 Titelseite > Programmierung > Daten-API für Amazon Aurora Serverless mit AWS SDK für Java – Teil Aurora Serverless Vata API trifft DevOps Guru oder nicht?
Titelseite > Programmierung > Daten-API für Amazon Aurora Serverless mit AWS SDK für Java – Teil Aurora Serverless Vata API trifft DevOps Guru oder nicht?
Daten-API für Amazon Aurora Serverless mit AWS SDK für Java – Teil Aurora Serverless Vata API trifft DevOps Guru oder nicht?
 Durchsuche:354
Durchsuche:354
Einführung
In meinem Artikel „Amazon DevOps Guru für serverlose Anwendungen – Teil 10 Anomalieerkennung auf Aurora Serverless v2“ haben wir erfahren, dass DevOps Guru Anomalien mit der PostgreSQL-Datenbank Aurora (Serverless v2) erfolgreich erkennen konnte, wenn die Lambda-Funktion mit Java 21 verwaltet wurde Runtime war über JDBC damit verbunden. Wir haben unsere Datenbank nur von 0,5 auf 1 ACU skaliert und eine sehr hohe Belastung der Datenbank verursacht, indem wir die Lambda-Funktion mehrere Hundert Mal gleichzeitig mehrere Minuten lang aufgerufen haben, um Produkte nach ID abzurufen. Wir haben gesehen, dass DevOps Guru richtig auf die erhöhte Summe an Datenbankverbindungen und die konstant hohe Datenbanklast (CPU) hingewiesen hat. In diesem Artikel möchte ich herausfinden, ob DevOps Guru die Anomalie erkennt, indem er dasselbe Experiment durchführt, aber die Daten-API für Aurora Serverless v2 mit AWS SDK für Java anstelle von JDBC verwendet.
Anomalieerkennung auf Aurora Serverless v2 mit Daten-API
Sehen wir uns unsere Beispielanwendung an und verwenden die SAM-Vorlage, um eine Infrastruktur zu erstellen und die im folgenden Bild beschriebene Anwendung bereitzustellen:
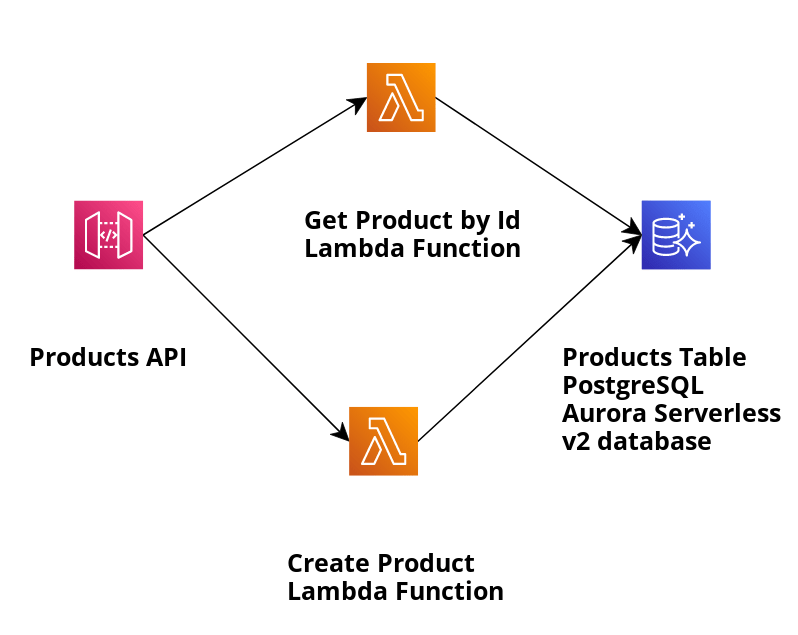
Die Anwendung erstellt Produkte, die in der Aurora Serverless v2 PostgreSQL-Datenbank gespeichert sind, und ruft sie mithilfe der Daten-API nach ID ab. Die relevante Lambda-Funktion, die wir verwenden, um das Produkt anhand seiner ID abzurufen, ist GetProductByIdViaAuroraServerlessV2DataApi und ihre Handler-Implementierung ist GetProductByIdViaAuroraServerlessV2DataApiHandler.
