
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit ist eine Python-Bibliothek, die es einfach macht, benutzerdefinierte Webanwendungen für maschinelles Lernen und Data-Science-Projekte zu erstellen und zu teilen.
numpy ist eine grundlegende Python-Bibliothek für numerische Berechnungen. Es bietet Unterstützung für große, mehrdimensionale Arrays und Matrizen sowie eine Sammlung mathematischer Funktionen, um diese Arrays effizient zu bearbeiten.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)Eingabewerte werden aus dem von Stremlit erstellten Eingabeformular abgerufen und kategoriale Variablen werden nach denselben Regeln codiert wie bei der Erstellung des Modells. Beachten Sie, dass die Reihenfolge der einzelnen Daten auch mit der Reihenfolge bei der Erstellung des Modells übereinstimmen muss. Wenn die Reihenfolge unterschiedlich ist, tritt beim Ausführen einer Prognose mithilfe des Modells ein Fehler auf.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" ist die Datei, in der das zuvor gespeicherte Modell gespeichert ist. Diese Datei enthält einen trainierten RandomForestClassifier im Binärformat. Wenn Sie diesen Code ausführen, wird das Modell in clf geladen, sodass Sie es für Vorhersagen und Auswertungen neuer Daten verwenden können.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): Verwendet das trainierte Modell, um die Klasse für die neuen codierten Eingabedaten vorherzusagen, und speichert das Ergebnis in der Vorhersage.
clf.predict_proba(input_encoded_df): Berechnet die Wahrscheinlichkeit für jede Klasse und speichert die Ergebnisse in Prediction_proba.
Sie können Ihre entwickelte Anwendung im Internet veröffentlichen, indem Sie auf die Stremlit Community Cloud (https://streamlit.io/cloud) zugreifen und die URL des GitHub-Repositorys angeben.

Kunstwerk von @allison_horst (https://github.com/allisonhorst)
Das Modell wird mithilfe des Palmer Penguins-Datensatzes trainiert, einem weithin anerkannten Datensatz zum Üben von Techniken des maschinellen Lernens. Dieser Datensatz liefert Informationen zu drei Pinguinarten (Adelie, Zügelpinguin und Eselspinguin) aus dem Palmer-Archipel in der Antarktis. Zu den wichtigsten Funktionen gehören:
Dieser Datensatz stammt von Kaggle und kann hier abgerufen werden. Die Vielfalt der Merkmale macht es zu einer hervorragenden Wahl für die Erstellung eines Klassifizierungsmodells und das Verständnis der Bedeutung jedes Merkmals für die Artenvorhersage.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} Titelseite > Programmierung > Bereitstellung eines Modells für maschinelles Lernen als Web-App mit Streamlit
Titelseite > Programmierung > Bereitstellung eines Modells für maschinelles Lernen als Web-App mit Streamlit
 Durchsuche:652
Durchsuche:652
Ein Modell für maschinelles Lernen ist im Wesentlichen eine Reihe von Regeln oder Mechanismen, die verwendet werden, um Vorhersagen zu treffen oder Muster in Daten zu finden. Um es ganz einfach auszudrücken (und ohne Angst vor einer zu starken Vereinfachung): Eine Trendlinie, die mithilfe der Methode der kleinsten Quadrate in Excel berechnet wird, ist ebenfalls ein Modell. In realen Anwendungen verwendete Modelle sind jedoch nicht so einfach – sie beinhalten oft komplexere Gleichungen und Algorithmen, nicht nur einfache Gleichungen.
In diesem Beitrag werde ich damit beginnen, ein sehr einfaches Modell für maschinelles Lernen zu erstellen und es als sehr einfache Web-App zu veröffentlichen, um ein Gefühl für den Prozess zu bekommen.
Hier werde ich mich nur auf den Prozess konzentrieren, nicht auf das ML-Modell selbst. Außerdem werde ich Streamlit und Streamlit Community Cloud verwenden, um Python-Webanwendungen einfach zu veröffentlichen.
