
I made a token count check app using Streamlit in Snowflake (SiS)
 Browse:227
Browse:227
Introduction
Hello, I'm a Sales Engineer at Snowflake. I'd like to share some of my experiences and experiments with you through various posts. In this article, I'll show you how to create an app using Streamlit in Snowflake to check token counts and estimate costs for Cortex LLM.
Note: This post represents my personal views and not those of Snowflake.
What is Streamlit in Snowflake (SiS)?
Streamlit is a Python library that allows you to create web UIs with simple Python code, eliminating the need for HTML/CSS/JavaScript. You can see examples in the App Gallery.
Streamlit in Snowflake enables you to develop and run Streamlit web apps directly on Snowflake. It's easy to use with just a Snowflake account and great for integrating Snowflake table data into web apps.
About Streamlit in Snowflake (Official Snowflake Documentation)
What is Snowflake Cortex?
Snowflake Cortex is a suite of generative AI features in Snowflake. Cortex LLM allows you to call large language models running on Snowflake using simple functions in SQL or Python.
Large Language Model (LLM) Functions (Snowflake Cortex) (Official Snowflake Documentation)
Feature Overview
Image
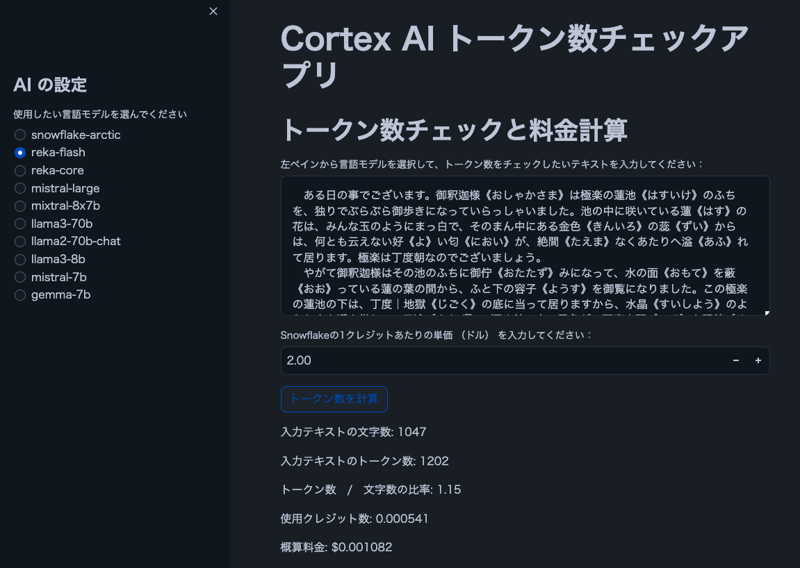
Note: The text in the image is from "The Spider's Thread" by Ryunosuke Akutagawa.
Features
- Users can select a Cortex LLM model
- Display character and token counts for user-input text
- Show the ratio of tokens to characters
- Calculate estimated cost based on Snowflake credit pricing
Note: Cortex LLM pricing table (PDF)
Prerequisites
- Snowflake account with Cortex LLM access
- snowflake-ml-python 1.1.2 or later
Note: Cortex LLM region availability (Official Snowflake Documentation)
Source Code
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
Conclusion
This app makes it easier to estimate costs for LLM workloads, especially when dealing with languages like Japanese where there's often a gap between character count and token count. I hope you find it useful!
Announcements
Snowflake What's New Updates on X
I'm sharing Snowflake's What's New updates on X. Please feel free to follow if you're interested!
English Version
Snowflake What's New Bot (English Version)
https://x.com/snow_new_en
Japanese Version
Snowflake What's New Bot (Japanese Version)
https://x.com/snow_new_jp
Change History
(20240914) Initial post
Original Japanese Article
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
-
 How do I combine two associative arrays in PHP while preserving unique IDs and handling duplicate names?Combining Associative Arrays in PHPIn PHP, combining two associative arrays into a single array is a common task. Consider the following request:Descr...Programming Published on 2024-12-29
How do I combine two associative arrays in PHP while preserving unique IDs and handling duplicate names?Combining Associative Arrays in PHPIn PHP, combining two associative arrays into a single array is a common task. Consider the following request:Descr...Programming Published on 2024-12-29 -
How Can I Find Users with Today\'s Birthdays Using MySQL?How to Identify Users with Today's Birthdays Using MySQLDetermining if today is a user's birthday using MySQL involves finding all rows where ...Programming Published on 2024-12-29
-
Beyond `if` Statements: Where Else Can a Type with an Explicit `bool` Conversion Be Used Without Casting?Contextual Conversion to bool Allowed Without a CastYour class defines an explicit conversion to bool, enabling you to use its instance 't' di...Programming Published on 2024-12-29
-
How to Check for NaN (Not a Number) in Python?Checking for NaN (Not a Number)In Python, NaN (not a number) is represented by float('nan'). It's used to represent values that cannot be ...Programming Published on 2024-12-29
-
Using WebSockets in Go for Real-Time CommunicationBuilding apps that require real-time updates—like chat applications, live notifications, or collaborative tools—requires a communication method faster...Programming Published on 2024-12-29
-
What Happened to Column Offsetting in Bootstrap 4 Beta?Bootstrap 4 Beta: The Removal and Restoration of Column OffsettingBootstrap 4, in its Beta 1 release, introduced significant changes to the way column...Programming Published on 2024-12-29
-
How to Fix \"ImproperlyConfigured: Error loading MySQLdb module\" in Django on macOS?MySQL Improperly Configured: The Problem with Relative PathsWhen running python manage.py runserver in Django, you may encounter the following error:I...Programming Published on 2024-12-29
-
How Can I Conditionally Apply Class Attributes in React?Conditionally Apply Class Attributes in ReactIn React, it's common to show or hide elements based on props passed from parent components. To achie...Programming Published on 2024-12-28
-
How to Execute System Commands and Interact with Other Applications in Java?Running Processes in JavaIn Java, the ability to launch processes is a crucial feature for executing system commands and interacting with other applic...Programming Published on 2024-12-28
-
How Can I Create Multi-Line String Literals in C++?Multi-Line String Literals in C In C , defining a multi-line string literal is not as straightforward as it is in some other languages like Perl. Ho...Programming Published on 2024-12-28
-
How Can I Accurately Pivot Data with Distinct Records to Avoid Losing Information?Pivoting Distinct Records EffectivelyPivot queries play a crucial role in transforming data into a tabular format, enabling easy data analysis. Howeve...Programming Published on 2024-12-27
-
Why Do C and C++ Ignore Array Lengths in Function Signatures?Passing Arrays to Functions in C and C Question:Why do C and C compilers allow array length declarations in function signatures, such as int dis(ch...Programming Published on 2024-12-26
-
How Can I Remove Accents in MySQL to Improve Autocomplete Search?Removing Accents in MySQL for Efficient Auto-Complete SearchWhen managing a large database of place names, it's crucial to ensure accurate and eff...Programming Published on 2024-12-26
-
How to Implement Composite Foreign Keys in MySQL?Implementing Composite Foreign Keys in SQLOne common database design involves establishing relationships between tables using composite keys. A compos...Programming Published on 2024-12-26
-
Why Are My JComponents Hidden Behind a Background Image in Java?Debugging JComponents Hidden by Background ImageWhen working with JComponents, such as JLabels, in a Java application, it's essential to ensure pr...Programming Published on 2024-12-26















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