Wie im vorherigen Artikel verwenden wir das Hey-Tool, um den Stresstest wie folgt durchzuführen
hey -z 15m -c 300 -H "X-API-Key: XXXa6XXXX" https://XXX.execute-api.eu-central-1.amazonaws.com/prod/productsWithDataApi/1
In diesem Beispiel rufen wir den API Gateway-Endpunkt mit 300 gleichzeitigen Containern für 15 Minuten auf. Hinter dem prod/productsWithoutDataApi-Endpunkt wird die Lambda-Funktion GetProductByIdViaAuroraServerlessV2WithoutDataApi aufgerufen, die das Produkt mit der ID 1 aus der Aurora Serverless v2 PostgreSQL-Datenbank abruft.
Wir haben in unserer [SAM-Vorlage]((https://github.com/Vadym79/AWSLambdaJavaAuroraServerlessV2DataApi/blob/master/template.yaml) den Aurora-Datenbankcluster so konfiguriert, dass er von der minimalen Kapazität 0,5 auf die maximale Kapazität 1 ACU skaliert (was sehr kleine Datenbankgröße) im Falle einer erhöhten Auslastung aus Kostengründen.
AuroraServerlessV2Cluster:
Type: 'AWS::RDS::DBCluster'
...
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 1
Die Aurora (Serverless v2)-Datenbank verwaltet die maximale Anzahl der verfügbaren Datenbankverbindungen proportional zur Datenbankgröße (in unserem Fall die ACU-Einstellung) auch mit der Daten-API für Aurora Serverless v2 (was einen großen Unterschied zu v1 darstellt, der künftig sein wird). Ende des Jahres 2024 nicht mehr unterstützt, da eine feste Quote von 1000 Datenbankverbindungen pro Sekunde galt. Weitere Informationen finden Sie in der Dokumentation zu Maximale Verbindungen für Aurora Serverless v2. Daher gehen wir davon aus, dass wir mit der erhöhten Anzahl von Aufrufen bald die maximale Anzahl der verfügbaren Datenbankverbindungen und eine hohe Datenbankauslastung (CPU) erreichen werden, sodass die Datenbank nicht mehr auf die neuen Lambda-Funktionsanforderungen zum Abrufen von Produkten reagieren kann id (Lambda wird dann auch darauf stoßen). Damit provozieren wir die Anomalie und möchten herausfinden, ob DevOps Guru sie erkennen kann. Und es war irgendwie in der Lage... Folgende Erkenntnis wurde generiert:
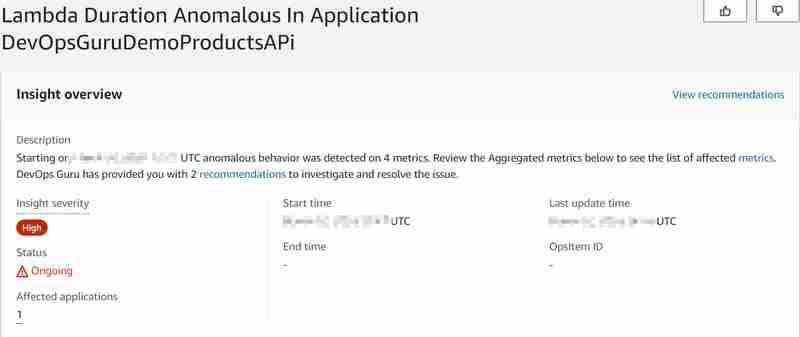
Und die folgenden aggregierten anomalen Messwerte wurden identifiziert:
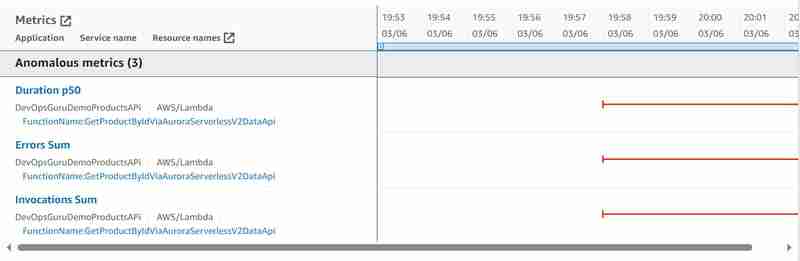
Im Vergleich zu den aggregierten anomalen Metriken, die bei der Verwendung von JDBC anstelle der Daten-API identifiziert wurden und in meinem Artikel „Amazon DevOps Guru für serverlose Anwendungen – Teil 10 Anomalieerkennung auf Aurora Serverless v2“ beschrieben sind, müssen wir die anomalen Metriken der Aurora-Datenbank: Datenbankverbindung vollständig durcheinander bringen Summe und Datenbank (CPU) laden, aber der Fehler in Lambda wird korrekt angezeigt, der innerhalb der definierten Zeitspanne von 15 Sekunden lief, da die Datenbank dies nicht konnte antworten.
