 Titelseite > Programmierung > Verwendung der Python-Bibliotheken faker und pandas zum Erstellen synthetischer Daten zum Testen
Titelseite > Programmierung > Verwendung der Python-Bibliotheken faker und pandas zum Erstellen synthetischer Daten zum Testen
Verwendung der Python-Bibliotheken faker und pandas zum Erstellen synthetischer Daten zum Testen
 Durchsuche:326
Durchsuche:326
Einführung:
Umfassende Tests sind für datengesteuerte Anwendungen unerlässlich, erfordern jedoch häufig die Verfügbarkeit der richtigen Datensätze, die möglicherweise nicht immer verfügbar sind. Unabhängig davon, ob Sie Webanwendungen, Modelle für maschinelles Lernen oder Backend-Systeme entwickeln, sind realistische und strukturierte Daten für eine ordnungsgemäße Validierung und die Gewährleistung einer robusten Leistung von entscheidender Bedeutung. Die Erfassung realer Daten kann aufgrund von Datenschutzbedenken, Lizenzbeschränkungen oder einfach der Nichtverfügbarkeit relevanter Daten eingeschränkt sein. Hier werden synthetische Daten wertvoll.
In diesem Blog werden wir untersuchen, wie Python zum Generieren synthetischer Daten für verschiedene Szenarien verwendet werden kann, darunter:
- Zusammenhängende Tabellen: Darstellung von Eins-zu-vielen-Beziehungen.
- Hierarchische Daten: Wird häufig in Organisationsstrukturen verwendet.
- Komplexe Beziehungen: Beispielsweise viele-zu-viele-Beziehungen in Registrierungssystemen.
Wir werden die Faker- und Pandas-Bibliotheken nutzen, um realistische Datensätze für diese Anwendungsfälle zu erstellen.
Beispiel 1: Erstellen synthetischer Daten für Kunden und Bestellungen (Eins-zu-Viele-Beziehung)
In vielen Anwendungen werden Daten in mehreren Tabellen mit Fremdschlüsselbeziehungen gespeichert. Lassen Sie uns synthetische Daten für Kunden und ihre Bestellungen generieren. Ein Kunde kann mehrere Bestellungen aufgeben, was eine Eins-zu-Viele-Beziehung darstellt.
Erstellen der Kundentabelle
Die Kundentabelle enthält grundlegende Informationen wie Kunden-ID, Name und E-Mail-Adresse.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
Dieser Code generiert mithilfe von Faker 10 zufällige Kunden, um realistische Namen und E-Mail-Adressen zu erstellen.
Erstellung der Auftragstabelle
Jetzt generieren wir die Tabelle „Bestellungen“, in der jede Bestellung über die Kunden-ID einem Kunden zugeordnet ist.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
In diesem Fall verknüpft die Tabelle „Bestellungen“ jede Bestellung mithilfe der Kunden-ID mit einem Kunden. Jeder Kunde kann mehrere Bestellungen aufgeben und so eine Eins-zu-Viele-Beziehung aufbauen.
Beispiel 2: Hierarchische Daten für Abteilungen und Mitarbeiter generieren
Hierarchische Daten werden häufig in Organisationsumgebungen verwendet, in denen Abteilungen mehrere Mitarbeiter haben. Lassen Sie uns eine Organisation mit Abteilungen simulieren, von denen jede mehrere Mitarbeiter hat.
Erstellen der Abteilungstabelle
Die Tabelle „Abteilungen“ enthält die eindeutige Abteilungs-ID, den Namen und den Manager jeder Abteilung.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
Erstellen der Mitarbeitertabelle
Als nächstes generieren wir die Mitarbeitertabelle, in der jeder Mitarbeiter über die Abteilungs-ID einer Abteilung zugeordnet ist.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
Diese hierarchische Struktur verknüpft jeden Mitarbeiter über die Abteilungs-ID mit einer Abteilung und bildet so eine Eltern-Kind-Beziehung.
Beispiel 3: Simulieren von Many-to-Many-Beziehungen für Kursanmeldungen
In bestimmten Szenarien bestehen Viele-zu-Viele-Beziehungen, bei denen eine Entität mit vielen anderen in Beziehung steht. Lassen Sie uns dies mit Studenten simulieren, die sich für mehrere Kurse anmelden, wobei jeder Kurs mehrere Studenten hat.
