 Titelseite > Programmierung > Extrahieren von Daten aus schwierigen PDFs mit Google Gemini in Python-Sprache
Titelseite > Programmierung > Extrahieren von Daten aus schwierigen PDFs mit Google Gemini in Python-Sprache
Extrahieren von Daten aus schwierigen PDFs mit Google Gemini in Python-Sprache
 Durchsuche:328
Durchsuche:328
In diesem Leitfaden zeige ich Ihnen, wie Sie mithilfe von Vision-Language-Modellen (VLMs) wie Gemini Flash oder GPT-4o strukturierte Daten aus PDFs extrahieren.
Gemini, Googles neueste Serie von Vision-Language-Modellen, hat modernste Leistung beim Text- und Bildverständnis gezeigt. Diese verbesserte multimodale Fähigkeit und das lange Kontextfenster machen es besonders nützlich für die Verarbeitung visuell komplexer PDF-Daten, mit denen herkömmliche Extraktionsmodelle Schwierigkeiten haben, wie z. B. Abbildungen, Diagramme, Tabellen und Diagramme.
Auf diese Weise können Sie ganz einfach Ihr eigenes Datenextraktionstool für die visuelle Datei- und Webextraktion erstellen. So geht's:
Das lange Kontextfenster und die multimodale Fähigkeit von Gemini machen es besonders nützlich für die Verarbeitung visuell komplexer PDF-Daten, bei denen herkömmliche Extraktionsmodelle Schwierigkeiten haben.
Einrichten Ihrer Umgebung
Bevor wir uns mit der Extraktion befassen, richten wir unsere Entwicklungsumgebung ein. In dieser Anleitung wird davon ausgegangen, dass Sie Python auf Ihrem System installiert haben. Wenn nicht, laden Sie es von https://www.python.org/downloads/
herunter und installieren Sie es.⚠️ Beachten Sie, dass Sie, wenn Sie Python nicht verwenden möchten, die Cloud-Plattform unter thepi.pe verwenden können, um Ihre Dateien hochzuladen und Ihr Ergebnis als CSV herunterzuladen, ohne Code schreiben zu müssen.
Installieren Sie die erforderlichen Bibliotheken
Öffnen Sie Ihr Terminal oder Ihre Eingabeaufforderung und führen Sie die folgenden Befehle aus:
pip install git https://github.com/emcf/thepipe pip install pandas
Für Python-Neulinge: pip ist das Paketinstallationsprogramm für Python, und diese Befehle laden die erforderlichen Bibliotheken herunter und installieren sie.
Richten Sie Ihren API-Schlüssel ein
Um die Pipe zu verwenden, benötigen Sie einen API-Schlüssel.
Haftungsausschluss: Während thepi.pe ein kostenloses Open-Source-Tool ist, kostet die API etwa 0,00002 US-Dollar pro Token. Wenn Sie solche Kosten vermeiden möchten, schauen Sie sich die Anleitung zur lokalen Einrichtung auf GitHub an. Beachten Sie, dass Sie weiterhin den LLM-Anbieter Ihrer Wahl bezahlen müssen.
So erhalten und richten Sie es ein:
- Besuchen Sie https://thepi.pe/platform/
- Erstellen Sie ein Konto oder melden Sie sich an
- Suchen Sie Ihren API-Schlüssel auf der Einstellungsseite

Jetzt müssen Sie dies als Umgebungsvariable festlegen. Der Vorgang variiert je nach Betriebssystem:
- Kopieren Sie den API-Schlüssel aus dem Einstellungsmenü auf der pi.pe-Plattform
Für Windows:
- Suchen Sie im Startmenü nach „Umgebungsvariablen“
- Klicken Sie auf „Systemumgebungsvariablen bearbeiten“
- Klicken Sie auf die Schaltfläche „Umgebungsvariablen“
- Klicken Sie unter „Benutzervariablen“ auf „Neu“
- Legen Sie den Variablennamen als THEPIPE_API_KEY und den Wert als Ihren API-Schlüssel fest
- Klicken Sie zum Speichern auf „OK“
Für macOS und Linux:
Öffnen Sie Ihr Terminal und fügen Sie diese Zeile zu Ihrer Shell-Konfigurationsdatei hinzu (z. B. ~/.bashrc oder ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
Dann laden Sie Ihre Konfiguration neu:
source ~/.bashrc # or ~/.zshrc
Definieren Ihres Extraktionsschemas
Der Schlüssel zu einer erfolgreichen Extraktion liegt in der Definition eines klaren Schemas für die Daten, die Sie extrahieren möchten. Nehmen wir an, wir extrahieren Daten aus einem Stücklistendokument:

Ein Beispiel für eine Seite aus dem Stücklistendokument. Die Daten auf jeder Seite sind unabhängig von den anderen Seiten, daher führen wir unsere Extraktion „pro Seite“ durch. Pro Seite müssen mehrere Daten extrahiert werden, daher setzen wir mehrere Extraktionen auf True
Wenn wir uns die Spaltennamen ansehen, möchten wir vielleicht ein Schema wie dieses extrahieren:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
Sie können das Schema auf der pi.pe-Plattform nach Ihren Wünschen ändern. Wenn Sie auf „Schema anzeigen“ klicken, erhalten Sie ein Schema, das Sie zur Verwendung mit der Python-API kopieren und einfügen können
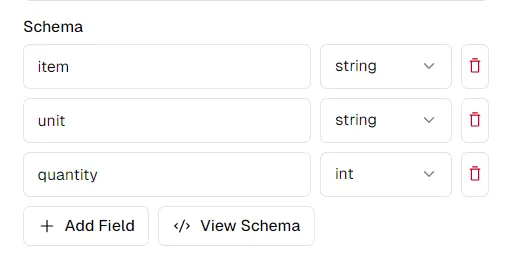
Extrahieren von Daten aus PDFs
Jetzt verwenden wir extract_from_file, um Daten aus einer PDF-Datei abzurufen:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
Hier haben wir chunking_method="chunk_by_page", weil wir jede Seite einzeln an das KI-Modell senden möchten (die PDF-Datei ist zu groß, um alle auf einmal einzuspeisen). Wir setzen auch multiple_extractions=True, da die PDF-Seiten jeweils mehrere Datenzeilen enthalten. So sieht eine Seite aus dem PDF aus:
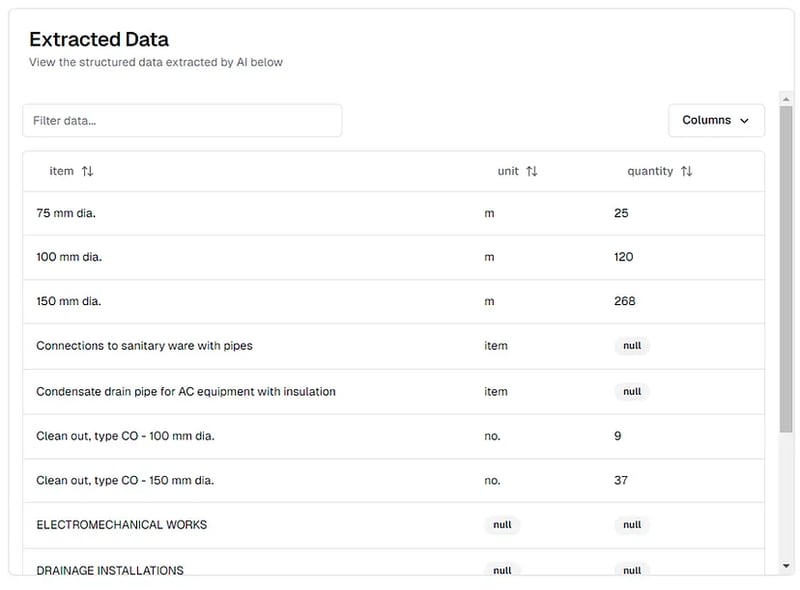
Die Ergebnisse der Extraktion für die Stücklisten-PDF, wie auf der thepi.pe-Plattform angezeigt
Verarbeitung der Ergebnisse
Die Extraktionsergebnisse werden als Liste von Wörterbüchern zurückgegeben. Wir können diese Ergebnisse verarbeiten, um einen Pandas-DataFrame zu erstellen:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
Dadurch wird ein DataFrame mit allen extrahierten Informationen erstellt, einschließlich Textinhalten und Beschreibungen visueller Elemente wie Abbildungen und Tabellen.
Exportieren in verschiedene Formate
Da wir nun unsere Daten in einem DataFrame haben, können wir sie problemlos in verschiedene Formate exportieren. Hier sind einige Optionen:
Exportieren nach Excel
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
Dadurch wird eine Excel-Datei namens „extracted_research_data.xlsx“ mit einem Blatt namens „Research Data“ erstellt. Der Parameter index=False verhindert, dass der DataFrame-Index als separate Spalte eingefügt wird.
Exportieren in CSV
Wenn Sie ein einfacheres Format bevorzugen, können Sie in CSV exportieren:
df.to_csv("extracted_research_data.csv", index=False)
Dadurch wird eine CSV-Datei erstellt, die in Excel oder einem beliebigen Texteditor geöffnet werden kann.
Schlussbemerkungen
Der Schlüssel zu einer erfolgreichen Extraktion liegt in der Definition eines klaren Schemas und der Nutzung der multimodalen Fähigkeiten des KI-Modells. Wenn Sie mit diesen Techniken vertrauter werden, können Sie erweiterte Funktionen wie benutzerdefinierte Chunking-Methoden, benutzerdefinierte Extraktionsaufforderungen und die Integration des Extraktionsprozesses in größere Datenpipelines erkunden.