 .
.
Also, was ist der Unterschied? Lassen Sie uns beide Vorfälle untersuchen, die wir auf dem Aurora Serverless v2 PostgreSQL-Cluster mit JDBC (Non Data API) und Data API reproduziert haben:
In Bezug auf die ACU-Auslastung/Skalierung sehen beide gleich aus:
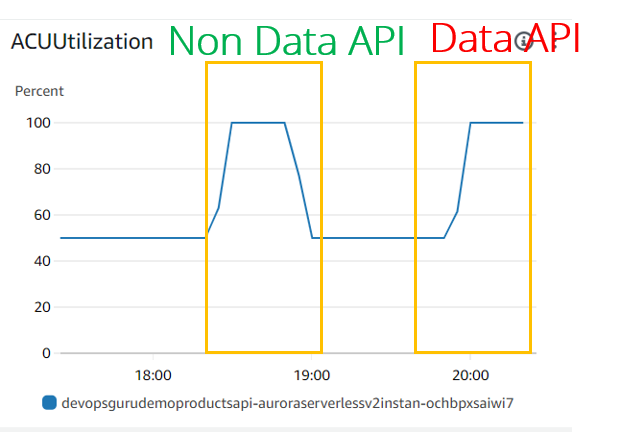
In Bezug auf andere Datenbankmetriken wie CPU-Auslastung, DatabaseConnection DBLoad (CPU) gibt es große Unterschiede:
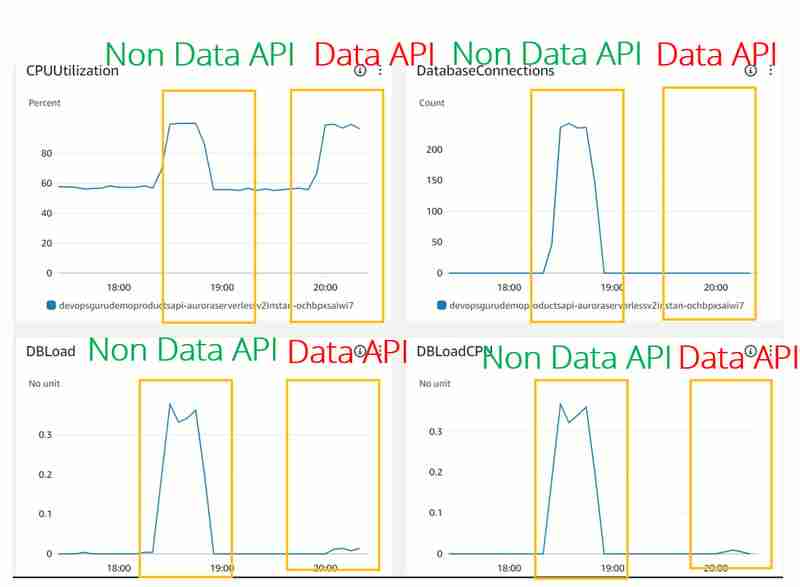
- Die CPU-Auslastung sieht für JDBC- (Nicht-Daten-API) und Daten-API-Fälle gleich aus. Aber DevOps Guru scheint diese Metrik nicht zu berücksichtigen, da wir sie nicht einmal beim JDBC-Experiment gesehen haben
- DBLoad(CPU), was für die Daten-API-Nutzung sehr niedrig ist. Es scheint, dass es für die Dat-API einen Load Balancer vor der Aurora Serverless v2-Datenbank gibt, der die Verbindungsnutzung überwacht und die Datenbank vor Überlastung schützt.
