
Überbrücken Sie KI/ML mit Ihrer Adaptive Analytics-Lösung
 Durchsuche:141
Durchsuche:141
In der heutigen Datenlandschaft stehen Unternehmen vor einer Reihe unterschiedlicher Herausforderungen. Eine davon besteht darin, Analysen auf der Grundlage einer einheitlichen und harmonisierten Datenschicht durchzuführen, die allen Verbrauchern zur Verfügung steht. Eine Ebene, die unabhängig vom verwendeten Dialekt oder Werkzeug dieselben Antworten auf dieselben Fragen liefern kann.
Die InterSystems IRIS Data Platform beantwortet diese Frage mit einem Add-on von Adaptive Analytics, das diese einheitliche semantische Ebene bereitstellen kann. In DevCommunity gibt es viele Artikel über die Verwendung über BI-Tools. In diesem Artikel geht es darum, wie man es mit KI nutzt und wie man einige Erkenntnisse zurückgewinnt.
Gehen wir Schritt für Schritt vor...
Was ist Adaptive Analytics?
Eine Definition finden Sie leicht auf der Website der Entwickler-Community
Kurz gesagt: Es kann Daten in strukturierter und harmonisierter Form an verschiedene Tools Ihrer Wahl zur weiteren Nutzung und Analyse liefern. Es liefert dieselben Datenstrukturen an verschiedene BI-Tools. Aber... es kann auch dieselben Datenstrukturen an Ihre KI/ML-Tools liefern!
Adaptive Analytics verfügt über eine zusätzliche Komponente namens AI-Link, die diese Brücke von KI zu BI schlägt.
Was genau ist AI-Link?
Es handelt sich um eine Python-Komponente, die eine programmatische Interaktion mit der semantischen Ebene ermöglichen soll, um wichtige Phasen des maschinellen Lernworkflows (ML) zu optimieren (z. B. Feature-Engineering).
Mit AI-Link können Sie:
- Greifen Sie programmgesteuert auf Funktionen Ihres analytischen Datenmodells zu;
- Abfragen durchführen, Dimensionen und Kennzahlen erkunden;
- Feed-ML-Pipelines; ... und liefern Ergebnisse zurück an Ihre semantische Ebene, damit sie von anderen erneut genutzt werden können (z. B. über Tableau oder Excel).
Da es sich um eine Python-Bibliothek handelt, kann sie in jeder Python-Umgebung verwendet werden. Einschließlich Notizbücher.
Und in diesem Artikel gebe ich ein einfaches Beispiel für die Erreichung einer Adaptive Analytics-Lösung aus Jupyter Notebook mithilfe von AI-Link.
Hier ist das Git-Repository, das das vollständige Notebook als Beispiel enthält: https://github.com/v23ent/aa-hands-on
Voraussetzungen
Für die weiteren Schritte wird davon ausgegangen, dass die folgenden Voraussetzungen erfüllt sind:
- Adaptive Analytics-Lösung in Betrieb (mit IRIS Data Platform als Data Warehouse)
- Jupyter Notebook läuft
- Verbindung zwischen 1. und 2. kann hergestellt werden
Schritt 1: Einrichtung
Zuerst installieren wir die benötigten Komponenten in unserer Umgebung. Dadurch werden einige Pakete heruntergeladen, die für weitere Schritte erforderlich sind.
'atscale' – das ist unser Hauptpaket zum Verbinden
'Prophet' – Paket, das wir für Vorhersagen benötigen
pip install atscale prophet
Dann müssen wir Schlüsselklassen importieren, die einige Schlüsselkonzepte unserer semantischen Ebene darstellen.
Client – Klasse, die wir verwenden, um eine Verbindung zu Adaptive Analytics herzustellen;
Projekt – Klasse zur Darstellung von Projekten innerhalb von Adaptive Analytics;
DataModel – Klasse, die unseren virtuellen Würfel darstellt;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
Schritt 2: Verbindung
Jetzt sollten wir bereit sein, eine Verbindung zu unserer Datenquelle herzustellen.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Fahren Sie fort und geben Sie die Verbindungsdetails Ihrer Adaptive Analytics-Instanz an. Sobald Sie nach der Organisation gefragt werden, antworten Sie im Dialogfeld und geben Sie dann bitte Ihr Passwort aus der AtScale-Instanz ein.
