.THRESH_OTSU)
# Apply morphological opening to remove noise
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# Dilate the opening to get the background
sure_bg = cv.dilate(opening, kernel, iterations=3)
# Calculate the distance transform
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
# Threshold the distance transform to get the foreground
_, sure_fg = cv.threshold(dist_transform, 0.2 * dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# Find the unknown region
unknown = cv.subtract(sure_bg, sure_fg)
# Label the markers for watershed algorithm
_, markers = cv.connectedComponents(sure_fg)
markers = markers 1
markers[unknown == 255] = 0
# Apply watershed algorithm
markers = cv.watershed(img, markers)
# Create a mask for the segmented region
mask = np.zeros_like(gray, dtype=np.uint8)
mask[markers == 1] = 255
return mask
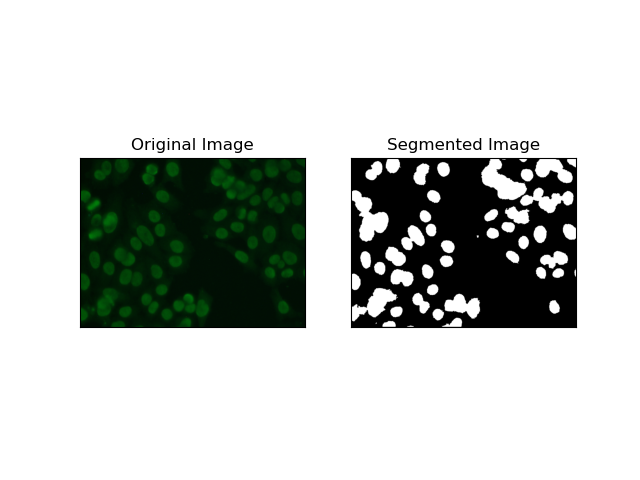
4. Clustering-basierte Segmentierung
Clustering-Techniken wie K-Means neigen dazu, die Pixel in ähnlichen Clustern zu gruppieren, was gut funktioniert, wenn Zellen in mehrfarbigen oder komplexen Umgebungen segmentiert werden sollen, wie in HEp-2-Zellbildern zu sehen ist. Grundsätzlich könnte dies verschiedene Klassen darstellen, beispielsweise eine Zellregion gegenüber einem Hintergrund.
K-means ist ein unbeaufsichtigter Lernalgorithmus zum Clustern von Bildern basierend auf der Pixelähnlichkeit von Farbe oder Intensität. Der Algorithmus wählt zufällig K Schwerpunkte aus, weist jedes Pixel dem nächstgelegenen Schwerpunkt zu und aktualisiert den Schwerpunkt iterativ, bis er konvergiert. Dies ist besonders effektiv bei der Segmentierung eines Bildes, das mehrere interessierende Bereiche aufweist, die sich stark voneinander unterscheiden.
# Clustering Segmentation
def clustering(img):
# Convert image to grayscale
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# Reshape the image
Z = gray.reshape((-1, 3))
Z = np.float32(Z)
# Define the criteria for k-means clustering
criteria = (cv.TERM_CRITERIA_EPS cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set the number of clusters
K = 2
# Perform k-means clustering
_, label, center = cv.kmeans(Z, K, None, criteria, 10, cv.KMEANS_RANDOM_CENTERS)
# Convert the center values to uint8
center = np.uint8(center)
# Reshape the result
res = center[label.flatten()]
res = res.reshape((gray.shape))
# Apply thresholding to the result
_, res = cv.threshold(res, 0, 255, cv.THRESH_BINARY cv.THRESH_OTSU)
return res
Bewertung der Techniken anhand von F1-Scores
Der F1-Score ist ein Maß, das Präzision und Erinnerung kombiniert, um das vorhergesagte Segmentierungsbild mit dem Ground-Truth-Bild zu vergleichen. Es handelt sich um das harmonische Mittel aus Präzision und Erinnerung, das in Fällen hoher Datenunausgewogenheit nützlich ist, beispielsweise bei medizinischen Bilddatensätzen.