- DatabaseConnection-Metrik wird für die Daten-API-Nutzung nicht angezeigt (oder als 0 angezeigt). Der Grund dafür ist, dass wir die Datenbankverbindung für die Daten-API nicht verwalten, sondern auf der anderen Seite für uns. Natürlich spielen sie immer noch eine wichtige Rolle, wie wir in „Maximale Verbindungen für Aurora Serverless v2“ gelernt haben, aber diese Metrik scheint in den CloudWatch-Metriken nach außen offengelegt zu sein, und selbst DevOps Guru hat keinen Zugriff auf die tatsächlichen Zahlen.
Damit und bei sehr geringer DBLoad (CPU) wurden im Vergleich zum JDBC-Anwendungsfall keine DevOps Guru-Einblicke für den Aurora Serverless v2-Cluster mit Daten-API-Nutzung generiert.
Ich habe das zweite Experiment durchgeführt, indem ich mich direkt mit dem Aurora Serverless v2-Cluster verbunden habe, und das Skript zum Erstellen des Auslastungstests geschrieben, indem ich das Skript geschrieben habe, das das Produkt mehrere hundert Mal anhand der ID abruft, und zwar auf die Standardmethode (Nicht-Daten-API). Ähnlich wie wir es mit dem hey-Tool gemacht haben, aber direkt auf die Datenbank zugreifen, anstatt Api Gateway aufzurufen. Nachdem ich die Datenbank unter Last gesetzt hatte, startete ich das gleiche Experiment mit dem Tool hey wie oben beschrieben und wollte sehen, was passieren würde. Die gleiche Erkenntnis wurde generiert, dieses Mal jedoch mit den folgenden anomalen Metriken:
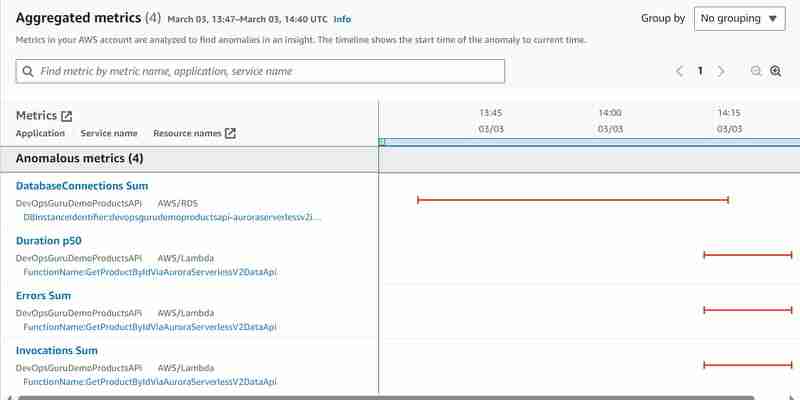
Jetzt sehen wir zumindest zusätzliche anomale Metriken für die Summe der Aurora Serverless v2-Datenbankverbindungen, aber DBLoad(CPU)-Metriken fehlen immer noch.
