
Evaluierung eines Klassifizierungsmodells für maschinelles Lernen
 Durchsuche:252
Durchsuche:252
Gliederung
- Was ist das Ziel der Modellevaluierung?
- Was ist der Zweck der Modellevaluierung und welche davon gibt es? gemeinsame Bewertungsverfahren?
- Wozu dient die Klassifizierungsgenauigkeit und wozu dient sie? Einschränkungen?
- Wie beschreibt eine Verwirrungsmatrix die Leistung eines Klassifikator?
- Welche Kennzahlen können aus einer Verwirrungsmatrix berechnet werden?
DDas Ziel der Modellevaluierung ist die Beantwortung der Frage;
Wie wähle ich zwischen verschiedenen Modellen?
Der Prozess der Bewertung eines maschinellen Lernens hilft festzustellen, wie zuverlässig und effektiv das Modell für seine Anwendung ist. Dazu gehört die Bewertung verschiedener Faktoren wie Leistung, Metriken und Genauigkeit für Vorhersagen oder Entscheidungsfindung.
Ganz gleich, für welches Modell Sie sich entscheiden, Sie benötigen eine Möglichkeit, zwischen Modellen zu wählen: verschiedene Modelltypen, Tuning-Parameter und Funktionen. Außerdem benötigen Sie ein Modellbewertungsverfahren, um abzuschätzen, wie gut sich ein Modell auf unsichtbare Daten verallgemeinern lässt. Schließlich benötigen Sie ein Bewertungsverfahren, das mit Ihrem Verfahren in anderen Bereichen gekoppelt werden kann, um die Leistung Ihres Modells zu quantifizieren.
Bevor wir fortfahren, werfen wir einen Blick auf einige der verschiedenen Modellbewertungsverfahren und ihre Funktionsweise.
Modellbewertungsverfahren und ihre Funktionsweise.
-
Training und Tests mit denselben Daten
- Belohnt übermäßig komplexe Modelle, die die Trainingsdaten „überpassen“ und nicht unbedingt verallgemeinern
-
Trainings-/Testaufteilung
- Teilen Sie den Datensatz in zwei Teile auf, damit das Modell auf verschiedenen Daten trainiert und getestet werden kann
- Bessere Schätzung der Leistung außerhalb der Stichprobe, aber immer noch eine Schätzung mit „hoher Varianz“
- Nützlich aufgrund seiner Geschwindigkeit, Einfachheit und Flexibilität
-
K-fache Kreuzvalidierung
- Erstellen Sie systematisch „K“-Zug-/Testaufteilungen und mitteln Sie die Ergebnisse zusammen
- Noch bessere Schätzung der Leistung außerhalb der Stichprobe
- Läuft „K“-mal langsamer als die Aufteilung zwischen Training und Test.
Von oben können wir Folgendes ableiten:
Training und Tests mit denselben Daten sind eine klassische Ursache für Überanpassung, bei der Sie ein übermäßig komplexes Modell erstellen, das sich nicht auf neue Daten verallgemeinern lässt und das eigentlich nicht nützlich ist.
Train_Test_Split bietet eine viel bessere Schätzung der Leistung außerhalb der Stichprobe.
K-fache Kreuzvalidierung ist besser, wenn systematisch K-Trainingstests aufgeteilt und die Ergebnisse gemittelt werden.
Zusammenfassend ist train_tests_split aufgrund seiner Geschwindigkeit und Einfachheit immer noch profitabel für die Kreuzvalidierung, und genau das werden wir in diesem Tutorial-Leitfaden verwenden.
Modellbewertungsmetriken:
Sie benötigen immer eine Bewertungsmetrik, die zu Ihrem gewählten Verfahren passt, und Ihre Wahl der Metrik hängt von dem Problem ab, das Sie ansprechen. Bei Klassifizierungsproblemen können Sie die Klassifizierungsgenauigkeit verwenden. Aber wir werden uns in diesem Leitfaden auf andere wichtige Klassifizierungsbewertungsmetriken konzentrieren.
Bevor wir neue Bewertungsmetriken kennenlernen, überprüfen wir die Klassifizierungsgenauigkeit und sprechen über ihre Stärken und Schwächen.
Klassifizierungsgenauigkeit
Wir haben für dieses Tutorial den Pima Indians Diabetes-Datensatz ausgewählt, der die Gesundheitsdaten und den Diabetesstatus von 768 Patienten enthält.