Wir haben den F1-Score für jede Segmentierungsmethode berechnet, indem wir sowohl die Grundwahrheit als auch das segmentierte Bild abgeflacht und den gewichteten F1-Score berechnet haben.
def calculate_f1_score(ground_image, segmented_image):
ground_image = ground_image.flatten()
segmented_image = segmented_image.flatten()
return f1_score(ground_image, segmented_image, average="weighted")
Wir haben dann die F1-Ergebnisse verschiedener Methoden mithilfe eines einfachen Balkendiagramms visualisiert:
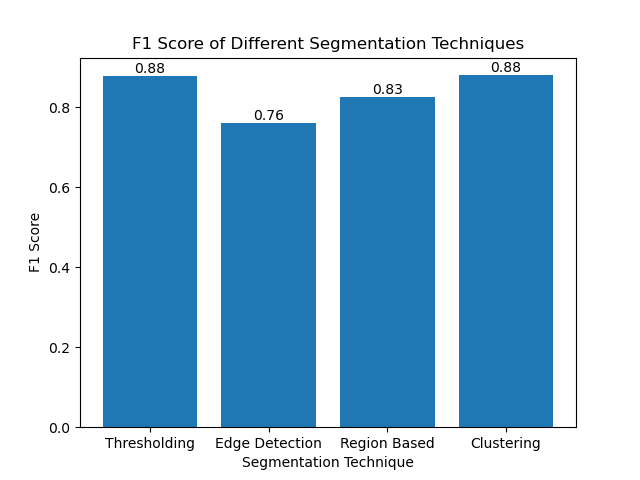
Abschluss
Obwohl viele neuere Ansätze zur Bildsegmentierung im Entstehen sind, können traditionelle Segmentierungstechniken wie Schwellenwertbildung, Kantenerkennung, bereichsbasierte Methoden und Clustering sehr nützlich sein, wenn sie auf Datensätze wie den MIVIA HEp-2-Bilddatensatz angewendet werden.
Jede Methode hat ihre Stärke:
- Schwellenwert eignet sich für eine einfache binäre Segmentierung.
- Kantenerkennung ist eine ideale Technik zur Erkennung von Grenzen.
- Regionsbasierte Segmentierung ist sehr nützlich, um verbundene Komponenten von ihren Nachbarn zu trennen.
- Clustering-Methoden eignen sich gut für Segmentierungsaufgaben in mehreren Regionen.
Durch die Bewertung dieser Methoden anhand von F1-Scores verstehen wir die Kompromisse, die jedes dieser Modelle hat. Diese Methoden sind vielleicht nicht so ausgefeilt wie die, die in den neuesten Deep-Learning-Modellen entwickelt werden, aber sie sind dennoch schnell, interpretierbar und in einem breiten Anwendungsspektrum einsetzbar.
Danke fürs Lesen! Ich hoffe, dass diese Erkundung traditioneller Bildsegmentierungstechniken Ihr nächstes Projekt inspiriert. Teilen Sie Ihre Gedanken und Erfahrungen gerne in den Kommentaren unten mit!