Grafische Anomalien sehen so aus:
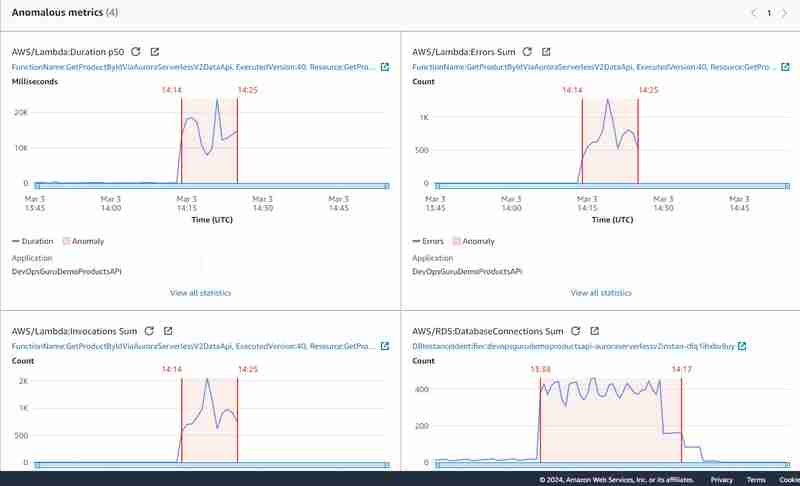
Natürlich war das Experiment nicht sauber, da ich zwei Lasttests nacheinander und teilweise parallel durchgeführt habe: Der erste stellte eine direkte Verbindung zur Datenbank ohne API-Gateway-Nutzung her und der zweite mithilfe der Daten-API. Dies bestätigte meine anfängliche Annahme, dass Datenbankverbindungssummenmetriken ein sehr wichtiges Kriterium sind, um DevOps-Guru-Einblicke für Aurora Serverless v2 (und für RDS im Allgemeinen) zu generieren, und dass sie bei Verwendung der Daten-API im Allgemeinen nicht offengelegt werden.
Ich habe bereits Kontakt zum Devops Guru-Team aufgenommen und ihnen meine Erkenntnisse mitgeteilt, mit der Erwartung, dass sie den Service verbessern werden. Oder zunächst wird die Offenlegung der Datenbankverbindung als CloudWatch-Metrik für die Verwendung von Aurora Serverless v2 mit Daten-API behoben.
Abschluss
In diesem Artikel erfahren Sie, dass DevOps Guru Anomalien mit der PostgreSQL-Datenbank Aurora (Serverless v2) erfolgreich erkennen konnte, wenn eine Lambda-Funktion mit einer verwalteten Java 21-Laufzeitumgebung über die Daten-API verbunden war, aber nur die anomalen Metriken im Zusammenhang mit der Lambda-Funktion anzeigen konnte Zeitüberschreitung, da die Datenbank nicht geantwortet hat. Der Hauptgrund dafür scheint zu sein, dass die Datenbankverbindung als CloudWatch-Metrik nicht verfügbar gemacht wird (oder immer als 0 angezeigt wird), wenn Aurora Serverless v2 mit Daten-API verwendet wird. Die Datenbankmetriken von Aurora Serverless v2 (Datenbankverbindungssumme) wurden nur während des zweiten künstlichen Experiments angezeigt.
-
 Wie kombiniere ich zwei assoziative Arrays in PHP und behalte dabei eindeutige IDs bei und verarbeite doppelte Namen?Kombinieren assoziativer Arrays in PHPIn PHP ist das Kombinieren zweier assoziativer Arrays zu einem einzigen Array eine häufige Aufgabe. Betrachten S...Programmierung Veröffentlicht am 19.11.2024
Wie kombiniere ich zwei assoziative Arrays in PHP und behalte dabei eindeutige IDs bei und verarbeite doppelte Namen?Kombinieren assoziativer Arrays in PHPIn PHP ist das Kombinieren zweier assoziativer Arrays zu einem einzigen Array eine häufige Aufgabe. Betrachten S...Programmierung Veröffentlicht am 19.11.2024 -
Wie behebt man „Unsachgemäß konfiguriert: Fehler beim Laden des MySQLdb-Moduls“ in Django unter macOS?MySQL falsch konfiguriert: Das Problem mit relativen PfadenBeim Ausführen von python manage.py runserver in Django kann der folgende Fehler auftreten:...Programmierung Veröffentlicht am 19.11.2024
-
Kann ich fahren? Codierung eines AlkoholtestersIn Dänemark, wo ich lebe, halten wir leider einen Rekord innerhalb Europas: Unsere Kinder sind die stärksten Alkoholtrinker auf dem Kontinent. Aus die...Programmierung Veröffentlicht am 18.11.2024
-
Warum funktioniert mein Python-MySQL-Einsatz nicht?Python MySQL Insert funktioniert nichtIn Python ist die Verwendung der MySQL-API zum Herstellen einer Verbindung mit einer MySQL-Datenbank ein beliebt...Programmierung Veröffentlicht am 18.11.2024
-
