 Titelseite > Programmierung > Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel
Titelseite > Programmierung > Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel
Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel
 Durchsuche:238
Durchsuche:238
In diesem Artikel untersuchen wir zwei Methoden zum Entfernen doppelter Elemente aus einem Stapel in Java. Wir vergleichen einen einfachen Ansatz mit verschachtelten Schleifen und eine effizientere Methode mit einem HashSet. Das Ziel besteht darin, zu demonstrieren, wie die Entfernung von Duplikaten optimiert werden kann, und die Leistung jedes Ansatzes zu bewerten.
Problemstellung
Schreiben Sie ein Java-Programm, um das doppelte Element aus dem Stapel zu entfernen.
Eingang
Stackdata = initData(10L);
Ausgabe
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
Um Duplikate aus einem bestimmten Stapel zu entfernen, haben wir zwei Ansätze:
- Naiver Ansatz: Erstellen Sie zwei verschachtelte Schleifen, um zu sehen, welche Elemente bereits vorhanden sind, und um zu verhindern, dass sie zur Ergebnisstapelrückgabe hinzugefügt werden.
- HashSet-Ansatz: Verwenden Sie ein Set, um eindeutige Elemente zu speichern, und nutzen Sie dessen O(1)-Komplexität, um zu überprüfen, ob ein Element vorhanden ist oder nicht.
Zufällige Stapel generieren und klonen
Unten ist dargestellt, wie das Java-Programm zunächst einen zufälligen Stapel erstellt und dann ein Duplikat davon zur weiteren Verwendung erstellt −
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData hilft beim Erstellen eines Stapels mit einer bestimmten Größe und zufälligen Elementen im Bereich von 1 bis 100.
manualCloneStack hilft bei der Datengenerierung durch das Kopieren von Daten aus einem anderen Stapel und verwendet sie für den Leistungsvergleich zwischen den beiden Ideen.
Entfernen Sie Duplikate aus einem bestimmten Stapel mit einem naiven Ansatz
Im Folgenden finden Sie die Schritte zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe des naiven Ansatzes:
- Starten Sie den Timer.
- Erstellen Sie einen leeren Stapel, um eindeutige Elemente zu speichern.
- Iterieren Sie mit der While-Schleife und fahren Sie fort, bis der ursprüngliche Stapel leer ist. Öffnen Sie das oberste Element.
- Suchen Sie mit resultStack.contains(element) nach Duplikaten, um zu sehen, ob sich das Element bereits im Ergebnisstapel befindet.
- Wenn sich das Element nicht im Ergebnisstapel befindet, fügen Sie es dem Ergebnisstapel hinzu.
- Notieren Sie die Endzeit und berechnen Sie die insgesamt aufgewendete Zeit.
- Ergebnis zurückgeben
Beispiel
Unten finden Sie das Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe des naiven Ansatzes −
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
Für den naiven Ansatz verwenden wir
while (!stack.isEmpty())
resultStack.contains(element)
um zu prüfen, ob das Element bereits vorhanden ist.Duplikate aus einem bestimmten Stapel mit optimiertem Ansatz (HashSet) entfernen
Im Folgenden finden Sie die Schritte zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe eines optimierten Ansatzes:
- Timer starten
- Erstellen Sie einen Satz, um gesehene Elemente zu verfolgen (für O(1)-Komplexitätsprüfungen).
- Erstellen Sie einen temporären Stapel zum Speichern eindeutiger Elemente.
- Iterieren Sie mit der while-Schleife und fahren Sie fort, bis der Stapel leer ist.
- Entfernen Sie das oberste Element vom Stapel.
- Um die Duplikate zu überprüfen, verwenden wir seen.contains(element), um zu prüfen, ob das Element bereits im Set vorhanden ist.
- Wenn sich das Element nicht im Satz befindet, fügen Sie es sowohl dem sichtbaren als auch dem temporären Stapel hinzu.
- Notieren Sie die Endzeit und berechnen Sie die insgesamt aufgewendete Zeit.
- Das Ergebnis zurückgeben
Beispiel
Unten finden Sie das Java-Programm zum Entfernen von Duplikaten aus einem bestimmten Stapel mithilfe von HashSet −
public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
Für einen optimierten Ansatz verwenden wir
Set seen Beide Ansätze zusammen nutzen
Im Folgenden finden Sie die Schritte zum Entfernen von Duplikaten aus einem bestimmten Stapel mit beiden oben genannten Ansätzen:
- Daten initialisieren. Wir verwenden die Methode initData(Long size), um einen Stapel mit zufälligen Ganzzahlen zu erstellen.
- Klonen Sie den Stapel, den wir mit der Methode cloneStack(Stack stack) verwenden, um eine exakte Kopie des ursprünglichen Stapels zu erstellen.
- Generieren Sie den ersten Stapel mit initData.
- Klonen Sie diesen Stapel mit cloneStack.
- Wenden Sie den naiven Ansatz an, um Duplikate aus dem Originalstapel zu entfernen.
- Wenden Sie den optimierten Ansatz an, um Duplikate aus dem geklonten Stapel zu entfernen.
- Zeigen Sie die für jede Methode benötigte Zeit und die einzigartigen Elemente an, die durch beide Ansätze erzeugt werden
Beispiel
Unten finden Sie das Java-Programm, das doppelte Elemente aus einem Stapel entfernt, indem es beide oben genannten Ansätze verwendet –
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
}
Ausgabe
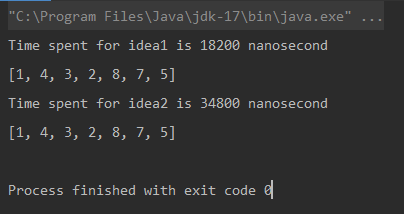
Vergleich
* Die Maßeinheit ist Nanosekunde.
