 Front page > Programming > Using faker and pandas Python Libraries to Create Synthetic Data for Testing
Front page > Programming > Using faker and pandas Python Libraries to Create Synthetic Data for Testing
Using faker and pandas Python Libraries to Create Synthetic Data for Testing
 Browse:497
Browse:497
Introduction:
Comprehensive testing is essential for data-driven applications, but it often relies on having the right datasets, which may not always be available. Whether you are developing web applications, machine learning models, or backend systems, realistic and structured data is crucial for proper validation and ensuring robust performance. Acquiring real-world data may be limited due to privacy concerns, licensing restrictions, or simply the unavailability of relevant data. This is where synthetic data becomes valuable.
In this blog, we will explore how Python can be used to generate synthetic data for different scenarios, including:
- Interrelated Tables: Representing one-to-many relationships.
- Hierarchical Data: Often used in organizational structures.
- Complex Relationships: Such as many-to-many relationships in enrollment systems.
We’ll leverage the faker and pandas libraries to create realistic datasets for these use cases.
Example 1: Creating Synthetic Data for Customers and Orders (One-to-Many Relationship)
In many applications, data is stored in multiple tables with foreign key relationships. Let’s generate synthetic data for customers and their orders. A customer can place multiple orders, representing a one-to-many relationship.
Generating the Customers Table
The Customers table contains basic information such as CustomerID, name, and email address.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_customers(num_customers):
customers = []
for _ in range(num_customers):
customer_id = fake.uuid4()
name = fake.name()
email = fake.email()
customers.append({'CustomerID': customer_id, 'CustomerName': name, 'Email': email})
return pd.DataFrame(customers)
customers_df = generate_customers(10)
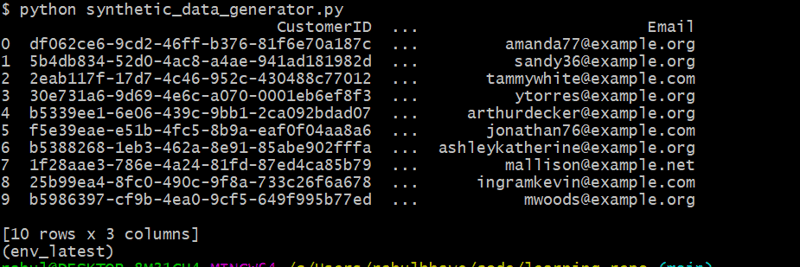
This code generates 10 random customers using Faker to create realistic names and email addresses.
Generating the Orders Table
Now, we generate the Orders table, where each order is associated with a customer through CustomerID.
def generate_orders(customers_df, num_orders):
orders = []
for _ in range(num_orders):
order_id = fake.uuid4()
customer_id = random.choice(customers_df['CustomerID'].tolist())
product = fake.random_element(elements=('Laptop', 'Phone', 'Tablet', 'Headphones'))
price = round(random.uniform(100, 2000), 2)
orders.append({'OrderID': order_id, 'CustomerID': customer_id, 'Product': product, 'Price': price})
return pd.DataFrame(orders)
orders_df = generate_orders(customers_df, 30)
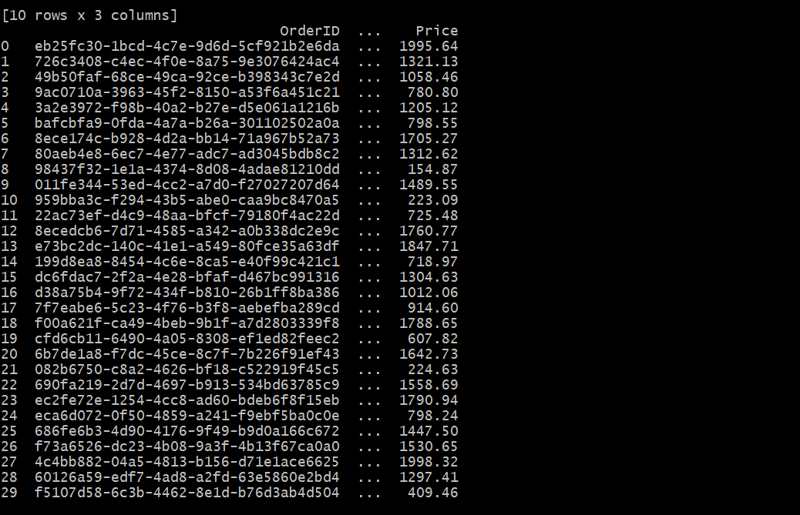
In this case, the Orders table links each order to a customer using the CustomerID. Each customer can place multiple orders, forming a one-to-many relationship.
