
Entropix: Sampling Techniques for Maximizing Inference Performance
 Browse:692
Browse:692
Entropix: Sampling Techniques for Maximizing Inference Performance
According to the Entropix README, Entropix uses an entropy-based sampling method. This article explains the specific sampling techniques based on entropy and varentropy.
Entropy and Varentropy
Let's start by explaining entropy and varentropy, as these are key factors in determining the sampling strategy.
Entropy
In information theory, entropy is a measure of the uncertainty of a random variable. The entropy of a random variable X is defined by the following equation:
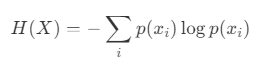
- X: A discrete random variable.
- x_i: The i-th possible state of X.
- p(x_i): The probability of state x_i.
Entropy is maximized when the probability distribution is uniform. Conversely, when a specific state is much more likely than others, entropy decreases.
Varentropy
Varentropy, closely related to entropy, represents the variability in the information content. Considering the information content I(X), entropy H(X), and variance for a random variable X, varentropy V E(X) is defined as follows:
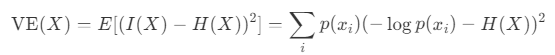
Varentropy becomes large when the probabilities p(x_i) vary greatly. It becomes small when the probabilities are uniform—either when the distribution has maximum entropy or when one value has a probability of 1 and all others have a probability of 0.
Sampling Methods
Next, let's explore how sampling strategies change based on entropy and varentropy values.
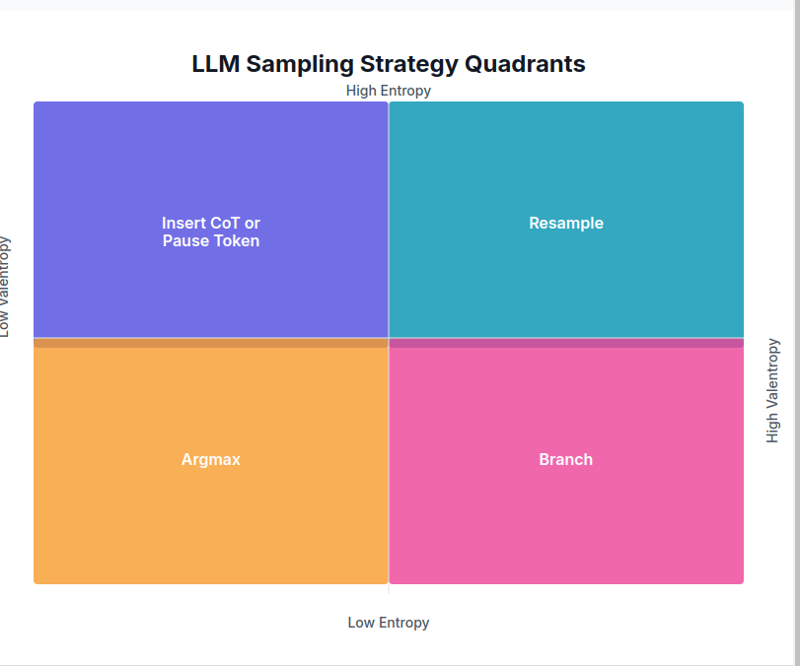
1. Low Entropy, Low Varentropy → Argmax
In this scenario, a particular token has a much higher prediction probability than the others. Since the next token is almost certain, Argmax is used.
if entCode link
2. Low Entropy, High Varentropy → Branch
This occurs when there is some confidence, but multiple viable options exist. In this case, the Branch strategy is used to sample from multiple choices and select the best outcome.
elif ent 5.0: temp_adj = 1.2 0.3 * interaction_strength top_k_adj = max(5, int(top_k * (1 0.5 * (1 - agreement)))) return _sample(logits, temperature=min(1.5, temperature * temp_adj), top_p=top_p, top_k=top_k_adj, min_p=min_p, generator=generator)Code link
Although this strategy is called "Branch," the current code appears to adjust the sampling range and select a single path. (If anyone has more insight, further clarification would be appreciated.)