Erstellen der Kurstabelle
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
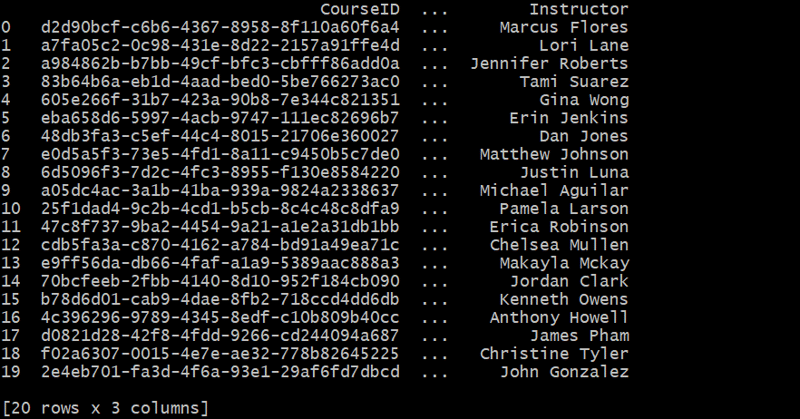
Erstellen der Schülertabelle
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
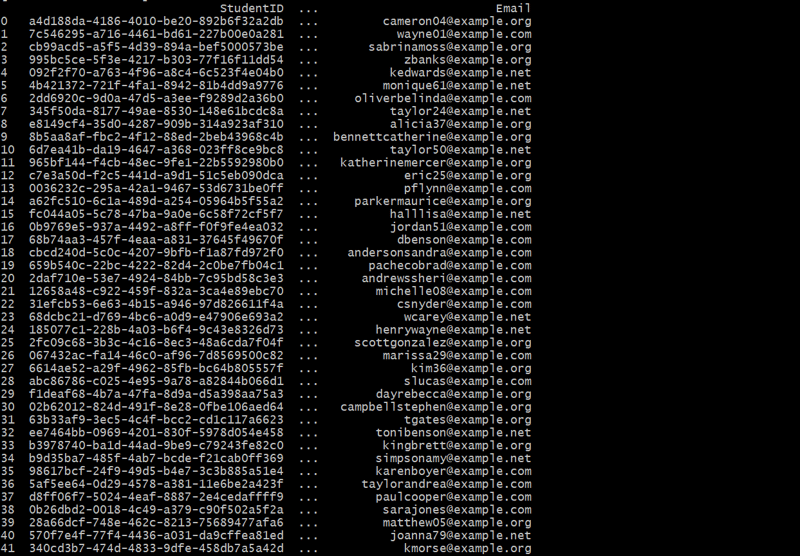
Erstellen der Kursanmeldungstabelle
Die Tabelle „CourseEnrollments“ erfasst die Viele-zu-Viele-Beziehung zwischen Studenten und Kursen.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
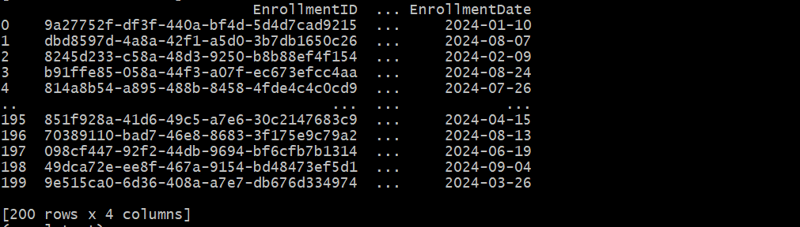
In diesem Beispiel erstellen wir eine Verknüpfungstabelle, um m:n-Beziehungen zwischen Studierenden und Kursen darzustellen.
Abschluss:
Mit Python und Bibliotheken wie Faker und Pandas können Sie realistische und vielfältige synthetische Datensätze generieren, um eine Vielzahl von Testanforderungen zu erfüllen. In diesem Blog haben wir Folgendes behandelt:
- Zusammenhängende Tabellen: Demonstration einer Eins-zu-Viele-Beziehung zwischen Kunden und Bestellungen.
- Hierarchische Daten: Veranschaulichung einer Eltern-Kind-Beziehung zwischen Abteilungen und Mitarbeitern.
- Komplexe Beziehungen: Simulation von Viele-zu-Viele-Beziehungen zwischen Studenten und Kursen.
Diese Beispiele legen den Grundstein für die Generierung synthetischer Daten, die auf Ihre Bedürfnisse zugeschnitten sind. Weitere Verbesserungen, wie das Erstellen komplexerer Beziehungen, das Anpassen von Daten für bestimmte Datenbanken oder das Skalieren von Datensätzen für Leistungstests, können die Generierung synthetischer Daten auf die nächste Stufe heben.
Diese Beispiele bieten eine solide Grundlage für die Generierung synthetischer Daten. Es können jedoch weitere Verbesserungen vorgenommen werden, um die Komplexität und Spezifität zu erhöhen, wie zum Beispiel:
- Datenbankspezifische Daten: Anpassen der Datengenerierung für verschiedene Datenbanksysteme (z. B. SQL vs. NoSQL).
- Komplexere Beziehungen: Erstellen zusätzlicher gegenseitiger Abhängigkeiten, wie z. B. zeitliche Beziehungen, mehrstufige Hierarchien oder eindeutige Einschränkungen.
- Daten skalieren: Generieren größerer Datensätze für Leistungstests oder Stresstests, um sicherzustellen, dass das System reale Bedingungen im großen Maßstab bewältigen kann. Durch die Generierung synthetischer Daten, die auf Ihre Bedürfnisse zugeschnitten sind, können Sie realistische Bedingungen zum Entwickeln, Testen und Optimieren von Anwendungen simulieren, ohne auf sensible oder schwer zu beschaffende Datensätze angewiesen zu sein.
Wenn Ihnen der Artikel gefällt, teilen Sie ihn bitte mit Ihren Freunden und Kollegen. Sie können sich auf LinkedIn mit mir in Verbindung setzen, um weitere Ideen zu besprechen.
