
What is faster and cheaper to convert files in AWS: Polar or Pandas?
 Browse:550
Browse:550
Both offer a wide range of tools and advantages that may make us doubt which of the two to choose at some point. It is not about changing all the company's processes so that they start using Polars or a “death” to Pandas (this is not going to happen in the immediate future). It is about knowing other tools that can help us reduce costs and time in processes, obtaining the same or better results.
When we use cloud services we prioritize certain factors, including their cost. The services I use for this process are AWS Lambda with the Python 3.10 runtime and S3 to store the raw file and the parquet converted file.
The intention is to obtain a CSV file as raw data and process it with pandas and polar with the intention of verifying which of these two libraries offers us better optimization of resources such as memory and the weight of the resulting file.
Pandas
It is a Python library specialized in data manipulation and analysis, it is written in C and its initial release was in 2008.
*Polars *
It is a Python and Rust library specialized in data manipulation and analysis that allows parallel processes and is written mostly in Rust and was released in 2022.
The architecture of the process:
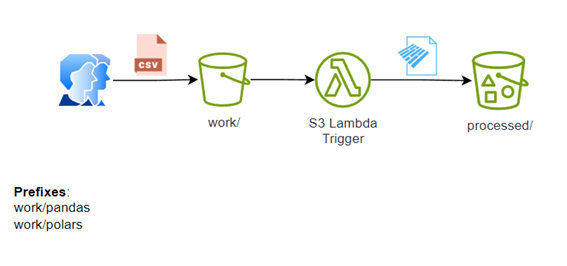
The project is somewhat simple as shown in the architecture: The user deposits a CSV file in work/pandas or work/porlas and automatically starts the s3 trigger to process the file to convert it into parquet and deposit it in processed.
In this small project use two lambdas with the following configuration:
Memory: 2 GB
Ephemeral memory: 2 GB
Life time: 600 seconds
Requirements
Lambda with pandas: Pandas, Numpy and Pyarrow
Lambda with polars: Polars
The dataset used for the comparison is available on kaggle under the name “Rotten Tomatoes Movie Reviews – 1.44M rows” or can be downloaded from here.
The full repository is available on GitHub and can be cloned here.
Size or Weight
The lambda that Pandas uses requires two more plugins to create a parquet file, in this case it is PyArrow and a specific version of numpy for the version of Pandas that I was using. As a result, we obtained a lambda with a weight or size of 74.4 MB, something very close to the limit that AWS allows us for the weight of the lambda.
The lambda with Polars does not require another plugin like PyArrow which makes life simpler and reduces the size of the lambda to less than half. As a result, our lambda has a weight or size of 30.6 MB compared to the first, giving us room to install other dependencies that we may need for our transformation process.
Performance
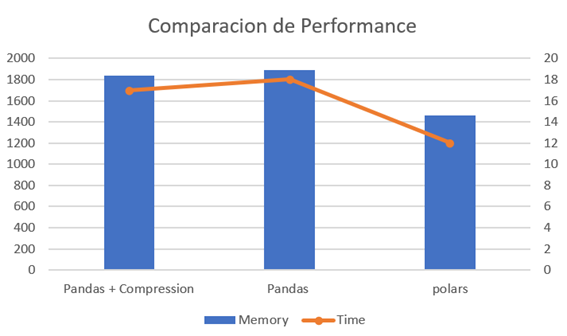
The lambda with Pandas was optimized to use compression after the first version, however, its behavior was also analyzed.
Pandas
It took 18 seconds to process the dataset and used 1894 MB of memory to process the CSV file and generate a Parquet file compared to the other versions, it was the one that used the most time and resources.
Pandas Compression
Adding a line of code allowed us to improve a little compared to the previous version (Pandas), it took 17 seconds to process the dataset and used 1837 MB, which does not represent a significant improvement in processing and computational time, but in size. of the resulting file.
Polars
It took 12 seconds to process the same dataset and I used only 1462 MB, compared to the previous two it represents a time saving of 44.44% and lower memory consumption.
Output file size
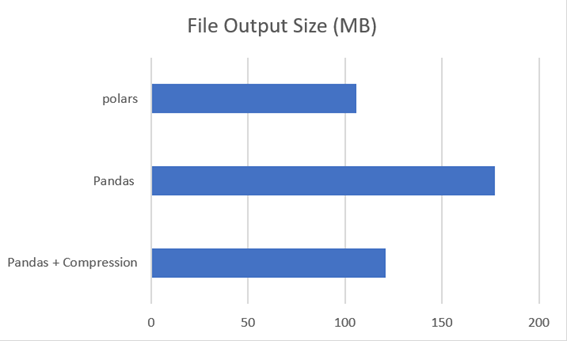
Pandas
The lambda in which a compression process was not established generated a parquet file of 177.4 MB.