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| Verfahren | 100 Elemente | 1000 Elemente | 10000 Elemente |
100000 Elemente |
1000000 Elemente |
| Idee 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idee 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
Wie beobachtet, ist die Laufzeit für Idee 2 kürzer als für Idee 1, da die Komplexität von Idee 1 O(n²) beträgt, während die Komplexität von Idee 2 O(n) beträgt. Wenn also die Anzahl der Stapel zunimmt, erhöht sich entsprechend auch der Zeitaufwand für Berechnungen.
-
 Wie sende ich eine Roh Postanforderung mit Curl in PHP?Wie sende ich eine rohe Postanfrage mit curl in php in php, curl ist eine beliebte Bibliothek für das Senden von HTTP -Anfragen. In diesem Art...Programmierung Gepostet am 2025-04-15
Wie sende ich eine Roh Postanforderung mit Curl in PHP?Wie sende ich eine rohe Postanfrage mit curl in php in php, curl ist eine beliebte Bibliothek für das Senden von HTTP -Anfragen. In diesem Art...Programmierung Gepostet am 2025-04-15 -
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-04-15
-
Gründe, warum Python keine Fehler beim Schneiden des Hyperscope -Substring meldetsubstring schneiden mit index außerhalb von Bereich: Dualität und leere Sequenzen In Python, Zugriff auf Elemente einer Sequenz mit dem Slicin...Programmierung Gepostet am 2025-04-15
-
So formatieren Sie beim Speichern von VSCODE automatisch Golang -Codeautomatisieren Sie Golang -Code -Formatierung mit vSCode auf Save Wenn Sie sich mit Golang in VSCode entwickeln, können Sie jedes Mal, wenn Än...Programmierung Gepostet am 2025-04-15
-
Wie kann man Zeitzonen effizient in PHP konvertieren?effiziente Timezone -Konvertierung in php In PHP können TimeZones eine einfache Aufgabe sein. Dieser Leitfaden bietet eine leicht zu implementie...Programmierung Gepostet am 2025-04-15
-
Wie füge ich Blobs (Bilder) mithilfe von PHP richtig in MySQL ein?Fügen Sie Blobs in mySQL -Datenbanken mit php beim Versuch, ein Bild in einer MySQL -Datenbank zu speichern, auf eine auf ein Bild zu speiche...Programmierung Gepostet am 2025-04-15
-
Vereinfachen Sie InotifyPropertyChanged: Gibt es eine einfachere Möglichkeit, es manuell zu implementieren?vereinfachen inotifyPropertychanged Implementierung in C# InotifyPropertyChanged ist für die Datenbindung und Eigenschaften von Eigenschaften...Programmierung Gepostet am 2025-04-15
-
Effektive Überprüfungsmethode für Java-Zeichenfolgen, die nicht leer und nicht null sindprüfen, ob ein String nicht null ist und nicht leer , ob ein String nicht null und nicht leer ist, Java bietet verschiedene Methoden. 1.6 and l...Programmierung Gepostet am 2025-04-15
-
Welche Methode ist effizienter für die Erkennung von Punkt-in-Polygon: Strahlenverfolgung oder Matplotlib \ 's path.contains_points?effiziente Punkt-in-Polygon-Erkennung in Python festlegen, ob ein Punkt innerhalb eines Polygons eine häufige Aufgabe in der Computergeometrie i...Programmierung Gepostet am 2025-04-15
-
Wie können Sie Variablen in Laravel Blade -Vorlagen elegant definieren?Variablen in Laravel -Blattvorlagen mit Elegance verstehen, wie man Variablen in Klingenvorlagen zugewiesen ist, ist entscheidend für das Spei...Programmierung Gepostet am 2025-04-15
-
Wie überprüfen Sie, ob eine Spalte in SQLDATAREADER vorhanden ist?Überprüfen Sie die Existenz der Spalte in SQLDATAREADER -Objekten In Datenzugriffsebenen sind häufig Methoden erstellt, die Daten verarbeiten,...Programmierung Gepostet am 2025-04-15
-
Warum kann Microsoft Visual C ++ keine zweiphasige Vorlage-Instanziierung korrekt implementieren?Das Geheimnis von "kaputte" Two-Phase-Vorlage Instantiation in Microsoft visual c Problemanweisung: Benutzer werden häufig besorgt...Programmierung Gepostet am 2025-04-15
-
`console.log` zeigt den Grund für die modifizierte Objektwertausnahme anobjekte und console.log: Eine Kuriosität enträtselte Wenn Sie mit Objekten und Console.log arbeiten, können Sie ein merkwürdiges Verhalten auf...Programmierung Gepostet am 2025-04-15
-
Wie bekomme ich die Benutzerdetails des aktuellen Benutzers in der Spring -Anwendung?public modelAndView SomeRestHandler (@authenticationPrincipal User ActiveUser) { ... } User activeUser = (User)SecurityContextHolder.getC...Programmierung Gepostet am 2025-04-15
-
Wie bestme ich die Visual Studio -Version beim Kompilieren des Codes?wie man die visuelle Studio -Version während der Codekompilation erfasst In der Softwareentwicklung ist es möglicherweise erforderlich, die spez...Programmierung Gepostet am 2025-04-15















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









