 Front page > Programming > Enhancing Performance with Static Analysis, Image Initialization and Heap Snapshotting
Front page > Programming > Enhancing Performance with Static Analysis, Image Initialization and Heap Snapshotting
Enhancing Performance with Static Analysis, Image Initialization and Heap Snapshotting
 Browse:864
Browse:864
From monolithic structures to the world of distributed systems, application development has come a long way. The massive adoption of cloud computing and microservice architecture has significantly altered the approach to how server applications are created and deployed. Instead of giant application servers, we now have independent, individually deployed services that spring into action
as and when needed.
However, a new player on the block that can impact this smooth functioning might be 'cold starts.' Cold starts kick in when the first request processes on a freshly spawned worker. This situation demands language runtime initialization and service configuration initialization before processing the actual request. The unpredictability and slower execution associated with cold starts can breach the service level agreements of a cloud service. So, how does one counter this growing concern?
Native Image: Optimizing Startup Time and Memory Footprint
To combat the inefficiencies of cold starts, a novel approach has been developed involving points-to analysis, application initialization at build time, heap snapshotting, and ahead-of-time (AOT) compilation. This method operates under a closed-world assumption, requiring all Java classes to be predetermined and accessible at build time. During this phase, a comprehensive points-to analysis determines all reachable program elements (classes, methods, fields) to ensure that only essential Java methods are compiled.
The initialization code for the application can execute during the build process rather than at runtime. This allows for the pre-allocation of Java objects and the construction of complex data structures, which are then made available at runtime via an "image heap". This image heap is integrated within the executable, providing immediate availability upon application start. The
iterative execution of points-to analysis and snapshotting continues until a stable state (fixed point) is achieved, optimizing both startup time and resource consumption.
Detailed Workflow
The input for our system is Java bytecode, which could originate from languages like Java, Scala, or Kotlin. The process treats the application, its libraries, the JDK, and VM components uniformly to produce a native executable specific to an operating system and architecture—termed a "native image". The building process includes iterative points-to analysis and heap snapshotting until a fixed point is reached, allowing the application to actively participate through registered callbacks. These steps are collectively known as the native image build process (Figure 1)
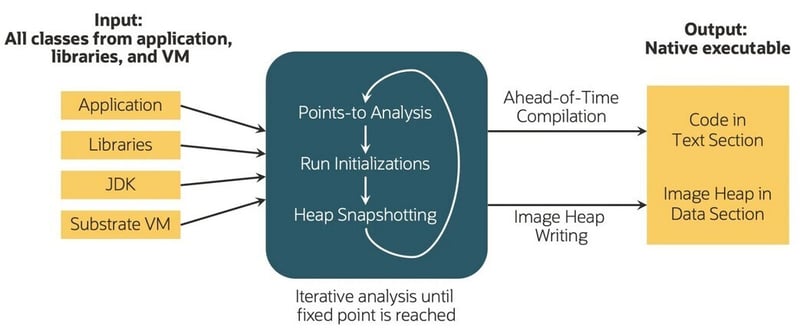
Figure 1 – Native Image Build Process(source: redhat.com)
Points-to Analysis
We employ a points-to analysis to ascertain the reachability of classes, methods, and fields during runtime. The points-to analysis commences with all entry points, such as the main method of the application, and iteratively traverses all transitively reachable methods until reaching a fixed point(Figure 2).
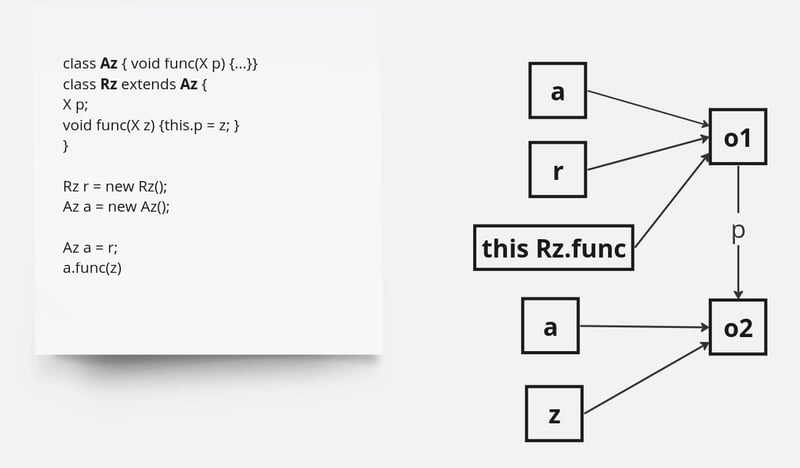
Figure 2 – Points-to-analysis
Our points-to analysis leverages the front end of our compiler to parse Java bytecode into the compiler’s high-level intermediate representation (IR). Subsequently, the IR is transformed into a type-flow graph. In this graph, nodes represent instructions operating on object types, while edges denote directed use edges between nodes, pointing from the definition to the usage. Each node maintains a type state, consisting of a list of types that can reach the node and nullness information. Type states propagate through the use edges; if the type state of a node changes, this change is disseminated to all usages. Importantly, type states can only expand; new types may be added to a type state, but existing types are never removed. This mechanism ensures that the
analysis ultimately converges to a fixed point, leading to termination.