Mit scikit-learn, einer beliebten Python-Bibliothek für maschinelles Lernen, können Sie schnell Daten trainieren und mit nur wenigen Codezeilen ein Modell für einfache Aufgaben erstellen. Das Modell kann dann mit joblib als wiederverwendbare Datei gespeichert werden. Dieses gespeicherte Modell kann wie eine normale Python-Bibliothek in eine Webanwendung importiert/geladen werden, sodass die App mithilfe des trainierten Modells Vorhersagen treffen kann!
App-URL: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
Mit dieser App können Sie Vorhersagen untersuchen, die von einem zufälligen Waldmodell erstellt wurden, das auf dem Palmer Penguins-Datensatz trainiert wurde. (Weitere Informationen zu den Trainingsdaten finden Sie am Ende dieses Artikels.)
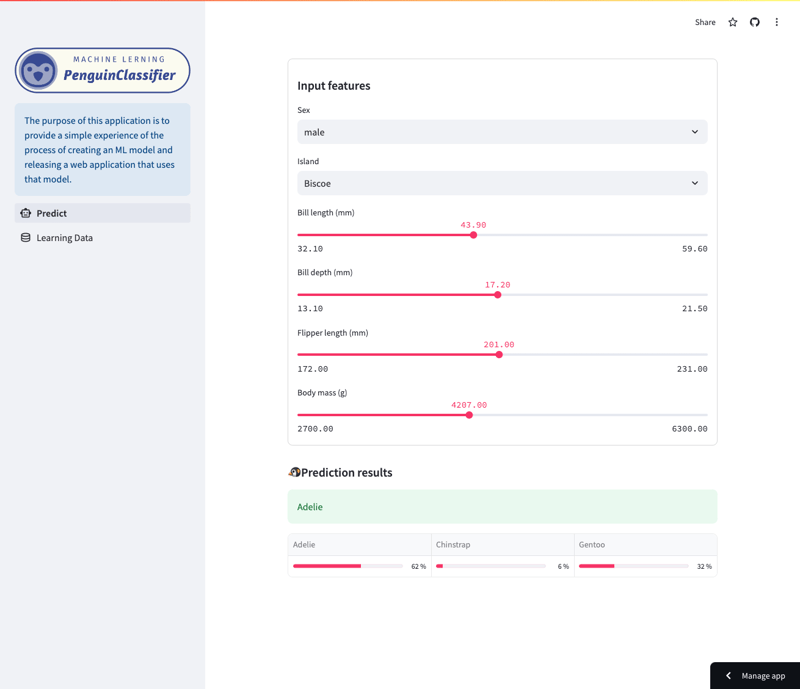
Konkret sagt das Modell Pinguinarten basierend auf einer Vielzahl von Merkmalen voraus, darunter Art, Insel, Schnabellänge, Flossenlänge, Körpergröße und Geschlecht. Benutzer können durch die App navigieren, um zu sehen, wie sich verschiedene Funktionen auf die Vorhersagen des Modells auswirken.