Example 2: Generating Hierarchical Data for Departments and Employees
Hierarchical data is often used in organizational settings, where departments have multiple employees. Let’s simulate an organization with departments, each of which has multiple employees.
Generating the Departments Table
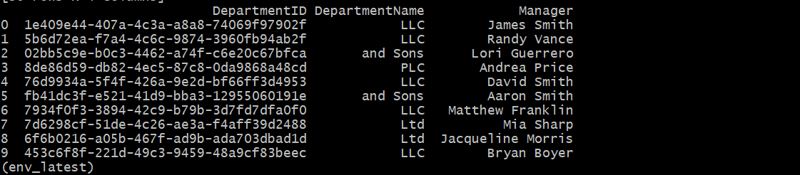
The Departments table contains each department's unique DepartmentID, name, and manager.
def generate_departments(num_departments):
departments = []
for _ in range(num_departments):
department_id = fake.uuid4()
department_name = fake.company_suffix()
manager = fake.name()
departments.append({'DepartmentID': department_id, 'DepartmentName': department_name, 'Manager': manager})
return pd.DataFrame(departments)
departments_df = generate_departments(10)
Generating the Employees Table
Next, we generate theEmployeestable, where each employee is associated with a department via DepartmentID.
def generate_employees(departments_df, num_employees):
employees = []
for _ in range(num_employees):
employee_id = fake.uuid4()
employee_name = fake.name()
email = fake.email()
department_id = random.choice(departments_df['DepartmentID'].tolist())
salary = round(random.uniform(40000, 120000), 2)
employees.append({
'EmployeeID': employee_id,
'EmployeeName': employee_name,
'Email': email,
'DepartmentID': department_id,
'Salary': salary
})
return pd.DataFrame(employees)
employees_df = generate_employees(departments_df, 100)
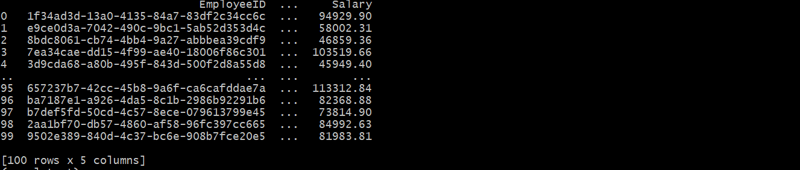
This hierarchical structure links each employee to a departmentthrough DepartmentID, forming a parent-child relationship.
Example 3: Simulating Many-to-Many Relationships for Course Enrollments
In certain scenarios, many-to-many relationships exist, where one entity relates to many others. Let’s simulate this with students enrolling in multiple courses, where each course has multiple students.
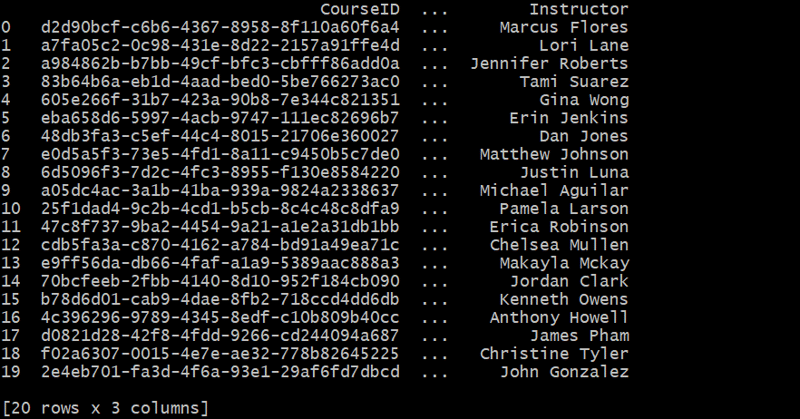
Generating the Courses Table
def generate_courses(num_courses):
courses = []
for _ in range(num_courses):
course_id = fake.uuid4()
course_name = fake.bs().title()
instructor = fake.name()
courses.append({'CourseID': course_id, 'CourseName': course_name, 'Instructor': instructor})
return pd.DataFrame(courses)
courses_df = generate_courses(20)
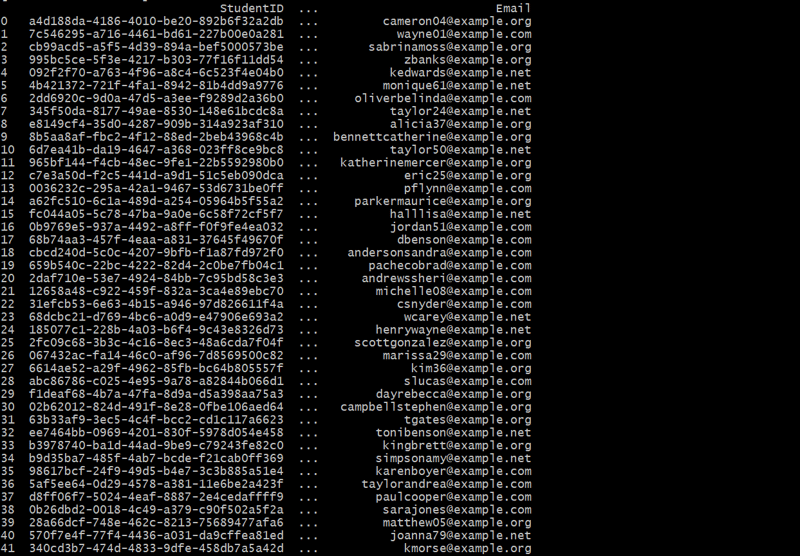
Generating the Students Table