Bei bestehender Verbindung müssen Sie dann Ihr Projekt aus der Liste der auf dem Server veröffentlichten Projekte auswählen. Sie erhalten die Liste der Projekte als interaktive Eingabeaufforderung und die Antwort sollte die ganzzahlige ID des Projekts sein. Und dann wird das Datenmodell automatisch ausgewählt, wenn es das einzige ist.
project = client.select_project() data_model = project.select_data_model()
Schritt 3: Erkunden Sie Ihren Datensatz
Es gibt eine Reihe von Methoden, die von AtScale in der AI-Link-Komponentenbibliothek vorbereitet wurden. Sie ermöglichen es, den vorhandenen Datenkatalog zu durchsuchen, Daten abzufragen und sogar einige Daten wieder aufzunehmen. Die AtScale-Dokumentation enthält eine ausführliche API-Referenz, die alles beschreibt, was verfügbar ist.
Sehen wir uns zunächst an, was unser Datensatz ist, indem wir einige Methoden von data_model aufrufen:
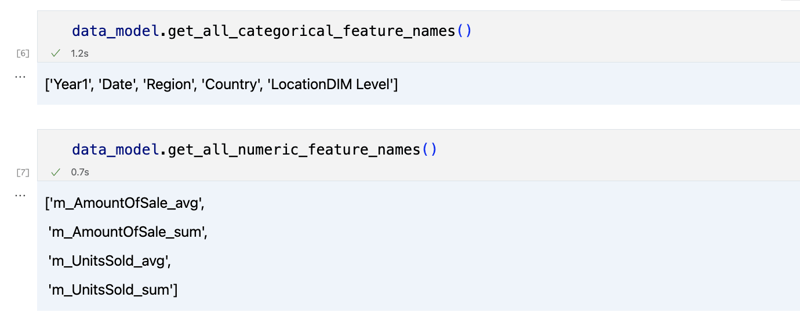
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
Die Ausgabe sollte etwa so aussehen
Sobald wir uns ein wenig umgesehen haben, können wir die tatsächlichen Daten, an denen wir interessiert sind, mit der Methode „get_data“ abfragen. Es wird ein Pandas-DataFrame zurückgegeben, der die Abfrageergebnisse enthält.
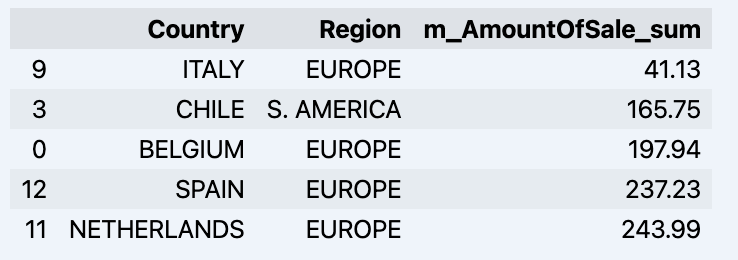
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