Vorhersagebildschirm
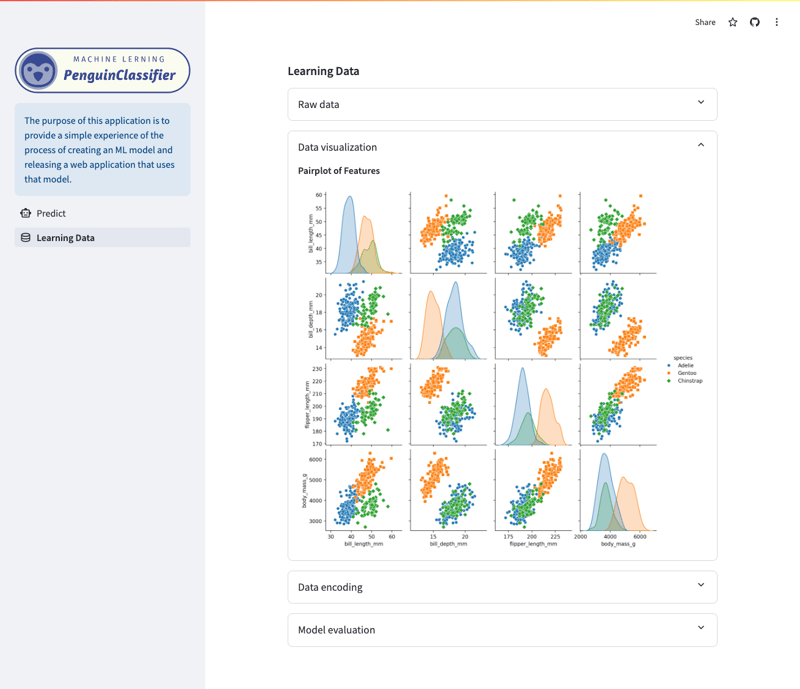
Lerndaten-/Visualisierungsbildschirm
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas ist eine Python-Bibliothek, die auf Datenmanipulation und -analyse spezialisiert ist. Es unterstützt das Laden, Vorverarbeiten und Strukturieren von Daten mithilfe von DataFrames und bereitet Daten für Modelle für maschinelles Lernen vor.
sklearn ist eine umfassende Python-Bibliothek für maschinelles Lernen, die Tools zum Training und zur Bewertung bereitstellt. In diesem Beitrag werde ich ein Modell mithilfe einer Lernmethode namens Random Forest erstellen.
joblib ist eine Python-Bibliothek, die dabei hilft, Python-Objekte, wie z. B. Modelle für maschinelles Lernen, auf sehr effiziente Weise zu speichern und zu laden.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
Laden Sie den Datensatz (Trainingsdaten) und teilen Sie ihn in Features (X) und Zielvariablen (y) auf.
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
Die kategorialen Variablen werden mithilfe der One-Hot-Kodierung (X_encoded) in ein numerisches Format konvertiert. Wenn „Insel“ beispielsweise die Kategorien „Biscoe“, „Dream“ und „Torgersen“ enthält, wird für jede eine neue Spalte erstellt (island_Biscoe, island_Dream, island_Torgersen). Das Gleiche gilt für Sex. Wenn die Originaldaten „Biscoe“ lauten, wird die Spalte island_Biscoe auf 1 und die anderen auf 0 gesetzt.
Die Zielvariablenart wird auf numerische Werte abgebildet (y_encoded).
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
Um ein Modell zu bewerten, ist es notwendig, die Leistung des Modells anhand von Daten zu messen, die nicht für das Training verwendet werden. 7:3 wird häufig als allgemeine Praxis beim maschinellen Lernen verwendet.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
Die Anpassungsmethode wird zum Trainieren des Modells verwendet.
Der x_train repräsentiert die Trainingsdaten für die erklärenden Variablen und der y_train repräsentiert die Zielvariablen.
Durch Aufrufen dieser Methode wird das auf Basis der Trainingsdaten trainierte Modell in clf gespeichert.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() ist eine Funktion zum Speichern von Python-Objekten im Binärformat. Durch das Speichern des Modells in diesem Format kann das Modell aus einer Datei geladen und unverändert verwendet werden, ohne dass es erneut trainiert werden muss.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit ist eine Python-Bibliothek, die es einfach macht, benutzerdefinierte Webanwendungen für maschinelles Lernen und Data-Science-Projekte zu erstellen und zu teilen.