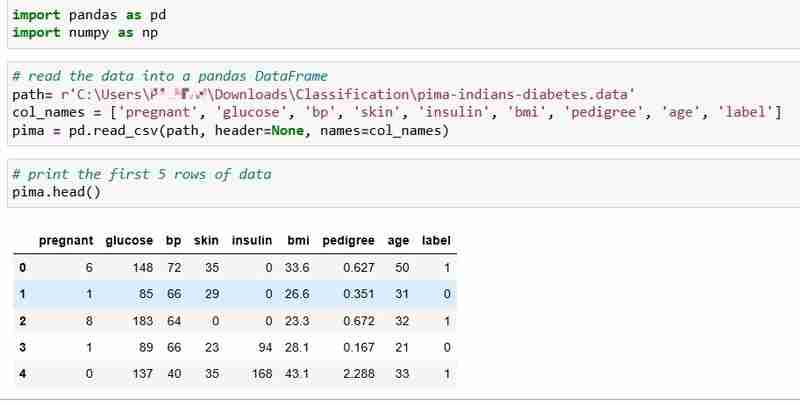
Lassen Sie uns die Daten lesen und die ersten 5 Zeilen der Daten drucken. Die Beschriftungsspalte zeigt 1 an, wenn der Patient Diabetes hat, und 0, wenn der Patient keinen Diabetes hat. Wir beabsichtigen, die Frage zu beantworten:
Frage: Können wir den Diabetesstatus eines Patienten anhand seiner Gesundheitswerte vorhersagen?
Wir definieren unsere Funktionsmetriken X und Antwortvektor Y. Wir verwenden train_test_split, um X und Y in Trainings- und Testsätze aufzuteilen.
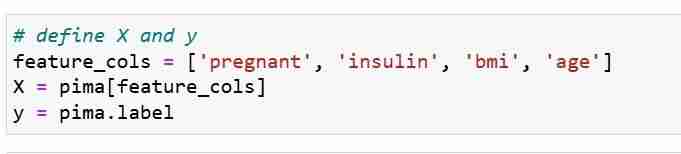
Als nächstes trainieren wir ein logistisches Regressionsmodell auf dem Trainingssatz. Während des Anpassungsschritts lernt das Logreg-Modellobjekt die Beziehung zwischen X_train und Y_train. Schließlich machen wir eine Klassenvorhersage für die Testsätze.
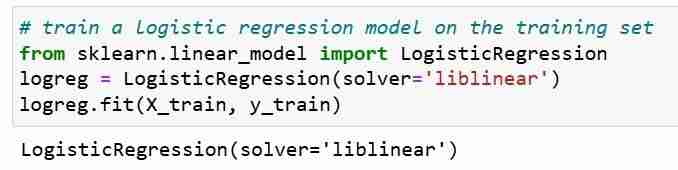

Nachdem wir die Vorhersage für den Testsatz getroffen haben, können wir die Klassifizierungsgenauigkeit berechnen, die einfach den Prozentsatz der korrekten Vorhersagen darstellt.
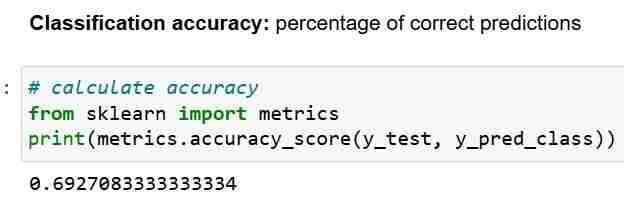
Wenn Sie jedoch die Klassifizierungsgenauigkeit als Ihre Bewertungsmetrik verwenden, ist es wichtig, sie mit der Nullgenauigkeit zu vergleichen. Dies ist die Genauigkeit, die erreicht werden könnte, wenn immer die häufigste Klasse vorhergesagt wird.

Nullgenauigkeit beantwortet die Frage; Wenn mein Modell die vorherrschende Klasse in 100 Prozent der Fälle vorhersagen würde, wie oft würde es dann korrekt sein? Im obigen Szenario sind 32 % des y_test 1 (Einsen). Mit anderen Worten, ein dummes Modell, das vorhersagt, dass der Patient Diabetes hat, würde in 68 % der Fälle richtig liegen (das sind die Nullen). Dies liefert eine Basislinie, an der wir unsere logistische Regression möglicherweise messen möchten Modell.
Wenn wir die Nullgenauigkeit von 68 % und die Modellgenauigkeit von 69 % vergleichen, sieht unser Modell nicht sehr gut aus. Dies zeigt eine Schwäche der Klassifizierungsgenauigkeit als Modellbewertungsmetrik. Die Klassifizierungsgenauigkeit sagt uns nichts über die zugrunde liegende Verteilung des Testtests.
