 Titelseite > Programmierung > Erstellen einer RAG-App mit LlamaIndex.ts und Azure OpenAI: Erste Schritte!
Titelseite > Programmierung > Erstellen einer RAG-App mit LlamaIndex.ts und Azure OpenAI: Erste Schritte!
Erstellen einer RAG-App mit LlamaIndex.ts und Azure OpenAI: Erste Schritte!
 Durchsuche:769
Durchsuche:769
Da KI weiterhin die Art und Weise prägt, wie wir arbeiten und mit Technologie interagieren, suchen viele Unternehmen nach Möglichkeiten, ihre eigenen Daten in intelligenten Anwendungen zu nutzen. Wenn Sie Tools wie ChatGPT oder Azure OpenAI verwendet haben, wissen Sie bereits, wie generative KI Prozesse verbessern und Benutzererlebnisse verbessern kann. Für wirklich individuelle und relevante Antworten müssen Ihre Anwendungen jedoch Ihre proprietären Daten integrieren.
Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel und bietet einen strukturierten Ansatz zur Integration des Datenabrufs mit KI-gestützten Antworten. Mit Frameworks wie LlamaIndex können Sie diese Funktion ganz einfach in Ihre Lösungen integrieren und so das volle Potenzial Ihrer Geschäftsdaten ausschöpfen.
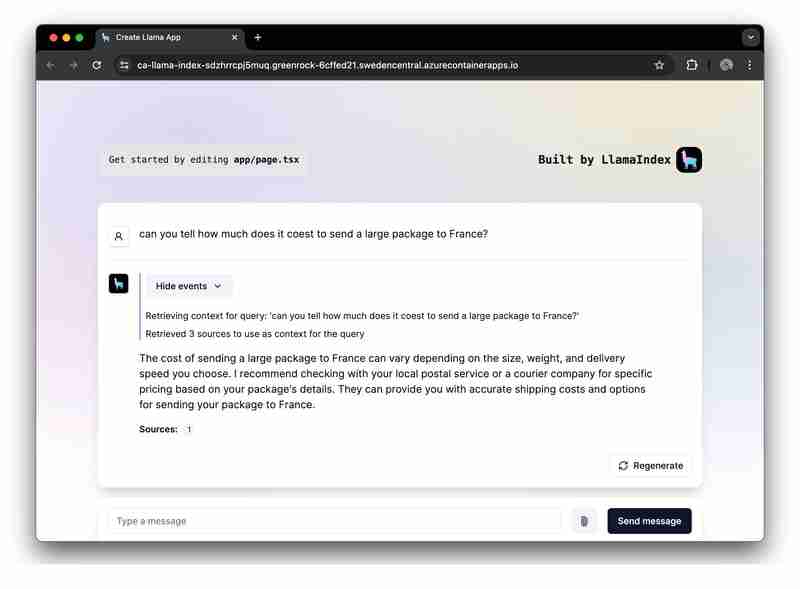
Möchten Sie die App schnell ausführen und erkunden? Klicken Sie hier.
Was ist RAG – Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) ist ein neuronales Netzwerk-Framework, das die KI-Textgenerierung durch die Einbindung einer Retrieval-Komponente verbessert, um auf relevante Informationen zuzugreifen und Ihre eigenen Daten zu integrieren. Es besteht aus zwei Hauptteilen:
- Retriever: Ein Dense-Retriever-Modell (z. B. basierend auf BERT), das einen großen Dokumentenkorpus durchsucht, um relevante Passagen oder Informationen zu einer bestimmten Abfrage zu finden.
- Generator: Ein Sequenz-zu-Sequenz-Modell (z. B. basierend auf BART oder T5), das die Abfrage und den abgerufenen Text als Eingabe verwendet und eine kohärente, kontextuell angereicherte Antwort generiert.
Der Retriever findet relevante Dokumente und der Generator verwendet sie, um genauere und informativere Antworten zu erstellen. Diese Kombination ermöglicht es dem RAG-Modell, externes Wissen effektiv zu nutzen und so die Qualität und Relevanz des generierten Textes zu verbessern.
Wie implementiert LlamaIndex RAG?