Verwendung von WebSockets in Go für EchtzeitkommunikationDas Erstellen von Apps, die Echtzeit-Updates erfordern – wie Chat-Anwendungen, Live-Benachrichtigungen oder Tools für die Zusammenarbeit – erfordert e...Programmierung Veröffentlicht am 18.11.2024
-
Behebung des Fehlers „Importanweisung kann nicht außerhalb eines Moduls verwendet werden“.Als JavaScript- und TypeScript-Entwickler stoßen wir bei der Arbeit mit verschiedenen Modulsystemen häufig auf unerwartete Fehler. Ein häufiges Proble...Programmierung Veröffentlicht am 18.11.2024
-
Wie stellt man von Localhost aus eine Verbindung zu einem Docker-MySQL-Container her?Herstellen einer Verbindung zum Docker-MySQL-Container von Localhost ausUm mit einer MySQL-Instanz zu interagieren, die in einem Docker-Container dire...Programmierung Veröffentlicht am 18.11.2024
-
Wie definiere ich Freundschaftsbeziehungen in Vorlagenklassen mit unterschiedlichen Vorlagenargumenten?Eintauchen in Klassenvorlagen mit VorlagenklassenfreundenBeim Definieren einer Binärbaumklasse (BT) und ihrer Elementklasse (BE). erforderlich, um ein...Programmierung Veröffentlicht am 18.11.2024
-
Jenseits von „if“-Anweisungen: Wo sonst kann ein Typ mit einer expliziten „bool“-Konvertierung ohne Umwandlung verwendet werden?Kontextuelle Konvertierung in bool ohne Umwandlung zulässigIhre Klasse definiert eine explizite Konvertierung in bool, sodass Sie ihre Instanz „t“ dir...Programmierung Veröffentlicht am 18.11.2024
-
## Aufbau eines robusten CMS-Backends: Wie können OOP und MVC-Struktur das Projektmanagement verbessern?PHP OOP Core Framework: Implementierung einer soliden Grundlage für ein CMS-BackendDas Verständnis der objektorientierten Programmierung (OOP) ist bei...Programmierung Veröffentlicht am 18.11.2024
-
Wie wird std::string implementiert und wie unterscheidet es sich von Strings im C-Stil?Eine Erkundung der Implementierung von std::stringDer rätselhafte std::string, eine grundlegende Komponente der C-Standardbibliothek, hat einen Funken...Programmierung Veröffentlicht am 18.11.2024
-
Warum wird (0 < 5 < 3) in JavaScript als wahr ausgewertet?JavaScripts vergleichendes Rätsel: Die innere Wahrheit entschlüsseln (0 < 5 < 3)Im Bereich JavaScript taucht eine eigenartige Beobachtung auf: Warum w...Programmierung Veröffentlicht am 18.11.2024
-
Was ist mit dem Spaltenversatz in Bootstrap 4 Beta passiert?Bootstrap 4 Beta: Die Entfernung und Wiederherstellung des SpaltenversatzesBootstrap 4 führte in seiner Beta-1-Version wesentliche Änderungen an der A...Programmierung Veröffentlicht am 18.11.2024
-
Wie behebe ich den Fehler „pip install Access Denied“ unter Windows mit mitmproxy?Behebung des Fehlers „pip install Access Denied“ unter Windows mit mitmproxyBeim Versuch, mitmproxy unter Windows mithilfe von pip zu installieren, st...Programmierung Veröffentlicht am 18.11.2024
-
Wie kann ich die Codeabdeckung von Integrationstests für eine Go-Binärdatei erfassen?Erfassen der Codeabdeckung aus einer Go-BinärdateiBeim Ausführen von Komponententests ist das Erfassen der Codeabdeckung unkompliziert. Allerdings kan...Programmierung Veröffentlicht am 18.11.2024















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









