
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit is a Python library that makes it easy to create and share custom web applications for machine learning and data science projects.
numpy is a fundamental Python library for numerical computing. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)Input values are retrieved from the input form created by Stremlit, and categorical variables are encoded using the same rules as when the model was created. Note that the order of each data must also be the same as when the model was created. If the order is different, an error will occur when executing a forecast using the model.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" is the file where the previously saved model is stored. This file contains a trained RandomForestClassifier in binary format. Running this code loads the model into clf, allowing you to use it for predictions and evaluations on new data.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): Uses the trained model to predict the class for the new encoded input data, storing the result in prediction.
clf.predict_proba(input_encoded_df): Calculates the probability for each class, storing the results in prediction_proba.
You can publish your developed application on the Internet by accessing the Stremlit Community Cloud (https://streamlit.io/cloud) and specifying the URL of the GitHub repository.

Artwork by @allison_horst (https://github.com/allisonhorst)
The model is trained using the Palmer Penguins dataset, a widely recognized dataset for practicing machine learning techniques. This dataset provides information on three penguin species (Adelie, Chinstrap, and Gentoo) from the Palmer Archipelago in Antarctica. Key features include:
This dataset is sourced from Kaggle, and it can be accessed here. The diversity in features makes it an excellent choice for building a classification model and understanding the importance of each feature in species prediction.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} Browse:420
Browse:420
A machine learning model is essentially a set of rules or mechanisms used to make predictions or find patterns in data. To put it super simply (and without fear of oversimplification), a trendline calculated using the least squares method in Excel is also a model. However, models used in real applications are not so simple—they often involve more complex equations and algorithms, not just simple equations.
In this post, I’m going to start by building a very simple machine learning model and releasing it as a very simple web app to get a feel for the process.
Here, I’ll focus only on the process, not the ML model itself. Alsom I’ll use Streamlit and Streamlit Community Cloud to easily release Python web applications.
Using scikit-learn, a popular Python library for machine learning, you can quickly train data and create a model with just a few lines of code for simple tasks. The model can then be saved as a reusable file with joblib. This saved model can be imported/load like a regular Python library in a web application, allowing the app to make predictions using the trained model!
App URL: https://yh-machine-learning.streamlit.app/
GitHub: https://github.com/yoshan0921/yh-machine-learning.git
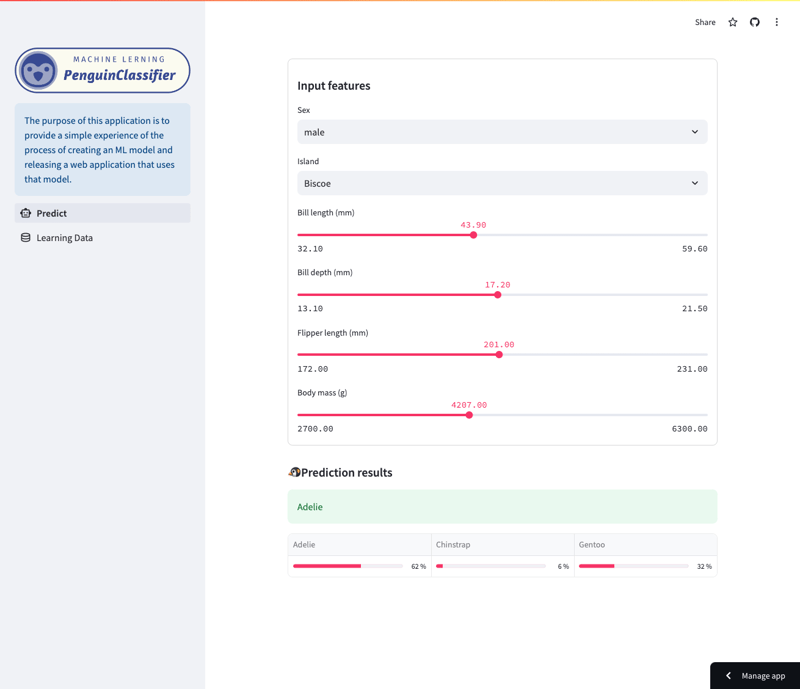
This app allows you to examine predictions made by a random forest model trained on the Palmer Penguins dataset. (See the end of this article for more details on the training data.)
Specifically, the model predicts penguin species based on a variety of features, including species, island, beak length, flipper length, body size, and sex. Users can navigate the app to see how different features affect the model's predictions.
Prediction Screen
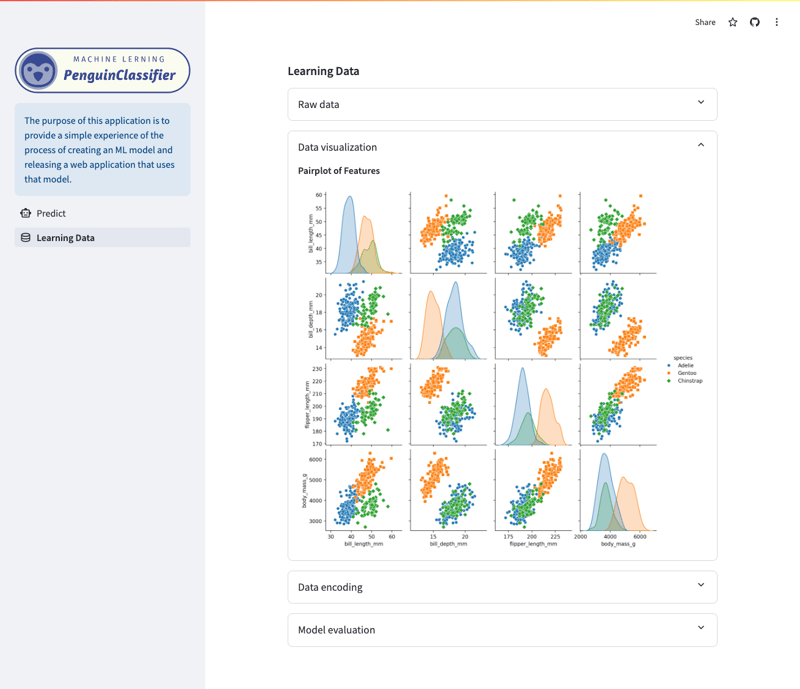
Learning Data/Visualization Screen
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas is a Python library specialized in data manipulation and analysis. It supports data loading, preprocessing, and structuring using DataFrames, preparing data for machine learning models.
sklearn is a comprehensive Python library for machine learning that provides tools for training and evaluating. In this post, I will build a model using a learning method called Random Forest.