-
 Leitfaden zur Lösung von CORS -Problemen in der Frühjahrssicherheit 4.1 und höherSpring Security CORS Filter: Fehlerbehebung gemeinsame Ausgaben Bei der Integration von Frühlingssicherheit in ein vorhandenes Projekt können ...Programmierung Gepostet am 2025-04-27
Leitfaden zur Lösung von CORS -Problemen in der Frühjahrssicherheit 4.1 und höherSpring Security CORS Filter: Fehlerbehebung gemeinsame Ausgaben Bei der Integration von Frühlingssicherheit in ein vorhandenes Projekt können ...Programmierung Gepostet am 2025-04-27 -
Wie sende ich eine Roh Postanforderung mit Curl in PHP?Wie sende ich eine rohe Postanfrage mit curl in php in php, curl ist eine beliebte Bibliothek für das Senden von HTTP -Anfragen. In diesem Art...Programmierung Gepostet am 2025-04-27
-
Warum können Java nicht generische Arrays erstellen?generic Array Creation error Frage: , wenn wir versuchen, eine Array von generischen Klassen zu erstellen. ArrayList [2]; public static A...Programmierung Gepostet am 2025-04-27
-
Kann ich meine Verschlüsselung von McRypt nach OpenSSL migrieren und mit OpenSSL von McRypt-verkürzten Daten entschlüsseln?Upgrade meiner Verschlüsselungsbibliothek von McRypt auf OpenSSL Kann ich meine Verschlüsselungsbibliothek von McRypt nach OpenSsl aufrüsten? ...Programmierung Gepostet am 2025-04-27
-
Wie kann ich Kompilierungsoptimierungen im Go -Compiler anpassen?Anpassung von Kompilierungsoptimierungen in Go Compiler Der Standardkompilierungsprozess in Go folgt einer spezifischen Optimierungsstrategie....Programmierung Gepostet am 2025-04-27
-
Wie extrahiere ich Elemente aus dem 2D -Array? Verwenden Sie einen anderen Array -IndexVerwenden von Numpy -Array als Indizes für die 2. Dimension eines anderen Array um bestimmte Elemente aus einem 2D -Array zu extrahieren, das ...Programmierung Gepostet am 2025-04-27
-
Wie kann ich nach der Bearbeitung von Zellen eine kundenspezifische JTable -Zell -Rendering beibehalten?beibehalten von jtable cell rendering nach cell edit in einem jtable, in dem benutzerdefinierte Zellenwiedergabe implementiert werden, kann di...Programmierung Gepostet am 2025-04-27
-
Welche Methode ist effizienter für die Erkennung von Punkt-in-Polygon: Strahlenverfolgung oder Matplotlib \ 's path.contains_points?effiziente Punkt-in-Polygon-Erkennung in Python festlegen, ob ein Punkt innerhalb eines Polygons eine häufige Aufgabe in der Computergeometrie i...Programmierung Gepostet am 2025-04-27
-
Lösen Sie den \\ "String -Wert -Fehler \\" -Ausnahme, wenn MySQL Emoji einfügtdie falsche String -Wert -Ausnahme beheben, wenn er Emoji beim Versuch, eine Zeichenfolge mit Emoji -Zeichen in eine mysql -Datenbank einzufügen...Programmierung Gepostet am 2025-04-27
-
Wie fahre ich gleichzeitig asynchrone Vorgänge aus und behandeln Fehler in JavaScript ordnungsgemäß?gleichzeitlich erwartet die Operation Execution Der in Frage stehende Code -Snippet begegnet ein Problem, wenn Asynchronous -Operationen ausge...Programmierung Gepostet am 2025-04-27
-
Wie extrahieren Sie ein zufälliges Element aus einem Array in PHP?zufällige Auswahl aus einem Array In PHP kann ein zufälliger Element aus einem Array mit Leichtigkeit erreicht werden. Betrachten Sie das folgen...Programmierung Gepostet am 2025-04-27
-
Warum kann Microsoft Visual C ++ keine zweiphasige Vorlage-Instanziierung korrekt implementieren?Das Geheimnis von "kaputte" Two-Phase-Vorlage Instantiation in Microsoft visual c Problemanweisung: Benutzer werden häufig besorgt...Programmierung Gepostet am 2025-04-27
-
Wie sendet Android Postdaten an PHP Server?So senden Sie Postdaten um Postdaten in Android zu senden, gibt es mehrere Ansätze: 1. Apache httpclient (veraltet) httpclient httpcli...Programmierung Gepostet am 2025-04-27
-
Warum hört die Ausführung von JavaScript ein, wenn die Firefox -Rückbutton verwendet wird?Navigational History Problem: JavaScript hört auf, nach der Verwendung von Firefox -Back -Schaltflächen auszuführen. Dieses Problem tritt in ande...Programmierung Gepostet am 2025-04-26
-
Wie kann man eine generische Hash -Funktion für Tupel in ungeordneten Sammlungen implementieren?generische Hash -Funktion für Tupel in nicht ordnungsgemäßen Sammlungen Die std :: unbestrahlte_Map und std :: unconded_set Container bieten e...Programmierung Gepostet am 2025-04-26















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