Hier wird Ihr Datadrame angezeigt:
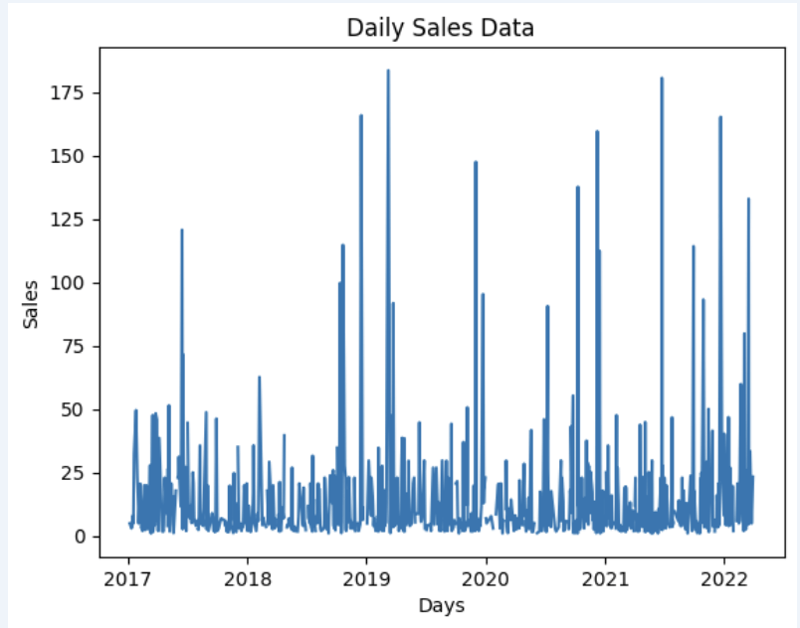
Lassen Sie uns einen Datensatz vorbereiten und ihn schnell in der Grafik anzeigen
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
Ausgabe:
Schritt 4: Vorhersage
Der nächste Schritt wäre, tatsächlich einen Nutzen aus der AI-Link-Brücke zu ziehen – machen wir eine einfache Vorhersage!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Wir erhalten hier 2 verschiedene Datensätze: um unser Modell zu trainieren und zu testen.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
Und dann erstellen wir einen weiteren Datenrahmen, um unsere Vorhersage aufzunehmen und sie im Diagramm anzuzeigen
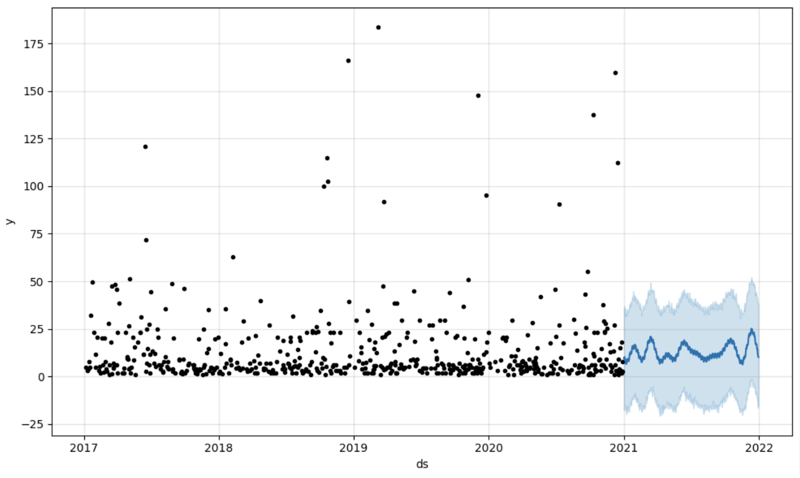
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
Ausgabe:
Schritt 5: Zurückschreiben
Sobald wir unsere Vorhersage getroffen haben, können wir sie zurück in das Data Warehouse stellen und unserem semantischen Modell ein Aggregat hinzufügen, um sie für andere Verbraucher widerzuspiegeln. Die Vorhersage wäre über jedes andere BI-Tool für BI-Analysten und Geschäftsanwender verfügbar.
Die Vorhersage selbst wird in unserem Data Warehouse abgelegt und dort gespeichert.
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
Flosse
Das ist es!
Viel Glück mit Ihren Vorhersagen!