-
 Wie kann ich exportpakettypen in Go -Sprache dynamisch entdecken?finden exportierte Pakettypen dynamisch im Gegensatz zu den begrenzten Typ -Erkennungsfunktionen im reflektierenden Paket, in diesem Artikel u...Programmierung Gepostet am 2025-07-13
Wie kann ich exportpakettypen in Go -Sprache dynamisch entdecken?finden exportierte Pakettypen dynamisch im Gegensatz zu den begrenzten Typ -Erkennungsfunktionen im reflektierenden Paket, in diesem Artikel u...Programmierung Gepostet am 2025-07-13 -
Warum kann Microsoft Visual C ++ keine zweiphasige Vorlage-Instanziierung korrekt implementieren?Das Geheimnis von "kaputte" Two-Phase-Vorlage Instantiation in Microsoft visual c Problemanweisung: Benutzer werden häufig besorgt...Programmierung Gepostet am 2025-07-13
-
ArrayMethoden sind fns, die auf Objekte aufgerufen werden können Arrays sind Objekte, daher haben sie auch Methoden in js. Slice (Beginn): Ex...Programmierung Gepostet am 2025-07-13
-
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-07-13
-
Wie kann man Zeitzonen effizient in PHP konvertieren?effiziente Timezone -Konvertierung in php In PHP können TimeZones eine einfache Aufgabe sein. Dieser Leitfaden bietet eine leicht zu implementie...Programmierung Gepostet am 2025-07-13
-
Fastapi benutzerdefinierte 404 -Seiten -Kreationsleitfadenbenutzerdefinierte 404 nicht gefundene Seite mit fastapi um eine benutzerdefinierte Seite zu erstellen. Die entsprechende Methode hängt von Ih...Programmierung Gepostet am 2025-07-13
-
`console.log` zeigt den Grund für die modifizierte Objektwertausnahme anobjekte und console.log: Eine Kuriosität enträtselte Wenn Sie mit Objekten und Console.log arbeiten, können Sie ein merkwürdiges Verhalten auf...Programmierung Gepostet am 2025-07-13
-
Warum HTML keine Seitenzahlen und Lösungen drucken kannkönnen Seitenzahlen auf html pages nicht drucken? Gebraucht: @page { Marge: 10%; @Top-Center { Schriftfamilie: Sans-Serif; Schriftge...Programmierung Gepostet am 2025-07-13
-
Warum bekomme ich in meiner Silverlight Linq -Abfrage einen Fehler "konnte keine Implementierung des Abfragemuster -Fehlers finden?"Abfragemuster -Implementierung Abwesenheit: Auflösung "konnte nicht" fehler In einer Silberlight -Anwendung, ein Versuch, eine Daten...Programmierung Gepostet am 2025-07-13
-
Wie kann ich mehrere Benutzertypen (Schüler, Lehrer und Administratoren) in ihre jeweiligen Aktivitäten in einer Firebase -App umleiten?rot: Wie man mehrere Benutzertypen zu jeweiligen Aktivitäten umleitet Login. Der aktuelle Code verwaltet die Umleitung für zwei Benutzertypen erf...Programmierung Gepostet am 2025-07-13
-
Ursachen und Lösungen für den Ausfall der Gesichtserkennung: Fehler -215Fehlerbehandlung: Auflösen "Fehler: (-215)! Leere () In Funktion DESTECTMULTICALS" In opencv , wenn Sie versuchen, das Erstellen der ...Programmierung Gepostet am 2025-07-13
-
Wie benutze ich wie Abfragen mit PDO -Parametern richtig?verwenden wie Abfragen in pdo beim Versuch, wie Abfragen in PDO zu implementieren, können Sie Probleme wie die in der Abfrage unten beschriebe...Programmierung Gepostet am 2025-07-13
-
Warum haben Bilder noch Grenzen in Chrome? `BORE: Keine;` Ungültige LösungEntfernen des Bildrandes in Chrome Ein häufiges Problem, das bei der Arbeit mit Bildern in Chrome und IE9 das Erscheinen eines anhaltenden dün...Programmierung Gepostet am 2025-07-13
-
Wie zeige ich das aktuelle Datum und die aktuelle Uhrzeit in "DD/MM/JJJJ HH: MM: SS.SS" -Format in Java richtig?wie man aktuelles Datum und Uhrzeit in "dd/mm/yyyy hh: mm: ss.sS" Format In dem vorgesehenen Java -Code, das Problem mit der Ausstel...Programmierung Gepostet am 2025-07-13
-
Tipps zum Auffinden von Elementpositionen in Java Arrayabrufen Elementposition in Java Arrays In der Arrays -Klasse von Java gibt es keine direkte "IndexOf" -Methode, um die Position eine...Programmierung Gepostet am 2025-07-13















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









