
Java program to remove duplicates from a given stack
 Browse:757
Browse:757
In this article, we’ll explore two methods to remove duplicate elements from a stack in Java. We’ll compare a straightforward approach with nested loops and a more efficient method using a HashSet. The goal is to demonstrate how to optimize duplicate removal and to evaluate the performance of each approach.
Problem statement
Write a Java program to remove the duplicate element from the stack.
Input
Stackdata = initData(10L);
Output
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
To remove duplicates from a given stack, we have 2 approaches −
- Naïve approach: Create two nested loops to see which elements are already present and prevent adding them to the result stack return.
- HashSet approach: Use a Set to store unique elements, and take advantage of its O(1) complexity to check if an element is present or not.
Generating and cloning random stacks
Below is the Java program first builds a random stack and then creates a duplicate of it for further use −
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData helps create a Stack with a specified size and random elements ranging from 1 to 100.
manualCloneStack helps generate data by copying data from another stack, using it for performance comparison between the two ideas.
Remove duplicates from a given stack using Naïve approach
Following are the step to remove duplicates from a given stack using Naïve approach −
- Start the timer.
- Create an empty stack to store unique elements.
- Iterate using while loop and continue until the original stack is empty pop the top element.
- Check for duplicates using resultStack.contains(element) to see if the element is already in the result stack.
- If the element is not in the result stack, add it to resultStack.
- Record the end time and calculate the total time spent.
- Return result
Example
Below is the Java program to remove duplicates from a given stack using Naïve approach −
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
For Naive approach, we use
while (!stack.isEmpty())
resultStack.contains(element)
to check if the element is already present.Remove duplicates from a given stack using optimized approach (HashSet)
Following are the step to remove duplicates from a given stack using optimized approach −
- Start the timer
- Create a Set to track seen elements (for O(1) complexity checks).
- Create a temporary stack to store unique elements.
- Iterate using the while loop continue until the stack is empty .
- Remove the top element from the stack.
- To check the duplicates we will use seen.contains(element) to check if the element is already in the set.
- If the element is not in the set, add it to both seen and the temporary stack.
- Record the end time and calculate the total time spent.
- Return the result
Example
Below is the Java program to remove duplicates from a given stack using HashSet −
public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
For optimized approach, we use
Set seen Using both approaches together
Below are the step to remove duplicates from a given stack using both approaches mentioned above −
- Initialize data we are using the initData(Long size) method to create a stack filled with random integers.
- Clone the Stack we are using the cloneStack(Stack stack) method to create an exact copy of the original stack.
- Generate the initial stack with initData.
- Clone this stack using cloneStack.
- Apply the naive approach to remove duplicates from the original stack.
- Apply the optimized approach to remove duplicates from the cloned stack.
- Display the time taken for each method and the unique elements produced by both approaches
Example
Below is the Java program that removes duplicate elements from a stack using both approaches mentioned above −
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
}
Output
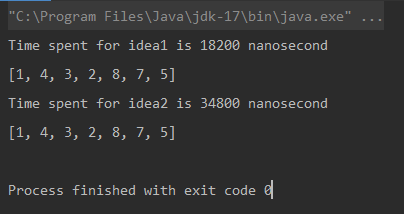
Comparison
* The unit of measurement is nanosecond.
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| Method | 100 elements | 1000 elements | 10000 elements |
100000 elements |
1000000 elements |
| Idea 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| Idea 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
As observed, the time running for Idea 2 is shorter than for Idea 1 because the complexity of Idea 1 is O(n²), while the complexity of Idea 2 is O(n). So, when the number of stacks increases, the time spent on calculations also increases based on it.
-
 How Can I Efficiently Generate URL-Friendly Slugs from Unicode Strings in PHP?Crafting a Function for Efficient Slug GenerationCreating slugs, simplified representations of Unicode strings used in URLs, can be a challenging task...Programming Posted on 2025-07-03
How Can I Efficiently Generate URL-Friendly Slugs from Unicode Strings in PHP?Crafting a Function for Efficient Slug GenerationCreating slugs, simplified representations of Unicode strings used in URLs, can be a challenging task...Programming Posted on 2025-07-03 -
How to Implement a Generic Hash Function for Tuples in Unordered Collections?Generic Hash Function for Tuples in Unordered CollectionsThe std::unordered_map and std::unordered_set containers provide efficient lookup and inserti...Programming Posted on 2025-07-03
-
How Can I Efficiently Read a Large File in Reverse Order Using Python?Reading a File in Reverse Order in PythonIf you're working with a large file and need to read its contents from the last line to the first, Python...Programming Posted on 2025-07-03
-
Python metaclass working principle and class creation and customizationWhat are Metaclasses in Python?Metaclasses are responsible for creating class objects in Python. Just as classes create instances, metaclasses create ...Programming Posted on 2025-07-03
-
Why Isn\'t My CSS Background Image Appearing?Troubleshoot: CSS Background Image Not AppearingYou've encountered an issue where your background image fails to load despite following tutorial i...Programming Posted on 2025-07-03
-
Why Doesn't `body { margin: 0; }` Always Remove Top Margin in CSS?Addressing Body Margin Removal in CSSFor novice web developers, removing the margin of the body element can be a confusing task. Often, the code provi...Programming Posted on 2025-07-03
-
How do Java's Map.Entry and SimpleEntry simplify key-value pair management?A Comprehensive Collection for Value Pairs: Introducing Java's Map.Entry and SimpleEntryIn Java, when defining a collection where each element com...Programming Posted on 2025-07-03
-
Do I Need to Explicitly Delete Heap Allocations in C++ Before Program Exit?Explicit Deletion in C Despite Program ExitWhen working with dynamic memory allocation in C , developers often wonder if it's necessary to manu...Programming Posted on 2025-07-03
-
How do you extract a random element from an array in PHP?Random Selection from an ArrayIn PHP, obtaining a random item from an array can be accomplished with ease. Consider the following array:$items = [523,...Programming Posted on 2025-07-03
-
Spark DataFrame tips to add constant columnsCreating a Constant Column in a Spark DataFrameAdding a constant column to a Spark DataFrame with an arbitrary value that applies to all rows can be a...Programming Posted on 2025-07-03
-
Will fake wakeup really happen in Java?Spurious Wakeups in Java: Reality or Myth?The concept of spurious wakeups in Java synchronization has been a subject of discussion for quite some time...Programming Posted on 2025-07-03
-
How Can I Customize Compilation Optimizations in the Go Compiler?Customizing Compilation Optimizations in Go CompilerThe default compilation process in Go follows a specific optimization strategy. However, users may...Programming Posted on 2025-07-03
-
FastAPI Custom 404 Page Creation GuideCustom 404 Not Found Page with FastAPITo create a custom 404 Not Found page, FastAPI offers several approaches. The appropriate method depends on your...Programming Posted on 2025-07-03
-
How Can I Programmatically Select All Text Within a DIV on Mouse Click?Programmatically Selecting DIV Text on Mouse ClickQuestionGiven a DIV element with text content, how can the user programmatically select the entire t...Programming Posted on 2025-07-03
-
Is There a Performance Difference Between Using a For-Each Loop and an Iterator for Collection Traversal in Java?For Each Loop vs. Iterator: Efficiency in Collection TraversalIntroductionWhen traversing a collection in Java, the choice arises between using a for-...Programming Posted on 2025-07-03















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