joblib is a Python library that helps save and load Python objects, like machine learning models, in a very efficient way.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
Load the dataset (training data) and separate it into features (X) and target variables (y).
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
The categorical variables are converted into a numerical format using one-hot encoding (X_encoded). For example, if “island” contains the categories “Biscoe”, “Dream”, and “Torgersen”, a new column is created for each (island_Biscoe, island_Dream, island_Torgersen). The same is done for sex. If the original data is “Biscoe,” the island_Biscoe column will be set to 1 and the others to 0.
The target variable species is mapped to numerical values (y_encoded).
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
To evaluate a model, it is necessary to measure the model's performance on data not used for training. 7:3 is widely used as a general practice in machine learning.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
The fit method is used to train the model.
The x_train represents the training data for the explanatory variables, and the y_train represents the target variables.
By calling this method, the model trained based on the training data is stored in clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() is a function for saving Python objects in binary format. By saving the model in this format, the model can be loaded from a file and used as-is without having to be trained again.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit is a Python library that makes it easy to create and share custom web applications for machine learning and data science projects.
numpy is a fundamental Python library for numerical computing. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
Input values are retrieved from the input form created by Stremlit, and categorical variables are encoded using the same rules as when the model was created. Note that the order of each data must also be the same as when the model was created. If the order is different, an error will occur when executing a forecast using the model.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" is the file where the previously saved model is stored. This file contains a trained RandomForestClassifier in binary format. Running this code loads the model into clf, allowing you to use it for predictions and evaluations on new data.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): Uses the trained model to predict the class for the new encoded input data, storing the result in prediction.
clf.predict_proba(input_encoded_df): Calculates the probability for each class, storing the results in prediction_proba.
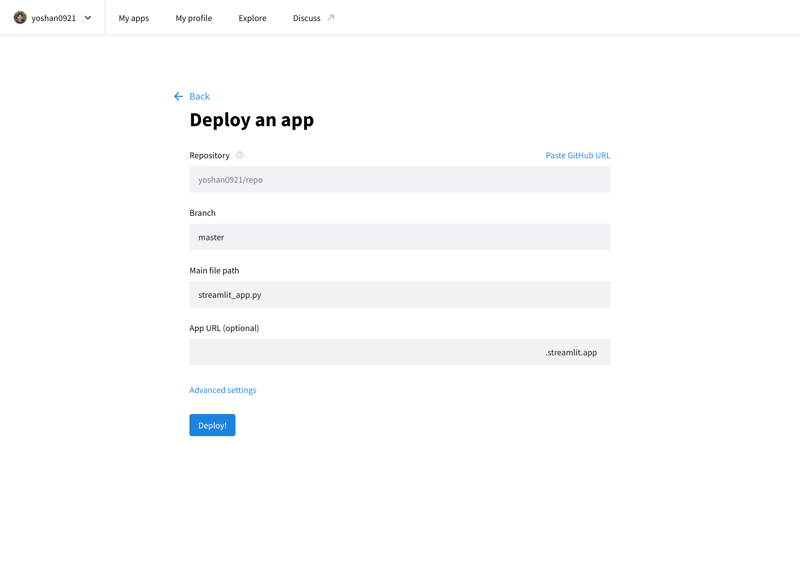
You can publish your developed application on the Internet by accessing the Stremlit Community Cloud (https://streamlit.io/cloud) and specifying the URL of the GitHub repository.

Artwork by @allison_horst (https://github.com/allisonhorst)
The model is trained using the Palmer Penguins dataset, a widely recognized dataset for practicing machine learning techniques. This dataset provides information on three penguin species (Adelie, Chinstrap, and Gentoo) from the Palmer Archipelago in Antarctica. Key features include:
This dataset is sourced from Kaggle, and it can be accessed here. The diversity in features makes it an excellent choice for building a classification model and understanding the importance of each feature in species prediction.














![How to Resolve "Unrecognized name: employees at [9:8]" Error in BigQuery?](http://www.luping.net/uploads/20250218/173987605067b466d280e71.jpg173987605067b466d280e79.jpg)
Disclaimer: All resources provided are partly from the Internet. If there is any infringement of your copyright or other rights and interests, please explain the detailed reasons and provide proof of copyright or rights and interests and then send it to the email: [email protected] We will handle it for you as soon as possible.
Copyright© 2022 湘ICP备2022001581号-3