3. High Entropy, Low Varentropy → CoT or Insert Pause Token
When the prediction probabilities of the next token are fairly uniform, indicating that the next context is not certain, a clarification token is inserted to resolve the ambiguity.
elif ent > 3.0 and ventCode link
4. High Entropy, High Varentropy → Resample
In this case, there are multiple contexts, and the prediction probabilities of the next token are low. A resampling strategy is used with a higher temperature setting and a lower top-p.
elif ent > 5.0 and vent > 5.0: temp_adj = 2.0 0.5 * attn_vent top_p_adj = max(0.5, top_p - 0.2 * attn_ent) return _sample(logits, temperature=max(2.0, temperature * temp_adj), top_p=top_p_adj, top_k=top_k, min_p=min_p, generator=generator)Code link
Intermediate Cases
If none of the above conditions are met, adaptive sampling is performed. Multiple samples are taken, and the best sampling score is calculated based on entropy, varentropy, and attention information.
else: return adaptive_sample( logits, metrics, gen_tokens, n_samples=5, base_temp=temperature, base_top_p=top_p, base_top_k=top_k, generator=generator )Code link
References
- Entropix Repository
- What is Entropix Doing?
-
 How to create dynamic variables in Python?Dynamic Variable Creation in PythonThe ability to create variables dynamically can be a powerful tool, especially when working with complex data struc...Programming Posted on 2025-07-12
How to create dynamic variables in Python?Dynamic Variable Creation in PythonThe ability to create variables dynamically can be a powerful tool, especially when working with complex data struc...Programming Posted on 2025-07-12 -
How to Capture and Stream stdout in Real Time for Chatbot Command Execution?Capturing stdout in Real Time from Command ExecutionIn the realm of developing chatbots capable of executing commands, a common requirement is the abi...Programming Posted on 2025-07-12
-
How to Parse JSON Arrays in Go Using the `json` Package?Parsing JSON Arrays in Go with the JSON PackageProblem: How can you parse a JSON string representing an array in Go using the json package?Code Exampl...Programming Posted on 2025-07-12
-
How Can I Maintain Custom JTable Cell Rendering After Cell Editing?Maintaining JTable Cell Rendering After Cell EditIn a JTable, implementing custom cell rendering and editing capabilities can enhance the user experie...Programming Posted on 2025-07-12
-
Why Am I Getting a "Could Not Find an Implementation of the Query Pattern" Error in My Silverlight LINQ Query?Query Pattern Implementation Absence: Resolving "Could Not Find" ErrorsIn a Silverlight application, an attempt to establish a database conn...Programming Posted on 2025-07-12
-
Python metaclass working principle and class creation and customizationWhat are Metaclasses in Python?Metaclasses are responsible for creating class objects in Python. Just as classes create instances, metaclasses create ...Programming Posted on 2025-07-12
-
CSS strongly typed language analysisOne of the ways you can classify a programming language is by how strongly or weakly typed it is. Here, “typed” means if variables are known at compil...Programming Posted on 2025-07-12
-
Why Does Microsoft Visual C++ Fail to Correctly Implement Two-Phase Template Instantiation?The Mystery of "Broken" Two-Phase Template Instantiation in Microsoft Visual C Problem Statement:Users commonly express concerns that Micro...Programming Posted on 2025-07-12
-
User local time format and time zone offset display guideDisplaying Date/Time in User's Locale Format with Time OffsetWhen presenting dates and times to end-users, it's crucial to display them in the...Programming Posted on 2025-07-12
-
Async Void vs. Async Task in ASP.NET: Why does the Async Void method sometimes throw exceptions?Understanding the Distinction Between Async Void and Async Task in ASP.NetIn ASP.Net applications, asynchronous programming plays a crucial role in en...Programming Posted on 2025-07-12
-
Method for correct passing of C++ member function pointersHow to Pass Member Function Pointers in C When passing a class member function to a function that accepts a member function pointer, it's essenti...Programming Posted on 2025-07-12
-
Guide to Solve CORS Issues in Spring Security 4.1 and aboveSpring Security CORS Filter: Troubleshooting Common IssuesWhen integrating Spring Security into an existing project, you may encounter CORS-related er...Programming Posted on 2025-07-12
-
How to Check if an Object Has a Specific Attribute in Python?Method to Determine Object Attribute ExistenceThis inquiry seeks a method to verify the presence of a specific attribute within an object. Consider th...Programming Posted on 2025-07-12
-
Can You Use CSS to Color Console Output in Chrome and Firefox?Displaying Colors in JavaScript ConsoleIs it possible to use Chrome's console to display colored text, such as red for errors, orange for warnings...Programming Posted on 2025-07-12
-
Why Am I Getting a \"Class \'ZipArchive\' Not Found\" Error After Installing Archive_Zip on My Linux Server?Class 'ZipArchive' Not Found Error While Installing Archive_Zip on Linux ServerSymptom:When attempting to run a script that utilizes the ZipAr...Programming Posted on 2025-07-12















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









