 Titelseite > Programmierung > So konvertieren Sie PDFs mit PyMuPDFM und seiner Auswertung in Markdown
Titelseite > Programmierung > So konvertieren Sie PDFs mit PyMuPDFM und seiner Auswertung in Markdown
So konvertieren Sie PDFs mit PyMuPDFM und seiner Auswertung in Markdown
 Durchsuche:975
Durchsuche:975
PyMuPDF4LLM ist eine Bibliothek zum Konvertieren von PDFs in das Markdown-Format. Hier teile ich meine Erfahrungen beim Testen dieser Bibliothek.
Installation
Beginnen Sie mit der Installation der Bibliothek mit dem folgenden Befehl:
pip install pymupdf4llm
Verwendung
Die grundlegende Verwendung ist recht einfach und erfordert nur drei Codezeilen, um ein PDF in Markdown zu konvertieren:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
Sie können Argumente angeben, um anzupassen, wie Inhalte extrahiert werden.
Text nach Seite extrahieren
Standardmäßig wird das gesamte PDF in eine einzige Textausgabe konvertiert. Sie können jedoch Text Seite für Seite extrahieren, indem Sie page_chunks=True angeben.
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
Bilder extrahieren
Um Bilder als Dateien zu extrahieren, verwenden Sie die Option write_images=True:
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
Es ist auch möglich, Bilder mithilfe der Base64-Kodierung direkt in den Markdown einzubetten:
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
Auswertung der Conversion-Ergebnisse
Zum Testen wurden verschiedene PDFs mit unterschiedlichen Markdown-Elementen verwendet.

Header-Konvertierung
Header werden korrekt in das Markdown-Format konvertiert. Hier ist ein Teil des Ergebnisses:
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
Fetter und kursiver Text
Fett- und Kursivformatierung wird ebenfalls ordnungsgemäß konvertiert:
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
Listenkonvertierung
Geordnete Listen auf der ersten Ebene werden ohne Probleme konvertiert, verschachtelte Listen und ungeordnete Listen werden jedoch nicht korrekt konvertiert.
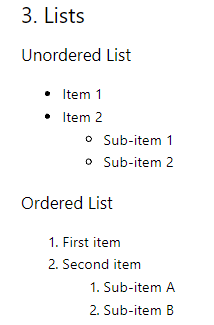
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
Linkkonvertierung
Die URLs von Links werden extrahiert, aber die gesamte Zeile, die den Link enthält, wird zu einem Hyperlink, was vom ursprünglichen Format abweicht.
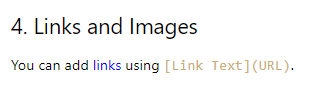
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
Bildextraktion
Bilder werden standardmäßig nicht extrahiert, können aber mit write_images=True lokal gespeichert werden.
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
Die gespeicherten Bilder werden dann im Markdown wie folgt referenziert:
### Image Example

Tabellenkonvertierung
Einfache Tabellen ohne vertikale Ränder werden nicht genau konvertiert (wahrscheinlich, weil mehrdeutige Spaltengrenzen dazu führen, dass Tabellen als einfacher Text behandelt werden).

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
Codekonvertierung
Codeblöcke werden korrekt konvertiert, die Sprachspezifikation (z. B. Python) bleibt jedoch nicht erhalten. Bei der Inline-Codekonvertierung gibt es ebenfalls Probleme.

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
Mehrzeiliger Text
Bei mehrzeiligem Text bleiben die Zeilenumbrüche so erhalten, wie sie im Original-PDF erscheinen.