numpy ist eine grundlegende Python-Bibliothek für numerische Berechnungen. Es bietet Unterstützung für große, mehrdimensionale Arrays und Matrizen sowie eine Sammlung mathematischer Funktionen, um diese Arrays effizient zu bearbeiten.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
Eingabewerte werden aus dem von Stremlit erstellten Eingabeformular abgerufen und kategoriale Variablen werden nach denselben Regeln codiert wie bei der Erstellung des Modells. Beachten Sie, dass die Reihenfolge der einzelnen Daten auch mit der Reihenfolge bei der Erstellung des Modells übereinstimmen muss. Wenn die Reihenfolge unterschiedlich ist, tritt beim Ausführen einer Prognose mithilfe des Modells ein Fehler auf.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" ist die Datei, in der das zuvor gespeicherte Modell gespeichert ist. Diese Datei enthält einen trainierten RandomForestClassifier im Binärformat. Wenn Sie diesen Code ausführen, wird das Modell in clf geladen, sodass Sie es für Vorhersagen und Auswertungen neuer Daten verwenden können.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): Verwendet das trainierte Modell, um die Klasse für die neuen codierten Eingabedaten vorherzusagen, und speichert das Ergebnis in der Vorhersage.
clf.predict_proba(input_encoded_df): Berechnet die Wahrscheinlichkeit für jede Klasse und speichert die Ergebnisse in Prediction_proba.
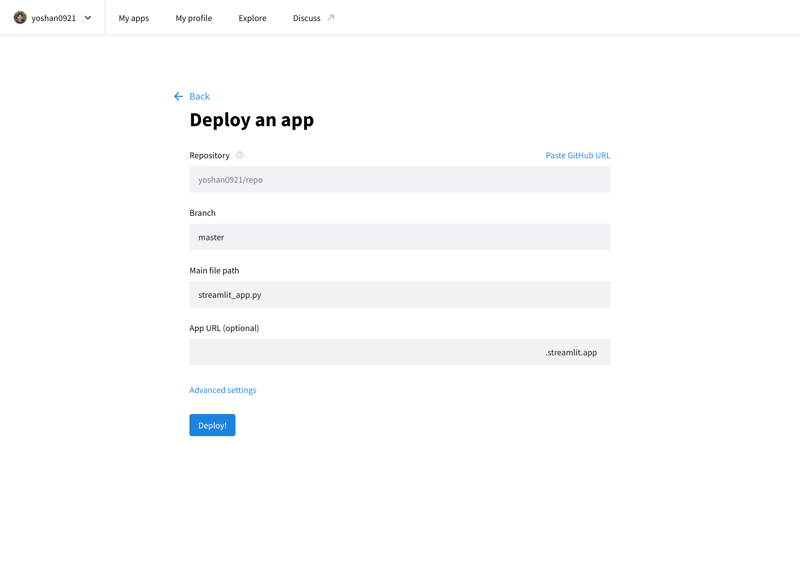
Sie können Ihre entwickelte Anwendung im Internet veröffentlichen, indem Sie auf die Stremlit Community Cloud (https://streamlit.io/cloud) zugreifen und die URL des GitHub-Repositorys angeben.

Kunstwerk von @allison_horst (https://github.com/allisonhorst)
Das Modell wird mithilfe des Palmer Penguins-Datensatzes trainiert, einem weithin anerkannten Datensatz zum Üben von Techniken des maschinellen Lernens. Dieser Datensatz liefert Informationen zu drei Pinguinarten (Adelie, Zügelpinguin und Eselspinguin) aus dem Palmer-Archipel in der Antarktis. Zu den wichtigsten Funktionen gehören:
Dieser Datensatz stammt von Kaggle und kann hier abgerufen werden. Die Vielfalt der Merkmale macht es zu einer hervorragenden Wahl für die Erstellung eines Klassifizierungsmodells und das Verständnis der Bedeutung jedes Merkmals für die Artenvorhersage.

























Haftungsausschluss: Alle bereitgestellten Ressourcen stammen teilweise aus dem Internet. Wenn eine Verletzung Ihres Urheberrechts oder anderer Rechte und Interessen vorliegt, erläutern Sie bitte die detaillierten Gründe und legen Sie einen Nachweis des Urheberrechts oder Ihrer Rechte und Interessen vor und senden Sie ihn dann an die E-Mail-Adresse: [email protected] Wir werden die Angelegenheit so schnell wie möglich für Sie erledigen.
Copyright© 2022 湘ICP备2022001581号-3