def generate_students(num_students):
students = []
for _ in range(num_students):
student_id = fake.uuid4()
student_name = fake.name()
email = fake.email()
students.append({'StudentID': student_id, 'StudentName': student_name, 'Email': email})
return pd.DataFrame(students)
students_df = generate_students(50)
print(students_df)
Generating the Course Enrollments Table
The CourseEnrollments table captures the many-to-many relationship between students and courses.
def generate_course_enrollments(students_df, courses_df, num_enrollments):
enrollments = []
for _ in range(num_enrollments):
enrollment_id = fake.uuid4()
student_id = random.choice(students_df['StudentID'].tolist())
course_id = random.choice(courses_df['CourseID'].tolist())
enrollment_date = fake.date_this_year()
enrollments.append({
'EnrollmentID': enrollment_id,
'StudentID': student_id,
'CourseID': course_id,
'EnrollmentDate': enrollment_date
})
return pd.DataFrame(enrollments)
enrollments_df = generate_course_enrollments(students_df, courses_df, 200)
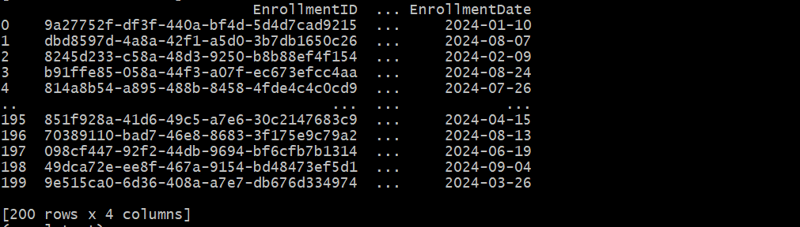
In this example, we create a linking table to represent many-to-many relationships between students and courses.
Conclusion:
Using Python and libraries like Faker and Pandas, you can generate realistic and diverse synthetic datasets to meet a variety of testing needs. In this blog, we covered:
- Interrelated Tables: Demonstrating a one-to-many relationship between customers and orders.
- Hierarchical Data: Illustrating a parent-child relationship between departments and employees.
- Complex Relationships: Simulating many-to-many relationships between students and courses.
These examples lay the foundation for generating synthetic data tailored to your needs. Further enhancements, such as creating more complex relationships, customizing data for specific databases, or scaling datasets for performance testing, can take synthetic data generation to the next level.
These examples provide a solid foundation for generating synthetic data. However, further enhancements can be made to increase complexity and specificity, such as:
- Database-Specific Data: Customizing data generation for different database systems (e.g., SQL vs. NoSQL).
- More Complex Relationships: Creating additional interdependencies, such as temporal relationships, multi-level hierarchies, or unique constraints.