Um ein RAG-System mit LlamaIndex zu implementieren, befolgen Sie diese allgemeinen Schritte:
Datenaufnahme:
- Laden Sie Ihre Dokumente mit einem Dokumentladeprogramm wie SimpleDirectoryReader in LlamaIndex.ts, das beim Importieren von Daten aus verschiedenen Quellen wie PDFs, APIs oder SQL-Datenbanken hilft.
- Teilen Sie große Dokumente mit dem SentenceSplitter in kleinere, überschaubare Teile auf.
Indexerstellung:
- Erstellen Sie mit VectorStoreIndex einen Vektorindex dieser Dokumentblöcke, der eine effiziente Ähnlichkeitssuche basierend auf Einbettungen ermöglicht.
- Optional können Sie bei komplexen Datensätzen rekursive Abruftechniken verwenden, um hierarchisch strukturierte Daten zu verwalten und relevante Abschnitte basierend auf Benutzerabfragen abzurufen.
Einrichtung der Abfrage-Engine:
- Konvertieren Sie den Vektorindex mithilfe von „asQueryEngine“ in eine Abfrage-Engine mit Parametern wie „similarityTopK“, um zu definieren, wie viele Top-Dokumente abgerufen werden sollen.
- Für erweiterte Setups erstellen Sie ein Multi-Agenten-System, bei dem jeder Agent für bestimmte Dokumente verantwortlich ist und ein Agent der obersten Ebene den gesamten Abrufprozess koordiniert.
Abruf und Generierung:
- Implementieren Sie die RAG-Pipeline, indem Sie eine Zielfunktion definieren, die relevante Dokumentblöcke basierend auf Benutzerabfragen abruft.
- Verwenden Sie die RetrieverQueryEngine, um den eigentlichen Abruf und die Abfrageverarbeitung durchzuführen, mit optionalen Nachbearbeitungsschritten wie der Neuordnung der abgerufenen Dokumente mithilfe von Tools wie CohereRerank.
Als praktisches Beispiel haben wir eine Beispielanwendung bereitgestellt, um eine vollständige RAG-Implementierung mit Azure OpenAI zu demonstrieren.
Praktische RAG-Beispielanwendung
Wir konzentrieren uns nun auf die Erstellung einer RAG-Anwendung mit LlamaIndex.ts (der TypeScipt-Implementierung von LlamaIndex) und Azure OpenAI und stellen diese als serverlose Web-Apps auf Azure Container Apps bereit.
Anforderungen zum Ausführen des Beispiels
- Azure Developer CLI (azd): Ein Befehlszeilentool zur einfachen Bereitstellung Ihrer gesamten App, einschließlich Backend, Frontend und Datenbanken.
- Azure-Konto: Sie benötigen ein Azure-Konto, um die Anwendung bereitzustellen. Holen Sie sich ein kostenloses Azure-Konto mit etwas Guthaben, um loszulegen.
Das Einstiegsprojekt finden Sie auf GitHub. Wir empfehlen Ihnen, diese Vorlage zu forken, damit Sie sie bei Bedarf frei bearbeiten können:

Architektur auf hohem Niveau
Die Projektanwendung „Erste Schritte“ basiert auf der folgenden Architektur:
- Azure OpenAI: Der KI-Anbieter, der die Abfragen des Benutzers verarbeitet.
- LlamaIndex.ts: Das Framework, das dabei hilft, Inhalte (PDFs) aufzunehmen, zu transformieren und zu vektorisieren und einen Suchindex zu erstellen.
- Azure Container Apps: Die Containerumgebung, in der die serverlose Anwendung gehostet wird.
- Azure Managed Identity: Gewährleistet erstklassige Sicherheit und macht die Handhabung von Anmeldeinformationen und API-Schlüsseln überflüssig.