-
 Wie setze ich Tasten in JavaScript -Objekten dynamisch ein?wie man einen dynamischen Schlüssel für eine JavaScript -Objektvariable erstellt beim Versuch, einen dynamischen Schlüssel für ein JavaScript -O...Programmierung Gepostet am 2025-04-03
Wie setze ich Tasten in JavaScript -Objekten dynamisch ein?wie man einen dynamischen Schlüssel für eine JavaScript -Objektvariable erstellt beim Versuch, einen dynamischen Schlüssel für ein JavaScript -O...Programmierung Gepostet am 2025-04-03 -
Wie wähle ich Spalten effizient in Pandas -Datenframes aus?Auswählen von Spalten in Pandas datframes beim Umgang mit Datenmanipulationsaufgaben werden bestimmte Spalten erforderlich. In Pandas gibt es ...Programmierung Gepostet am 2025-04-03
-
Warum wird die Anfrage nicht nach dem Erfassen von Eingaben in PHP trotz gültiger Code erfasst?adressieren nach Anfrage Fehlfunktion in php in dem vorgestellten Code -Snippet: action='' Die Intented -In -Intented -Aufnahme. Die Ausg...Programmierung Gepostet am 2025-04-03
-
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-04-03
-
Warum hört die Ausführung von JavaScript ein, wenn die Firefox -Rückbutton verwendet wird?Navigational History Problem: JavaScript hört auf, nach der Verwendung von Firefox -Back -Schaltflächen auszuführen. Dieses Problem tritt in ande...Programmierung Gepostet am 2025-04-03
-
Wie kann ich in Java Eingabeaufforderungsbefehle, einschließlich Verzeichnisänderungen, ausführen?Lösung: , um Eingabeaufforderung und Änderungsverzeichnisse mit Java auszuführen, nutzen A -ProcessBuilder. Dieser Ansatz ermöglicht es Ihnen...Programmierung Gepostet am 2025-04-03
-
Muss ich vor dem Programm Exit explizit Heap -Zuordnungen in C ++ löschen?explizites Löschen in C trotz des Programms exit Wenn Sie mit dynamischer Speicherzuweisung in C arbeiten, fragen sich Entwickler oft, ob es n...Programmierung Gepostet am 2025-04-03
-
Wie zeige ich das aktuelle Datum und die aktuelle Uhrzeit in "DD/MM/JJJJ HH: MM: SS.SS" -Format in Java richtig?wie man aktuelles Datum und Uhrzeit in "dd/mm/yyyy hh: mm: ss.ss" Format in dem vorgesehenen Java -Code, das Problem mit der Anzeige...Programmierung Gepostet am 2025-04-03
-
Warum gibt es Streifen in meinem linearen Gradientenhintergrund und wie kann ich sie beheben?die Hintergrundstreifen aus linearem Gradienten Beim Einsatz der Linear-Gradient-Eigenschaft für einen Hintergrund können Sie auffällige Strei...Programmierung Gepostet am 2025-04-03
-
Können mehrere klebrige Elemente in reinem CSS übereinander gestapelt werden?Ist es möglich, in reinem CSS mehrere klebrige Elemente gestapelt zu haben? Hier: https://webthemez.com/demo/sticky-multi-header-scroll/index.ht...Programmierung Gepostet am 2025-04-03
-
Wie beheben Sie die "ungültige Verwendung der Gruppenfunktion" in MySQL beim Finden der Maximalzahl?wie man die maximale zählende mit mysql in mysql abrufen Wählen Sie max (count (*)) aus der Emp1 -Gruppe nach Namen; ERROR 1111 (HY000): Ungül...Programmierung Gepostet am 2025-04-03
-
Wie kann ich programmgesteuert den gesamten Text in einer DIV auf Mausklick auswählen?programmatisch den Div -Text in Maus auswählen klicken Frage angegeben ein DIV -Element mit Textinhalten, wie kann der Benutzer programmatisch...Programmierung Gepostet am 2025-04-03
-
Warum zeigt keine Firefox -Bilder mithilfe der CSS `Content` -Eigenschaft an?Bilder mit Inhalts -URL in Firefox Es wurde ein Problem aufgenommen, an dem bestimmte Browser, speziell Firefox, nicht die Bilder mit der Inha...Programmierung Gepostet am 2025-04-03
-
Wie kann ich Kompilierungsoptimierungen im Go -Compiler anpassen?Anpassung von Kompilierungsoptimierungen in Go Compiler Der Standardkompilierungsprozess in Go folgt einer spezifischen Optimierungsstrategie....Programmierung Gepostet am 2025-04-03
-
Was waren die Einschränkungen bei der Verwendung von Current_Timestamp mit Zeitstempelspalten in MySQL vor Version 5.6.5?Einschränkungen für Zeitstempelspalten mit Current_Timestamp in Standard- oder Aktualisierungsklauseln in MySQL -Versionen vor 5.6.5 Historisch ...Programmierung Gepostet am 2025-04-03















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