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
Abschluss
Trotz der Herausforderungen bei der genauen Konvertierung von Listen und Links ist PyMuPDF4LLM ein nützliches Tool zum Konvertieren von PDFs in Markdown. Es kann lokal ohne die Notwendigkeit externer Sprachmodelle arbeiten und eignet sich daher für Umgebungen, in denen kein Internetzugang verfügbar ist.
-
 Wie begrenzt ich den Scroll-Bereich eines Elements in einem dynamisch großen übergeordneten Element?implementieren CSS -Höhenlimits für vertikale Scrolling -Elemente in einer interaktiven Schnittstelle und kontrollieren des Bildlaufverhaltens...Programmierung Gepostet am 2025-07-14
Wie begrenzt ich den Scroll-Bereich eines Elements in einem dynamisch großen übergeordneten Element?implementieren CSS -Höhenlimits für vertikale Scrolling -Elemente in einer interaktiven Schnittstelle und kontrollieren des Bildlaufverhaltens...Programmierung Gepostet am 2025-07-14 -
\ "während (1) gegen (;;): Beseitigt die Compiler -Optimierung Leistungsunterschiede? \"wob führt die Verwendung von (1) statt für (;;) zu einem Leistungsunterschied in Infinite führt Loops? Antwort: In den meisten modernen C...Programmierung Gepostet am 2025-07-14
-
Python Effizienter Weg, HTML -Tags aus Text zu entfernenhtml tags in python für eine makellose textuelle Darstellung manipulieren HTML -Antworten beinhalten oft die Extraktion relevanter Textinhalte...Programmierung Gepostet am 2025-07-14
-
Wie kann ich mit dem Python -Verständnis Wörterbücher effizient erstellen?Python Dictionary Verständnis In Python bieten Dictionary -Verständnisse eine kurze Möglichkeit, neue Wörterbücher zu generieren. Während sie de...Programmierung Gepostet am 2025-07-14
-
Warum bekomme ich in meiner Silverlight Linq -Abfrage einen Fehler "konnte keine Implementierung des Abfragemuster -Fehlers finden?"Abfragemuster -Implementierung Abwesenheit: Auflösung "konnte nicht" fehler In einer Silberlight -Anwendung, ein Versuch, eine Daten...Programmierung Gepostet am 2025-07-14
-
Muss ich vor dem Programm Exit explizit Heap -Zuordnungen in C ++ löschen?explizites Löschen in C trotz des Programms exit Wenn Sie mit dynamischer Speicherzuweisung in C arbeiten, fragen sich Entwickler oft, ob es n...Programmierung Gepostet am 2025-07-14
-
Effektive Überprüfungsmethode für Java-Zeichenfolgen, die nicht leer und nicht null sindprüfen, ob ein String nicht null ist und nicht leer , ob ein String nicht null und nicht leer ist, Java bietet verschiedene Methoden. 1.6 and l...Programmierung Gepostet am 2025-07-14
-
Wie kann man leere Arrays in PHP effizient erfassen?prüfen Array -Leere in php Ein leeres Array kann in Php durch verschiedene Ansätze bestimmt werden. Wenn das Vorhandensein eines Array -Elemen...Programmierung Gepostet am 2025-07-14
-
Wie kann man die Funktionsbeschränkungen von PHP 'Funktionen überwinden?Überwindung von PHP-Funktionsfunktionen Einschränkungen In PHP sind eine Funktion mit demselben Namen mehrmals ein No-no. Der Versuch, dies zu...Programmierung Gepostet am 2025-07-14
-
Warum HTML keine Seitenzahlen und Lösungen drucken kannkönnen Seitenzahlen auf html -Seiten nicht drucken? Gebraucht: @page { Marge: 10%; @Top-Center { Schriftfamilie: Sans-Serif; Schrift...Programmierung Gepostet am 2025-07-14
-
Wie kann ich effizient URL-freundliche Schnecken von Unicode-Zeichenfolgen in PHP erzeugen?eine Funktion für effiziente Slug -Generation Erstellen von Schlägen, vereinfachte Darstellungen von Unicode -Zeichenfolgen, die in URLs verwe...Programmierung Gepostet am 2025-07-14
-
Wie rufe ich die neueste JQuery -Bibliothek von Google APIs ab?abrufen die neueste jQuery -Bibliothek von Google apis Die bereitgestellte jQuery -URL in der Frage ist für Version 1.2.6. Für das Abrufen der...Programmierung Gepostet am 2025-07-14
-
Können mehrere klebrige Elemente in reinem CSS übereinander gestapelt werden?Ist es möglich, in reinem CSS mehrere klebrige Elemente gestapelt zu haben? Hier: https://webthemez.com/demo/sticky-multi-header-scroll/index.ht...Programmierung Gepostet am 2025-07-14
-
Wie kann ich mit Decimal.Parse () Zahlen in exponentieller Notation analysieren?analysieren eine Nummer aus exponentieller Notation beim Versuch, eine in exponentielle Notation ausgedrückte String mit Decimal.parse zu anal...Programmierung Gepostet am 2025-07-14
-
Wie beheben Sie die Diskrepanzen für Modulpfade in Go -Mod mithilfe der Richtlinie Ersetzen?überwinden Modulpfad -Diskrepanz in go mod Wenn GO mod verwendet wird, ist es möglich, auf einen Konflikt zu begegnen, bei dem ein Drittanbiet...Programmierung Gepostet am 2025-07-14















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