-
 Der Unterschied zwischen PHP- und C ++ - Funktion ÜberlastverarbeitungPHP -Funktion Überladen: Entschlüsseln des Enigma aus einer C Perspektive als erfahrener C -Entwickler, der sich in den Bereich des PHP wagt, kö...Programmierung Gepostet am 2025-07-06
Der Unterschied zwischen PHP- und C ++ - Funktion ÜberlastverarbeitungPHP -Funktion Überladen: Entschlüsseln des Enigma aus einer C Perspektive als erfahrener C -Entwickler, der sich in den Bereich des PHP wagt, kö...Programmierung Gepostet am 2025-07-06 -
Warum können Java nicht generische Arrays erstellen?generic Array Creation error Frage: , wenn wir versuchen, eine Array von generischen Klassen zu erstellen. ArrayList [2]; public static A...Programmierung Gepostet am 2025-07-06
-
Können Templatparameter in C ++ 20 -Konstalfunktion von Funktionsparametern abhängen?konstvale Funktionen und Vorlagenparameter, die von Funktionsargumenten abhängen In c 17 kompile-time. c 20 canteval functions c 20 führ...Programmierung Gepostet am 2025-07-06
-
Wie wiederhole ich Stringzeichen für die Einklingel in C#effizient?Wenn Sie nur das gleiche Zeichen wiederholen möchten, können Sie den String -Konstruktor verwenden, der ein Zeichen akzeptiert, und die Anzahl ...Programmierung Gepostet am 2025-07-06
-
Warum gibt es Streifen in meinem linearen Gradientenhintergrund und wie kann ich sie beheben?die Hintergrundstreifen aus linearem Gradienten Beim Einsatz der Linear-Gradient-Eigenschaft für einen Hintergrund können Sie auffällige Strei...Programmierung Gepostet am 2025-07-06
-
Können Sie CSS verwenden, um die Konsolenausgabe in Chrom und Firefox zu färben?Farben in JavaScript console Ist es möglich, Chromes Konsole zu verwenden, um farbigen Text wie rot für Fehler, orange für Kriege und grün für...Programmierung Gepostet am 2025-07-06
-
Python Metaclass -Arbeitsprinzip und Klassenerstellung und -anpassungWas sind Metaklassen in Python? Metaklassen sind dafür verantwortlich, Klassenobjekte in Python zu erstellen. So wie Klassen Instanzen erstellen...Programmierung Gepostet am 2025-07-06
-
Muss ich vor dem Programm Exit explizit Heap -Zuordnungen in C ++ löschen?explizites Löschen in C trotz des Programms exit Wenn Sie mit dynamischer Speicherzuweisung in C arbeiten, fragen sich Entwickler oft, ob es n...Programmierung Gepostet am 2025-07-06
-
-
Wie setze ich Tasten in JavaScript -Objekten dynamisch ein?wie man einen dynamischen Schlüssel für eine JavaScript -Objektvariable erstellt beim Versuch, einen dynamischen Schlüssel für ein JavaScript -O...Programmierung Gepostet am 2025-07-06
-
Wie beheben Sie die Diskrepanzen für Modulpfade in Go -Mod mithilfe der Richtlinie Ersetzen?überwinden Modulpfad -Diskrepanz in go mod Wenn GO mod verwendet wird, ist es möglich, auf einen Konflikt zu begegnen, bei dem ein Drittanbiet...Programmierung Gepostet am 2025-07-06
-
Wie implementieren Sie benutzerdefinierte Ereignisse mit dem Beobachtermuster in Java?erstellen benutzerdefinierte Ereignisse in java benutzerdefinierte Ereignisse sind in vielen Programmierszenarien unverzichtbar und ermöglichen ...Programmierung Gepostet am 2025-07-06
-
Warum bekomme ich in meiner Silverlight Linq -Abfrage einen Fehler "konnte keine Implementierung des Abfragemuster -Fehlers finden?"Abfragemuster -Implementierung Abwesenheit: Auflösung "konnte nicht" fehler In einer Silberlight -Anwendung, ein Versuch, eine Daten...Programmierung Gepostet am 2025-07-06
-
Wie kann ich mit dem Python -Verständnis Wörterbücher effizient erstellen?Python Dictionary Verständnis In Python bieten Dictionary -Verständnisse eine kurze Möglichkeit, neue Wörterbücher zu generieren. Während sie de...Programmierung Gepostet am 2025-07-06
-
Wie kann ich mit Decimal.Parse () Zahlen in exponentieller Notation analysieren?analysieren eine Nummer aus exponentieller Notation beim Versuch, eine in exponentielle Notation ausgedrückte String mit Decimal.parse zu anal...Programmierung Gepostet am 2025-07-06















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