Run Initialization Code
The points-to analysis guides the execution of initialization code when it hits a local fixed point. This code finds its origins in two separate sources: Class initializers and custom code batch executed at build time through a feature interface:
Class Initializers: Every Java class can have a class initializer indicated by a
method, which initializes static fields. Developers can choose which classes to initialize at build-time vs runtime. Explicit Callbacks: Developers can implement custom code through hooks provided by our system, executing before, during, or after the analysis stages.
Here are the APIs provided for integrating with our system.
Passive API (queries the current analysis status)
boolean isReachable(Class> clazz); boolean isReachable(Field field); boolean isReachable(Executable method);
For more information, refer to the QueryReachabilityAccess
Active API (registers callbacks for analysis status changes):
void registerReachabilityHandler(Consumercallback, Object... elements); void registerSubtypeReachabilityHandler(BiConsumer > callback, Class> baseClass); void registerMethodOverrideReachabilityHandler(BiConsumer callback, Executable baseMethod);
For more information, refer to the BeforeAnalysisAccess
During this phase, the application can execute custom code such as object allocation and initialization of larger data structures. Importantly, the initialization code can access the current points-to analysis state, enabling queries regarding the reachability of types, methods, or fields. This is accomplished using the various isReachable() methods provided by DuringAnalysisAccess. Leveraging this information, the application can construct data structures optimized for the reachable segments of the application.
Heap Snapshotting
Finally, heap snapshotting constructs an object graph by following root pointers like static fields to build a comprehensive view of all reachable objects. This graph then populates the native image's
image heap, ensuring that the application's initial state is efficiently loaded upon startup.
To generate the transitive closure of reachable objects, the algorithm traverses object fields, reading their values using reflection. It's crucial to note that the image builder operates within the Java environment. Only instance fields marked as "read" by the points-to analysis are considered during this traversal. For instance, if a class has two instance fields but one isn't marked as read, the object reachable through the unmarked field is excluded from the image heap.
When encountering a field value whose class hasn't been previously identified by the points-to analysis, the class is registered as a field type. This registration ensures that in subsequent iterations of the points-to analysis, the new type is propagated to all field reads and transitive usages in the type-flow graph.
The code snippet below outlines the core algorithm for heap snapshotting:
Declare List worklist := []
Declare Set reachableObjects := []
Function BuildHeapSnapshot(PointsToState pointsToState)
For Each field in pointsToState.getReachableStaticObjectFields()
Call AddObjectToWorkList(field.readValue())
End For
For Each method in pointsToState.getReachableMethods()
For Each constant in method.embeddedConstants()
Call AddObjectToWorkList(constant)
End For
End For
While worklist.isNotEmpty
Object current := Pop from worklist
If current Object is an Array
For Each value in current
Call AddObjectToWorkList(value)
Add current.getClass() to pointsToState.getObjectArrayTypes()
End For
Else
For Each field in pointsToState.getReachableInstanceObjectFields(current.getClass())
Object value := field.read(current)
Call AddObjectToWorkList(value)
Add value.getClass() to pointsToState.getFieldValueTypes(field)
End For
End If
End While
Return reachableObjects
End Function
In summary, the heap snapshotting algorithm efficiently constructs a snapshot of the heap by systematically traversing reachable objects and their fields. This ensures that only relevant objects are included in the image heap, optimizing the performance and memory footprint of the native image.
Conclusion
In conclusion, the process of heap snapshotting plays a critical role in the creation of native images. By systematically traversing reachable objects and their fields, the heap snapshotting algorithm constructs an object graph that represents the transitive closure of reachable objects from root pointers such as static fields. This object graph is then embedded into the native image as the image heap, serving as the initial heap upon native image startup.
