 Titelseite > Programmierung > Konvertieren Sie mit dieser Funktion in Javascript einen String in camelCase.
Titelseite > Programmierung > Konvertieren Sie mit dieser Funktion in Javascript einen String in camelCase.
Konvertieren Sie mit dieser Funktion in Javascript einen String in camelCase.
 Durchsuche:431
Durchsuche:431
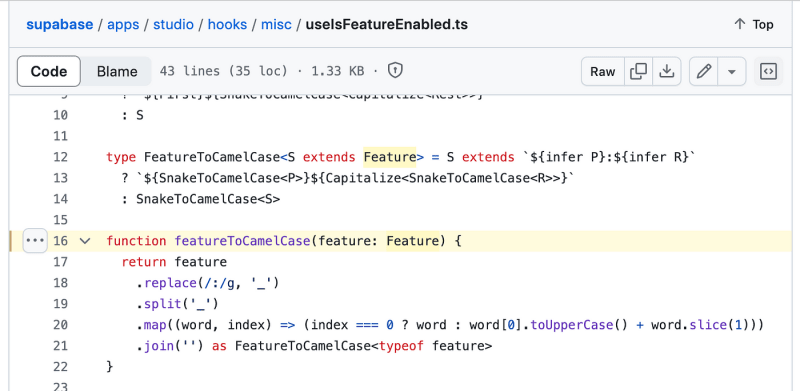
Mussten Sie schon einmal einen String in camelCase konvertieren? Beim Erkunden des Open-Source-Repositorys Supabase habe ich einen interessanten Codeausschnitt gefunden. Hier ist die Methode, die sie verwenden:
function featureToCamelCase(feature: Feature) {
return feature
.replace(/:/g, '\_')
.split('\_')
.map((word, index) => (index === 0 ? word : word\[0\].toUpperCase() word.slice(1)))
.join('') as FeatureToCamelCase
}
Diese Funktion ist ziemlich nett. Es ersetzt Doppelpunkte durch Unterstriche, teilt die Zeichenfolge in Wörter auf und ordnet dann jedes Wort zu, um es in camelCase umzuwandeln. Das erste Wort wird in Kleinbuchstaben geschrieben und bei den folgenden Wörtern wird das erste Zeichen groß geschrieben, bevor es wieder zusammengefügt wird. Einfach und doch effektiv!
Ich bin bei Stack Overflow auf einen anderen Ansatz gestoßen, der keine regulären Ausdrücke verwendet. Hier ist die Alternative:
function toCamelCase(str) {
return str.split(' ').map(function(word, index) {
// If it is the first word make sure to lowercase all the chars.
if (index == 0) {
return word.toLowerCase();
}
// If it is not the first word only upper case the first char and lowercase the rest.
return word.charAt(0).toUpperCase() word.slice(1).toLowerCase();
}).join('');
}
Dieser Codeausschnitt von SO enthält Kommentare, die erklären, was dieser Code tut, außer dass er keinerlei Regex verwendet. Der Code, der in Supabases Methode zum Konvertieren eines Strings in camelCase gefunden wird, ist dieser SO-Antwort sehr ähnlich, mit Ausnahme der Kommentare und des verwendeten regulären Ausdrucks.
.replace(/:/g, '\_')
Diese Methode teilt die Zeichenfolge nach Leerzeichen auf und ordnet sie dann jedem Wort zu. Das erste Wort wird vollständig in Kleinbuchstaben geschrieben, während die folgenden Wörter beim ersten Zeichen großgeschrieben und für den Rest kleingeschrieben werden. Abschließend werden die Wörter wieder zu einem CamelCase-String zusammengefügt.
Ein interessanter Kommentar eines Stack Overflow-Benutzers erwähnte den Leistungsvorteil dieses Ansatzes:
“ 1 für die Nichtverwendung regulärer Ausdrücke, auch wenn in der Frage nach einer Lösung gefragt wurde, die diese verwendet. Dies ist eine viel klarere Lösung und auch ein klarer Leistungsgewinn (da die Verarbeitung komplexer regulärer Ausdrücke eine viel schwierigere Aufgabe ist, als nur eine Reihe von Zeichenfolgen zu durchlaufen und Teile davon zusammenzufügen). Siehe jsperf.com/camel-casing-regexp-or-character-manipulation/1 wo ich einige der Beispiele hier zusammen mit diesem (und auch meinem eigenen bescheidenen Beispiel) genommen habe Verbesserung der Leistung, obwohl ich dieser Version aus Gründen der Übersichtlichkeit in den meisten Fällen wahrscheinlich den Vorzug geben würde).“
Beide Methoden haben ihre Vorzüge. Der Regex-Ansatz im Supabase-Code ist prägnant und nutzt leistungsstarke Techniken zur String-Manipulation. Andererseits wird der Nicht-Regex-Ansatz für seine Klarheit und Leistung gelobt, da er den mit regulären Ausdrücken verbundenen Rechenaufwand vermeidet.
So können Sie zwischen ihnen wählen:
- Verwenden Sie den Regex-Ansatz, wenn Sie eine kompakte, einzeilige Lösung benötigen, die die leistungsstarken Regex-Funktionen von JavaScript nutzt. Fügen Sie außerdem unbedingt Kommentare hinzu, die erklären, was Ihr regulärer Ausdruck bewirkt, damit Ihr zukünftiger Selbst- oder nächster Entwickler, der mit Ihrem Code arbeitet, es verstehen kann.