Zusammenfassung:
- Klassifizierungsgenauigkeit ist die am einfachsten zu verstehende Klassifizierungsmetrik
- Aber es sagt Ihnen nichts über die zugrundeliegende Verteilung der Antwortwerte
- Und es sagt Ihnen nicht, welche "Typen" von Fehlern Ihr Klassifikator macht.
Sehen wir uns nun die Verwirrungsmatrix an.
Verwirrungsmatrix
Die Verwirrungsmatrix ist eine Tabelle, die die Leistung eines Klassifizierungsmodells beschreibt.
Es ist nützlich, um Ihnen zu helfen, die Leistung Ihres Klassifikators zu verstehen, es handelt sich jedoch nicht um eine Modellbewertungsmetrik; Sie können Scikit Learn also nicht anweisen, das Modell mit der besten Verwirrungsmatrix auszuwählen. Es gibt jedoch viele Metriken, die aus der Verwirrungsmatrix berechnet und direkt zur Auswahl zwischen Modellen verwendet werden können.
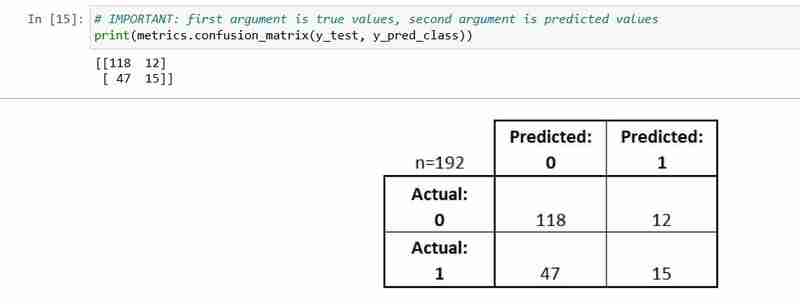
- Jede Beobachtung im Testsatz wird in genau einem Feld dargestellt.
- Es ist eine 2x2-Matrix, weil es 2 Antwortklassen gibt
- Das hier gezeigte Format ist nicht universell
Lassen Sie uns einige seiner grundlegenden Terminologien erklären.
- True Positives (TP): Wir haben richtig vorhergesagt, dass sie Diabetes haben
- True Negatives (TN): wir haben richtig vorhergesagt, dass sie keinen Diabetes haben
- False Positives (FP): wir haben fälschlicherweise vorhergesagt, dass sie Diabetes haben (ein „Typ-I-Fehler“) Falsche Negative (FN):
- wir haben fälschlicherweise vorhergesagt, dass sie keinen Diabetes haben (ein „Typ-II-Fehler“) Sehen wir uns an, wie wir die Kennzahlen berechnen können
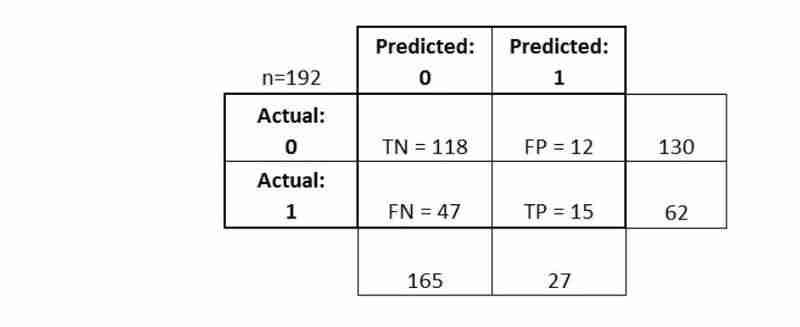


Die Verwirrungsmatrix gibt Ihnen ein
- vollständigeres Bild
- der Leistung Ihres Klassifikators Ermöglicht Ihnen außerdem die Berechnung verschiedener Klassifizierungsmetriken
- , und diese Metriken können Sie bei Ihrer Modellauswahl unterstützen
-
 So laden Sie Dateien mit zusätzlichen Parametern mit java.net.urlconnection und Multipart/Form-Data-Codierung hoch?Dateien mit Http-Anfragen hochladen , um Dateien auf einen HTTP-Server hochzuladen und gleichzeitig zusätzliche Parameter zu senden. Hier ist e...Programmierung Gepostet am 2025-04-12
So laden Sie Dateien mit zusätzlichen Parametern mit java.net.urlconnection und Multipart/Form-Data-Codierung hoch?Dateien mit Http-Anfragen hochladen , um Dateien auf einen HTTP-Server hochzuladen und gleichzeitig zusätzliche Parameter zu senden. Hier ist e...Programmierung Gepostet am 2025-04-12 -
Wie setze ich Tasten in JavaScript -Objekten dynamisch ein?wie man einen dynamischen Schlüssel für eine JavaScript -Objektvariable erstellt beim Versuch, einen dynamischen Schlüssel für ein JavaScript -O...Programmierung Gepostet am 2025-04-12
-
YII-Framework baut schnell Crud-Anwendungen auf, ein Muss für PHP-ExpertenYii框架:快速构建高效CRUD应用的指南 Yii是一个高性能的PHP框架,以其速度、安全性以及对Web 2.0应用的良好支持而闻名。它遵循“约定优于配置”的原则,这意味着只要遵循其规范,就能编写比其他框架少得多的代码(更少的代码意味着更少的bug)。此外,Yii还提供了许多开箱即用的便捷功能,例如...Programmierung Gepostet am 2025-04-12
-
Wie kann man Zeitzonen effizient in PHP konvertieren?effiziente Timezone -Konvertierung in php In PHP können TimeZones eine einfache Aufgabe sein. Dieser Leitfaden bietet eine leicht zu implementie...Programmierung Gepostet am 2025-04-12