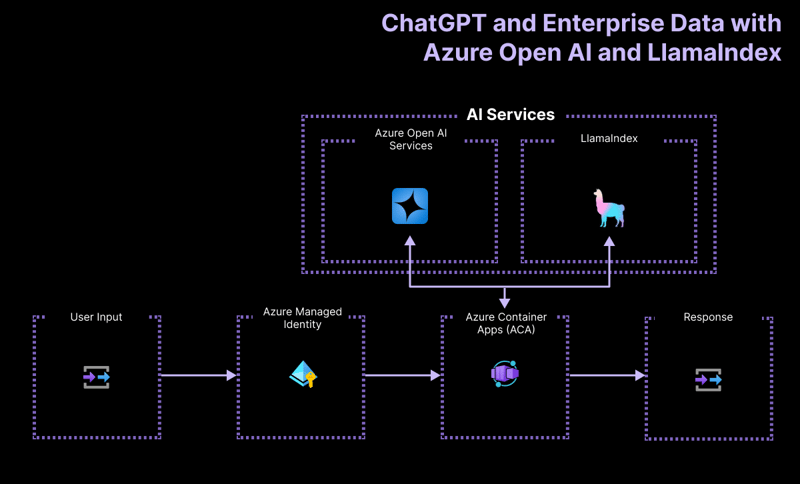
Weitere Informationen zu den bereitgestellten Ressourcen finden Sie im Infra-Ordner, der in allen unseren Beispielen verfügbar ist.
Beispiel-Benutzer-Workflows
Die Beispielanwendung enthält Logik für zwei Workflows:
-
Datenaufnahme: Daten werden abgerufen, vektorisiert und Suchindizes erstellt. Wenn Sie weitere Dateien wie PDFs oder Word-Dateien hinzufügen möchten, sollten Sie diese hier hinzufügen.
npm run generate
Bereitstellung von Eingabeaufforderungsanfragen: Die App empfängt Benutzereingabeaufforderungen, sendet sie an Azure OpenAI und erweitert diese Eingabeaufforderungen mithilfe des Vektorindex als Retriever.
Ausführen der Probe
Bevor Sie das Beispiel ausführen, stellen Sie sicher, dass Sie die erforderlichen Azure-Ressourcen bereitgestellt haben.
Um die GitHub-Vorlage im GitHub-Codespace auszuführen, klicken Sie einfach auf
Melden Sie sich in Ihrer Codespaces-Instanz von Ihrem Terminal aus bei Ihrem Azure-Konto an:
azd auth login
Bereitstellen, Verpacken und Bereitstellen der Beispielanwendung in Azure mit einem einzigen Befehl:
azd up
Um die Anwendung lokal auszuführen und auszuprobieren, installieren Sie die npm-Abhängigkeiten und führen Sie die App aus:
npm install npm run dev
Die App wird auf Port 3000 in Ihrer Codespaces-Instanz oder unter http://localhost:3000 in Ihrem Browser ausgeführt.
Abschluss
Diese Anleitung zeigt, wie man eine serverlose RAG-Anwendung (Retrieval-Augmented Generation) mit LlamaIndex.ts und Azure OpenAI erstellt, die auf Microsoft Azure bereitgestellt wird. Wenn Sie diesem Leitfaden folgen, können Sie die Infrastruktur von Azure und die Funktionen von LlamaIndex nutzen, um leistungsstarke KI-Anwendungen zu erstellen, die kontextuell angereicherte Antworten basierend auf Ihren Daten bereitstellen.
Wir sind gespannt, was Sie mit dieser Einstiegsanwendung erstellen. Fühlen Sie sich frei, es zu forken und das GitHub-Repository zu liken, um die neuesten Updates und Funktionen zu erhalten.