- Entscheiden Sie sich für die Nicht-Regex-Methode, wenn Sie Wert auf Lesbarkeit und Leistung legen, insbesondere wenn Sie mit längeren Zeichenfolgen arbeiten oder diese Konvertierung mehrmals ausführen.
Möchten Sie lernen, wie man shadcn-ui/ui von Grund auf erstellt? Schauen Sie sich an Build-from-Scratch
Über mich:
Website: https://ramunarasinga.com/
Linkedin: https://www.linkedin.com/in/ramu-narasinga-189361128/
Github: https://github.com/Ramu-Narasinga
E-Mail: [email protected]
Shadcn-ui/ui von Grund auf erstellen
Verweise:
- https://github.com/supabase/supabase/blob/master/apps/studio/hooks/misc/useIsFeatureEnabled.ts#L16
- https://stackoverflow.com/a/35976812
-
 Warum erscheint mein CSS -Hintergrundbild nicht?Fehlerbehebung: CSS -Hintergrundbild erscheinen nicht Sie haben auf ein Problem gestoßen, bei dem Ihr Hintergrundbild trotz der folgenden Tuto...Programmierung Gepostet am 2025-07-07
Warum erscheint mein CSS -Hintergrundbild nicht?Fehlerbehebung: CSS -Hintergrundbild erscheinen nicht Sie haben auf ein Problem gestoßen, bei dem Ihr Hintergrundbild trotz der folgenden Tuto...Programmierung Gepostet am 2025-07-07 -
Kann ich meine Verschlüsselung von McRypt nach OpenSSL migrieren und mit OpenSSL von McRypt-verkürzten Daten entschlüsseln?Upgrade meiner Verschlüsselungsbibliothek von McRypt auf OpenSSL Kann ich meine Verschlüsselungsbibliothek von McRypt nach OpenSsl aufrüsten? ...Programmierung Gepostet am 2025-07-07
-
Wie kann ich Zeilen effizient basierend auf zwei Bedingungen in MySQL einfügen oder aktualisieren?in zwei Bedingungen einfügen oder aktualisieren. Bestehende Zeile Wenn eine Übereinstimmung gefunden wird. Lösung: Die Antwort liegt in MyS...Programmierung Gepostet am 2025-07-07
-
Effektive Überprüfungsmethode für Java-Zeichenfolgen, die nicht leer und nicht null sindprüfen, ob ein String nicht null ist und nicht leer , ob ein String nicht null und nicht leer ist, Java bietet verschiedene Methoden. 1.6 and l...Programmierung Gepostet am 2025-07-07
-
Wie kann ich programmgesteuert den gesamten Text in einer DIV auf Mausklick auswählen?programmatisch den Div -Text in Maus auswählen klicken Frage angegeben ein DIV -Element mit Textinhalten, wie kann der Benutzer programmatisch...Programmierung Gepostet am 2025-07-07
-
Wie kann ich UTF-8-Dateinamen in den Dateisystemfunktionen von PHP bewältigen?Lösung: URL codieren Dateinamen , um dieses Problem zu beheben. Verwenden Sie die Urlencode-Funktion, um den gewünschten Ordnernamen in ein U...Programmierung Gepostet am 2025-07-07
-
Warum können Java nicht generische Arrays erstellen?generic Array Creation error Frage: , wenn wir versuchen, eine Array von generischen Klassen zu erstellen. ArrayList [2]; public static A...Programmierung Gepostet am 2025-07-07
-
Python Metaclass -Arbeitsprinzip und Klassenerstellung und -anpassungWas sind Metaklassen in Python? Metaklassen sind dafür verantwortlich, Klassenobjekte in Python zu erstellen. So wie Klassen Instanzen erstellen...Programmierung Gepostet am 2025-07-07
-
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-07-07
-
Können Templatparameter in C ++ 20 -Konstalfunktion von Funktionsparametern abhängen?konstvale Funktionen und Vorlagenparameter, die von Funktionsargumenten abhängen In c 17 kompile-time. c 20 canteval functions c 20 führ...Programmierung Gepostet am 2025-07-07
-
Wie können Sie Variablen in Laravel Blade -Vorlagen elegant definieren?Variablen in Laravel -Blattvorlagen mit Elegance verstehen, wie man Variablen in Klingenvorlagen zugewiesen ist, ist entscheidend für das Spei...Programmierung Gepostet am 2025-07-07
-
Wie beheben Sie die "ungültige Verwendung der Gruppenfunktion" in MySQL beim Finden der Maximalzahl?wie man die maximale zählende mit mysql in mysql abrufen Wählen Sie max (count (*)) aus der Emp1 -Gruppe nach Namen; ERROR 1111 (HY000): Ungül...Programmierung Gepostet am 2025-07-07
-
Wie kann ich exklusive Zeiger als Funktions- oder Konstruktorparameter in C ++ übergeben?Managing Unique Pointers as Parameters in Constructors and FunctionsUnique pointers (unique_ptr) uphold the principle of unique ownership in C 11. Wh...Programmierung Gepostet am 2025-07-07
-
Wie kann ich mit dem Python -Verständnis Wörterbücher effizient erstellen?Python Dictionary Verständnis In Python bieten Dictionary -Verständnisse eine kurze Möglichkeit, neue Wörterbücher zu generieren. Während sie de...Programmierung Gepostet am 2025-07-07
-
Wie erstelle ich in Python dynamische Variablen?dynamische variable Erstellung in Python Die Fähigkeit, dynamisch Variablen zu erstellen, kann ein leistungsstarkes Tool sein, insbesondere we...Programmierung Gepostet am 2025-07-07















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









