
ETL: Extracting a Person&#s Name from Text
 Browse:674
Browse:674
Let's say we want to scrape chicagomusiccompass.com.
As you can see, it has several cards, each representing an event. Now, let's check out the next one:
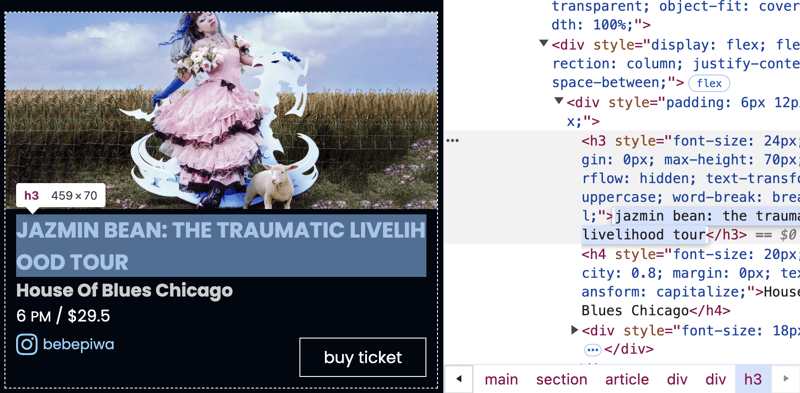
Notice that the name of the event is:
jazmin bean: the traumatic livelihood tour
So now the question is: How do we extract the artist's name from the text?
As a human, I can "easily" tell that jazmin bean is the artist—just check out their wiki page. But writing code to extract that name can get tricky.
We could think, "Hey, anything before the : should be the artist's name," which seems clever, right? It works for this case, but what about this one:
happy hour on the patio: kathryn & chris
Here, the order is flipped. We could keep adding logic to handle different cases, but soon we'll end up with a ton of rules that are fragile and probably won't cover everything.
That’s where Named Entity Recognition (NER) models come in handy. They’re open source and can help us extract names from text. It won’t catch every case, but most of the time, they’ll get us the info we need.
With this approach, the extraction becomes way easier. I'm going with Python because the community around Machine Learning in Python is just unbeatable.
from gliner import GLiNER
model = GLiNER.from_pretrained("urchade/gliner_base")
text = "jazmin bean: the traumatic livelihood tour"
labels = ["person", "bands", "projects"]
entities = model.predict_entities(text, labels)
for entity in entities:
print(entity["text"], "=>", entity["label"])
Which generates the output:
jazmin bean => person
Now, let’s take a look at that other case:
happy hour on the patio: kathryn & chris
Output:
kathryn => person chris => person
source-GLiNER
Awesome, right? No more tedious logic to extract names, just use a model. Sure, it won’t cover every possible case, but for my project, this level of flexibility works just fine. If you need more accuracy, you can always:
- Try a different model
- Contribute to the existing model
- Fork the project and tweak it to fit your needs
Conclusion
As a Software Developer, it's highly recommended to stay updated with the tools in the Machine Learning space. Not everything can be solved with just plain programming and logic—some challenges are better tackled using models and statistics.
-
 Why Doesn\'t Firefox Display Images Using the CSS `content` Property?Displaying Images with Content URL in FirefoxAn issue has been encountered where certain browsers, specifically Firefox, fail to display images when r...Programming Posted on 2025-03-11
Why Doesn\'t Firefox Display Images Using the CSS `content` Property?Displaying Images with Content URL in FirefoxAn issue has been encountered where certain browsers, specifically Firefox, fail to display images when r...Programming Posted on 2025-03-11 -
How do you extract a random element from an array in PHP?Random Selection from an ArrayIn PHP, obtaining a random item from an array can be accomplished with ease. Consider the following array:$items = [523,...Programming Posted on 2025-03-11
-
Why Isn\'t My CSS Background Image Appearing?Troubleshoot: CSS Background Image Not AppearingYou've encountered an issue where your background image fails to load despite following tutorial i...Programming Posted on 2025-03-11
-
How to Check if an Object Has a Specific Attribute in Python?Method to Determine Object Attribute ExistenceThis inquiry seeks a method to verify the presence of a specific attribute within an object. Consider th...Programming Posted on 2025-03-11
-
Is There a Performance Difference Between Using a For-Each Loop and an Iterator for Collection Traversal in Java?For Each Loop vs. Iterator: Efficiency in Collection TraversalIntroductionWhen traversing a collection in Java, the choice arises between using a for-...Programming Posted on 2025-03-11
-
How Can I UNION Database Tables with Different Numbers of Columns?Combined tables with different columns] Can encounter challenges when trying to merge database tables with different columns. A straightforward way i...Programming Posted on 2025-03-11
-
Why Does Microsoft Visual C++ Fail to Correctly Implement Two-Phase Template Instantiation?The Mystery of "Broken" Two-Phase Template Instantiation in Microsoft Visual C Problem Statement:Users commonly express concerns that Micro...Programming Posted on 2025-03-11
-
How to upload files with additional parameters using java.net.URLConnection and multipart/form-data encoding?Uploading Files with HTTP RequestsTo upload files to an HTTP server while also submitting additional parameters, java.net.URLConnection and multipart/...Programming Posted on 2025-03-11
-
How to Write Truly Non-Blocking Functions in Node.js?Correct Way to Write a Non-Blocking Function in Node.jsThe non-blocking paradigm is crucial in Node.js for achieving high performance. However, it can...Programming Posted on 2025-03-10
-
How to Extract Text from Specific HTML Tags Using DOMDocument and XPath?Parsing HTML with PHP's DOMDocument and XPathWhen attempting to parse HTML using PHP's DOMDocument, a common issue is finding specific text wi...Programming Posted on 2025-03-10
-
d[IA]gnosis: developing RAG applications with IRIS for HealtWith the introduction of vector data types and the Vector Search functionality in IRIS, a whole world of possibilities opens up for the development of...Programming Posted on 2025-03-10
-
Can We Create Generic Arrays in Java That Extend Comparable?Generic Arrays in Java: Exploring Covariance and Type ErasureIntroductionGeneric arrays, where the array elements share a common type parameter, prese...Programming Posted on 2025-03-09
-
Why Does My WordPress Ajax Call Return \"0\"?Troubleshooting Ajax Calls in WordPress: Why Your Output is "0"In WordPress, making Ajax calls can be straightforward, but sometimes issues ...Programming Posted on 2025-03-07
-
Can I Control the Height of Images Within CSS :before/:after Pseudo-Elements?Can I Adjust Image Height in CSS :before/:after Pseudo-Elements?Your inquiry is whether it's possible to modify the height of an image used within...Programming Posted on 2025-03-07
-
My Laravel Package Building WorkflowCrafting Laravel Packages: A Comprehensive Guide This article delves into the process of building Laravel packages, offering a structured approach fro...Programming Posted on 2025-03-07










![d[IA]gnosis: developing RAG applications with IRIS for Healt](http://www.luping.net/uploads/20250309/174153458267cdb5769930b.jpg174153458267cdb57699314.png)




Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