-
 Enthülle, ob mySQL_REAL_ESCAPE_STRING eine SQL -Injektion verhindern kannEinschränkungen von mysql_real_escape_string Die MySQL_REAL_ESCAPE_STRING -Funktion in PHP wurde dafür kritisiert, dass sie nicht umfassende S...Programmierung Gepostet am 2025-04-12
Enthülle, ob mySQL_REAL_ESCAPE_STRING eine SQL -Injektion verhindern kannEinschränkungen von mysql_real_escape_string Die MySQL_REAL_ESCAPE_STRING -Funktion in PHP wurde dafür kritisiert, dass sie nicht umfassende S...Programmierung Gepostet am 2025-04-12 -
Wie kann ich mehrere Benutzertypen (Schüler, Lehrer und Administratoren) in ihre jeweiligen Aktivitäten in einer Firebase -App umleiten?rot: Wie man mehrere Benutzertypen zu jeweiligen Aktivitäten umleitet Login. Der aktuelle Code verwaltet die Umleitung für zwei Benutzertypen erf...Programmierung Gepostet am 2025-04-12
-
Können Sie CSS verwenden, um die Konsolenausgabe in Chrom und Firefox zu färben?Farben in JavaScript console Ist es möglich, Chromes Konsole zu verwenden, um farbigen Text wie rot für Fehler, orange für Kriege und grün für...Programmierung Gepostet am 2025-04-12
-
Python erstellt effizient XML -Dateien: ElementTree, Celementtree oder LXML?wie man XML -Dateien in Python erstellen, um XML -Dateien in Python zu erstellen. 2.5 ist eine unkomplizierte und effiziente Wahl. It includes...Programmierung Gepostet am 2025-04-12
-
Wie kann ich Kompilierungsoptimierungen im Go -Compiler anpassen?Anpassung von Kompilierungsoptimierungen in Go Compiler Der Standardkompilierungsprozess in Go folgt einer spezifischen Optimierungsstrategie....Programmierung Gepostet am 2025-04-12
-
Wie entferte ich anonyme JavaScript -Ereignishandler sauber?entfernen anonymer Ereignis -Hörer Hinzufügen von anonymen Ereignishörern zu Elementen bieten Flexibilität und Einfachheit, aber wenn es Zeit is...Programmierung Gepostet am 2025-04-12
-
Warum gibt es Streifen in meinem linearen Gradientenhintergrund und wie kann ich sie beheben?die Hintergrundstreifen aus linearem Gradienten Beim Einsatz der Linear-Gradient-Eigenschaft für einen Hintergrund können Sie auffällige Strei...Programmierung Gepostet am 2025-04-12
-
Wie kann ich Werte von zwei gleichen Arrays in PHP synchron iterieren und drucken?synchron iterierend und drucken Werte aus zwei Arrays derselben Größe beim Erstellen einer Selectbox unter Verwendung von zwei Arrays gleicher G...Programmierung Gepostet am 2025-04-12
-
Warum führt PHPs DateTime :: Modify ('+1 Monat') unerwartete Ergebnisse zu?Monate mit PHP DATETIME: Aufdeckung des beabsichtigten Verhaltens Wenn Sie mit der DateTime -Klasse von PHP die erwarteten Ergebnisse hinzufüg...Programmierung Gepostet am 2025-04-12
-
Wie kann ich in Java Eingabeaufforderungsbefehle, einschließlich Verzeichnisänderungen, ausführen?Lösung: , um Eingabeaufforderung und Änderungsverzeichnisse mit Java auszuführen, nutzen A -ProcessBuilder. Dieser Ansatz ermöglicht es Ihnen...Programmierung Gepostet am 2025-04-12
-
Python Read CSV -Datei UnicodEdeCodeError Ultimate Lösungunicode dekodieren Fehler in der CSV-Datei Reading Wenn versucht wird, eine CSV-Datei mit dem integrierten CSV-Modul zu lesen, können Sie eine...Programmierung Gepostet am 2025-04-12
-
Wie kann ich bei der Erstellung von SQL -Abfragen in Go sicher Text und Werte verkettet?concattenieren Text und Werte in Go SQL -Abfragen Bei der Erstellung eines Text -SQL -Abfrages in GO, es gibt bestimmte Syntax -Regeln, die be...Programmierung Gepostet am 2025-04-12
-
Wie extrahieren Sie ein zufälliges Element aus einem Array in PHP?zufällige Auswahl aus einem Array In PHP kann ein zufälliger Element aus einem Array mit Leichtigkeit erreicht werden. Betrachten Sie das folgen...Programmierung Gepostet am 2025-04-12
-
Wie kann man eine generische Hash -Funktion für Tupel in ungeordneten Sammlungen implementieren?generische Hash -Funktion für Tupel in nicht ordnungsgemäßen Sammlungen Die std :: unbestrahlte_Map und std :: unconded_set Container bieten e...Programmierung Gepostet am 2025-04-12
-
Warum zeigt keine Firefox -Bilder mithilfe der CSS `Content` -Eigenschaft an?Bilder mit Inhalts -URL in Firefox Es wurde ein Problem aufgenommen, an dem bestimmte Browser, speziell Firefox, nicht in den Verweisen der In...Programmierung Gepostet am 2025-04-12















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