-
Wie füge ich Blobs (Bilder) mithilfe von PHP richtig in MySQL ein?Fügen Sie Blobs in mySQL -Datenbanken mit php beim Versuch, ein Bild in einer MySQL -Datenbank zu speichern, auf eine auf ein Bild zu speiche...Programmierung Gepostet am 2025-04-12
-
Warum erscheint mein CSS -Hintergrundbild nicht?Fehlerbehebung: CSS -Hintergrundbild erscheinen nicht Sie haben auf ein Problem gestoßen, bei dem Ihr Hintergrundbild trotz der folgenden Tuto...Programmierung Gepostet am 2025-04-12
-
Wie kann ich die letzte Zeile für jede eindeutige Kennung in PostgreSQL effizient abrufen?postgresql: Extrahieren der letzten Zeile für jede eindeutige Kennung In Postgresql können Sie Situationen begegnen, in denen Sie die Informat...Programmierung Gepostet am 2025-04-12
-
Wie beheben Sie die Diskrepanzen für Modulpfade in Go -Mod mithilfe der Richtlinie Ersetzen?überwinden Modulpfad -Diskrepanz in go mod Wenn GO mod verwendet wird, ist es möglich, auf einen Konflikt zu begegnen, bei dem ein Drittanbiet...Programmierung Gepostet am 2025-04-12
-
Properties.Settings.Default -Anwendungseinstellungen Speicherort werden angegebenEigenschaften verstehen. c#'s properties.setings.default bietet eine bequeme Möglichkeit, die Anwendungseinstellungen zu verwalten und sie ...Programmierung Gepostet am 2025-04-12
-
Können mehrere klebrige Elemente in reinem CSS übereinander gestapelt werden?Ist es möglich, in reinem CSS mehrere klebrige Elemente gestapelt zu haben? Hier: https://webthemez.com/demo/sticky-multi-header-scroll/index.ht...Programmierung Gepostet am 2025-04-12
-
Wie behandle ich den Benutzereingang im exklusiven Modus von Java von Java?verwandeln Benutzereingaben im Vollbildmodus in java Einführung Wenn eine Java -Anwendung im Vollbildmodus exklusiver Modus ausgeführt wird,...Programmierung Gepostet am 2025-04-12
-
Warum bekomme ich in meiner Silverlight Linq -Abfrage einen Fehler "konnte keine Implementierung des Abfragemuster -Fehlers finden?"Abfragemuster -Implementierung Abwesenheit: Auflösung "konnte nicht" fehler In einer Silberlight -Anwendung, ein Versuch, eine Daten...Programmierung Gepostet am 2025-04-12
-
ES6 Praktischer Kampf: Verbessertes Objekt wörtliches6 Objektliteraler Verbesserung: Vereinfachen Sie JavaScript -Objektoperationen ] Die von ES6 eingeführten erweiterten Objektliteraleigenschaf...Programmierung Gepostet am 2025-04-12
-
Enthülle, ob mySQL_REAL_ESCAPE_STRING eine SQL -Injektion verhindern kannEinschränkungen von mysql_real_escape_string Die MySQL_REAL_ESCAPE_STRING -Funktion in PHP wurde dafür kritisiert, dass sie nicht umfassende S...Programmierung Gepostet am 2025-04-12
-
Wie kann ich mehrere Benutzertypen (Schüler, Lehrer und Administratoren) in ihre jeweiligen Aktivitäten in einer Firebase -App umleiten?rot: Wie man mehrere Benutzertypen zu jeweiligen Aktivitäten umleitet Login. Der aktuelle Code verwaltet die Umleitung für zwei Benutzertypen erf...Programmierung Gepostet am 2025-04-12















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