Throughout the process, the algorithm relies on the state of the points-to analysis to determine which objects and fields are relevant for inclusion in the image heap. Objects and fields marked as "read" by the points-to analysis are considered, while unmarked entities are excluded. Additionally, when encountering previously unseen types, the algorithm registers them for propagation in subsequent iterations of the points-to analysis.
Overall, heap snapshotting optimizes the performance and memory usage of native images by ensuring that only necessary objects are included in the image heap. This systematic approach enhances the efficiency and reliability of native image execution.
-
 Spark DataFrame tips to add constant columnsCreating a Constant Column in a Spark DataFrameAdding a constant column to a Spark DataFrame with an arbitrary value that applies to all rows can be a...Programming Posted on 2025-07-02
Spark DataFrame tips to add constant columnsCreating a Constant Column in a Spark DataFrameAdding a constant column to a Spark DataFrame with an arbitrary value that applies to all rows can be a...Programming Posted on 2025-07-02 -
How Can I Handle UTF-8 Filenames in PHP's Filesystem Functions?Handling UTF-8 Filenames in PHP's Filesystem FunctionsWhen creating folders containing UTF-8 characters using PHP's mkdir function, you may en...Programming Posted on 2025-07-02
-
Why Doesn\'t Firefox Display Images Using the CSS `content` Property?Displaying Images with Content URL in FirefoxAn issue has been encountered where certain browsers, specifically Firefox, fail to display images when r...Programming Posted on 2025-07-02
-
How to dynamically discover export package types in Go language?Finding Exported Package Types DynamicallyIn contrast to the limited type discovery capabilities in the reflect package, this article explores alterna...Programming Posted on 2025-07-02
-
Why Isn\'t My CSS Background Image Appearing?Troubleshoot: CSS Background Image Not AppearingYou've encountered an issue where your background image fails to load despite following tutorial i...Programming Posted on 2025-07-02
-
Guide to Solve CORS Issues in Spring Security 4.1 and aboveSpring Security CORS Filter: Troubleshooting Common IssuesWhen integrating Spring Security into an existing project, you may encounter CORS-related er...Programming Posted on 2025-07-02
-
Method to correctly convert Latin1 characters to UTF8 in UTF8 MySQL tableConvert Latin1 Characters in a UTF8 Table to UTF8You've encountered an issue where characters with diacritics (e.g., "Jáuò Iñe") were in...Programming Posted on 2025-07-02
-
Why Doesn't `body { margin: 0; }` Always Remove Top Margin in CSS?Addressing Body Margin Removal in CSSFor novice web developers, removing the margin of the body element can be a confusing task. Often, the code provi...Programming Posted on 2025-07-02
-
Python metaclass working principle and class creation and customizationWhat are Metaclasses in Python?Metaclasses are responsible for creating class objects in Python. Just as classes create instances, metaclasses create ...Programming Posted on 2025-07-02
-
How to Combine Data from Three MySQL Tables into a New Table?mySQL: Creating a New Table from Data and Columns of Three TablesQuestion:How can I create a new table that combines selected data from three existing...Programming Posted on 2025-07-02
-
Async Void vs. Async Task in ASP.NET: Why does the Async Void method sometimes throw exceptions?Understanding the Distinction Between Async Void and Async Task in ASP.NetIn ASP.Net applications, asynchronous programming plays a crucial role in en...Programming Posted on 2025-07-02
-
User local time format and time zone offset display guideDisplaying Date/Time in User's Locale Format with Time OffsetWhen presenting dates and times to end-users, it's crucial to display them in the...Programming Posted on 2025-07-02
-
How to efficiently detect empty arrays in PHP?Checking Array Emptiness in PHPAn empty array can be determined in PHP through various approaches. If the need is to verify the presence of any array ...Programming Posted on 2025-07-02
-
How Can I Efficiently Read a Large File in Reverse Order Using Python?Reading a File in Reverse Order in PythonIf you're working with a large file and need to read its contents from the last line to the first, Python...Programming Posted on 2025-07-02
-
How to Convert a Pandas DataFrame Column to DateTime Format and Filter by Date?Transform Pandas DataFrame Column to DateTime FormatScenario:Data within a Pandas DataFrame often exists in various formats, including strings. When w...Programming Posted on 2025-07-02















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