- Scaling Data: Generating larger datasets for performance testing or stress testing, ensuring the system can handle real-world conditions at scale. By generating synthetic data tailored to your needs, you can simulate realistic conditions for developing, testing, and optimizing applications without relying on sensitive or hard-to-acquire datasets.
If you like the article, please share it with your friends and colleagues. You can connect with me on LinkedIn to discuss any further ideas.
-
 How to Simplify JSON Parsing in PHP for Multi-Dimensional Arrays?Parsing JSON with PHPTrying to parse JSON data in PHP can be challenging, especially when dealing with multi-dimensional arrays. To simplify the proce...Programming Posted on 2025-04-27
How to Simplify JSON Parsing in PHP for Multi-Dimensional Arrays?Parsing JSON with PHPTrying to parse JSON data in PHP can be challenging, especially when dealing with multi-dimensional arrays. To simplify the proce...Programming Posted on 2025-04-27 -
How to Correctly Display the Current Date and Time in "dd/MM/yyyy HH:mm:ss.SS" Format in Java?How to Display Current Date and Time in "dd/MM/yyyy HH:mm:ss.SS" FormatIn the provided Java code, the issue with displaying the date and tim...Programming Posted on 2025-04-27
-
How to efficiently repeat string characters for indentation in C#?Repeating a String for IndentationWhen indenting a string based on an item's depth, it's convenient to have an efficient way to return a strin...Programming Posted on 2025-04-27
-
How Can I Customize Compilation Optimizations in the Go Compiler?Customizing Compilation Optimizations in Go CompilerThe default compilation process in Go follows a specific optimization strategy. However, users may...Programming Posted on 2025-04-27
-
Async Void vs. Async Task in ASP.NET: Why does the Async Void method sometimes throw exceptions?Understanding the Distinction Between Async Void and Async Task in ASP.NetIn ASP.Net applications, asynchronous programming plays a crucial role in en...Programming Posted on 2025-04-27
-
When does a Go web application close the database connection?Managing Database Connections in Go Web ApplicationsIn simple Go web applications that utilize databases like PostgreSQL, the timing of database conne...Programming Posted on 2025-04-27
-
Reasons for CodeIgniter to connect to MySQL database after switching to MySQLiUnable to Connect to MySQL Database: Troubleshooting Error MessageWhen attempting to switch from the MySQL driver to the MySQLi driver in CodeIgniter,...Programming Posted on 2025-04-27
-
Tips for floating pictures to the right side of the bottom and wrapping around textFloating an Image to the Bottom Right with Text Wrapping AroundIn web design, it is sometimes desirable to float an image to the bottom right corner o...Programming Posted on 2025-04-27
-
How to avoid memory leaks when slicing Go language?Memory Leak in Go SlicesUnderstanding memory leaks in Go slices can be a challenge. This article aims to provide clarification by examining two approa...Programming Posted on 2025-04-27
-
How to efficiently detect empty arrays in PHP?Checking Array Emptiness in PHPAn empty array can be determined in PHP through various approaches. If the need is to verify the presence of any array ...Programming Posted on 2025-04-27
-
Laravel Database: Detailed explanation of what is and usesO Laravel is a framework that offers many facilities in the database connection. It has several advanced features to help deal with the most divers...Programming Posted on 2025-04-27
-
How to Parse Numbers in Exponential Notation Using Decimal.Parse()?Parsing a Number from Exponential NotationWhen attempting to parse a string expressed in exponential notation using Decimal.Parse("1.2345E-02&quo...Programming Posted on 2025-04-27
-
The difference between PHP and C++ function overload processingPHP Function Overloading: Unraveling the Enigma from a C PerspectiveAs a seasoned C developer venturing into the realm of PHP, you may encounter t...Programming Posted on 2025-04-27
-
Why Am I Getting a "Could Not Find an Implementation of the Query Pattern" Error in My Silverlight LINQ Query?Query Pattern Implementation Absence: Resolving "Could Not Find" ErrorsIn a Silverlight application, an attempt to establish a database conn...Programming Posted on 2025-04-27
-
How does Android send POST data to PHP server?Sending POST Data in AndroidIntroductionThis article addresses the need to send POST data to a PHP script and display the result in an Android applica...Programming Posted on 2025-04-27















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