Pandas Compression
When configuring compression in the lambda I do not generate a 121.1 MB parquet file. One small line or option helped us reduce the file size by 31.74%. Considering that it is not a significant code change, it is a very good option.
Polars
Polars generated a 105.8 MB file that, purchased with the first version of Pandas, represents a saving of 40.36% and 12.63% against the Pandas version with compression.
Conclusion
It is not necessary to change all the internal processes that use Pandas so that they now use Polars, however, it is important to consider that if we are talking about thousands or millions of lambda executions, using Polars will help us not only with the deployment time but will also help us to have a lower cost due to the time-based charging that AWS makes for Serverless services such as Lambda.
Likewise, when we translate that 40.36% into millions of files we are talking about GBs or TBs, something that would have a significant impact within a Datalake or Dataware house or even in a cold file storage.
The reduction with Polars would not only be limited to these two factors, because it would greatly affect the output of data and/or objects from AWS because it is a service that does have a cost.
-
 How Can I UNION Database Tables with Different Numbers of Columns?Combined tables with different columns] Can encounter challenges when trying to merge database tables with different columns. A straightforward way i...Programming Posted on 2025-04-03
How Can I UNION Database Tables with Different Numbers of Columns?Combined tables with different columns] Can encounter challenges when trying to merge database tables with different columns. A straightforward way i...Programming Posted on 2025-04-03 -
How Can I Execute Multiple SQL Statements in a Single Query Using Node-MySQL?Multi-Statement Query Support in Node-MySQLIn Node.js, the question arises when executing multiple SQL statements in a single query using the node-mys...Programming Posted on 2025-04-03
-
How Can I Efficiently Read a Large File in Reverse Order Using Python?Reading a File in Reverse Order in PythonIf you're working with a large file and need to read its contents from the last line to the first, Python...Programming Posted on 2025-04-03
-
How to upload files with additional parameters using java.net.URLConnection and multipart/form-data encoding?Uploading Files with HTTP RequestsTo upload files to an HTTP server while also submitting additional parameters, java.net.URLConnection and multipart/...Programming Posted on 2025-04-03
-
How to Parse Numbers in Exponential Notation Using Decimal.Parse()?Parsing a Number from Exponential NotationWhen attempting to parse a string expressed in exponential notation using Decimal.Parse("1.2345E-02&quo...Programming Posted on 2025-04-03
-
How to Fix \"mysql_config not found\" Error When Installing MySQL-python on Ubuntu/Linux?MySQL-python Installation Error: "mysql_config not found"Attempting to install MySQL-python on Ubuntu/Linux Box may encounter an error messa...Programming Posted on 2025-04-03
-
How to Correctly Use LIKE Queries with PDO Parameters?Using LIKE Queries in PDOWhen trying to implement LIKE queries in PDO, you may encounter issues like the one described in the query below:$query = &qu...Programming Posted on 2025-04-03
-
How to Parse JSON Arrays in Go Using the `json` Package?Parsing JSON Arrays in Go with the JSON PackageProblem: How can you parse a JSON string representing an array in Go using the json package?Code Exampl...Programming Posted on 2025-04-03
-
How to Redirect Multiple User Types (Students, Teachers, and Admins) to Their Respective Activities in a Firebase App?Red: How to Redirect Multiple User Types to Respective ActivitiesUnderstanding the ProblemIn a Firebase-based voting app with three distinct user type...Programming Posted on 2025-04-03
-
Eval() vs. ast.literal_eval(): Which Python Function Is Safer for User Input?Weighing eval() and ast.literal_eval() in Python SecurityWhen handling user input, it's imperative to prioritize security. eval(), a powerful Pyth...Programming Posted on 2025-04-03
-
Do I Need to Explicitly Delete Heap Allocations in C++ Before Program Exit?Explicit Deletion in C Despite Program ExitWhen working with dynamic memory allocation in C , developers often wonder if it's necessary to manu...Programming Posted on 2025-04-03
-
How Can I Execute Command Prompt Commands, Including Directory Changes, in Java?Execute Command Prompt Commands in JavaProblem:Running command prompt commands through Java can be challenging. Although you may find code snippets th...Programming Posted on 2025-04-03
-
How to Implement a Generic Hash Function for Tuples in Unordered Collections?Generic Hash Function for Tuples in Unordered CollectionsThe std::unordered_map and std::unordered_set containers provide efficient lookup and inserti...Programming Posted on 2025-04-03
-
How to Check if an Object Has a Specific Attribute in Python?Method to Determine Object Attribute ExistenceThis inquiry seeks a method to verify the presence of a specific attribute within an object. Consider th...Programming Posted on 2025-04-03
-
Why Isn\'t My CSS Background Image Appearing?Troubleshoot: CSS Background Image Not AppearingYou've encountered an issue where your background image fails to load despite following tutorial i...Programming Posted on 2025-04-03















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









