
How to Convert PDFs to Markdown Using PyMuPDFM and Its Evaluation
 Browse:467
Browse:467
PyMuPDF4LLM is a library designed to convert PDFs into Markdown format. Here, I’ll share my experience testing this library.
Installation
Start by installing the library using the following command:
pip install pymupdf4llm
Usage
The basic usage is quite simple, requiring just three lines of code to convert a PDF to Markdown:
import pymupdf4llm
md_text = pymupdf4llm.to_markdown("input.pdf")
print(md_text)
You can specify arguments to adjust how content is extracted.
Extracting Text by Page
By default, the entire PDF is converted into a single text output. However, you can extract text page by page by specifying page_chunks=True.
md_text = pymupdf4llm.to_markdown("input.pdf", page_chunks=True)
Extracting Images
To extract images as files, use the write_images=True option:
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
It’s also possible to embed images directly in the Markdown using base64 encoding:
md_text = pymupdf4llm.to_markdown("input.pdf", embed_images=True)
Evaluation of Conversion Results
For testing, various PDFs with different Markdown elements were used.

Header Conversion
Headers are correctly converted into Markdown format. Here is a portion of the result:
# Sample Markdown Guide This is a sample markdown file that includes various features for quick reference. ## 1. Headers ... ## 3. Lists
Bold and Italic Text
Bold and italic formatting is also properly converted:
**Bold: **Bold Text**** _Italic: *Italic Text*_ **_Bold and Italic: ***Bold and Italic***_**
List Conversion
Ordered lists at the first level are converted without issues, but nested lists and unordered lists are not accurately converted.
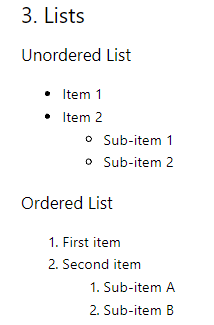
## 3. Lists ### Unordered List Item 1 Item 2 Sub-item 1 Sub-item 2 ### Ordered List 1. First item 2. Second item 1. Sub-item A 2. Sub-item B
Link Conversion
The URLs of links are extracted, but the entire line containing the link becomes a hyperlink, deviating from the original format.
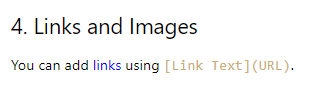
## 4. Links and Images [You can add links using [Link Text](URL).](https://www.example.com/)
Image Extraction
Images are not extracted by default but can be saved locally with write_images=True.
md_text = pymupdf4llm.to_markdown("input.pdf", write_images=True)
The saved images are then referenced in the Markdown as follows:
### Image Example

Table Conversion
Simple tables without vertical borders are not accurately converted (likely because ambiguous column boundaries result in tables being treated as plain text).

## 5. Tables
**Column 1** **Column 2** **Column 3**
Row 1 Data A Data B
Row 2 Data C Data D
Code Conversion
Code blocks are correctly converted, but language specification (e.g., python) is not retained. Inline code conversion also has issues.

## 6. Code
### Inline Code
Use backticks for inline code: print("Hello, world!")
### Code Block
Use triple backticks for code blocks:
```
def greet(name):
return f"Hello, {name}!"
print(greet("Markdown"))
```
Multi-Line Text
For multi-line text, the line breaks are preserved as they appear in the original PDF.

Markdown is a lightweight and versatile markup language favored by developers, writers, and bloggers alike
due to its simplicity in formatting text, enabling users to create readable and well-structured documents—
whether for documentation, blog posts, or articles—without the complexity of HTML, while also offering the
ability to convert content seamlessly into other formats like HTML, PDF, and even slideshows, making it an
ideal choice for projects that require both clarity and flexibility in presentation.
Conclusion
Despite challenges in accurately converting lists and links, PyMuPDF4LLM is a useful tool for converting PDFs to Markdown. It can work locally without the need for external language models, making it suitable for environments where internet access is unavailable.
-
 How to Redirect Multiple User Types (Students, Teachers, and Admins) to Their Respective Activities in a Firebase App?Red: How to Redirect Multiple User Types to Respective ActivitiesUnderstanding the ProblemIn a Firebase-based voting app with three distinct user type...Programming Posted on 2025-07-01
How to Redirect Multiple User Types (Students, Teachers, and Admins) to Their Respective Activities in a Firebase App?Red: How to Redirect Multiple User Types to Respective ActivitiesUnderstanding the ProblemIn a Firebase-based voting app with three distinct user type...Programming Posted on 2025-07-01 -
Do I Need to Explicitly Delete Heap Allocations in C++ Before Program Exit?Explicit Deletion in C Despite Program ExitWhen working with dynamic memory allocation in C , developers often wonder if it's necessary to manu...Programming Posted on 2025-07-01
-
How to Capture and Stream stdout in Real Time for Chatbot Command Execution?Capturing stdout in Real Time from Command ExecutionIn the realm of developing chatbots capable of executing commands, a common requirement is the abi...Programming Posted on 2025-07-01
-
When to use "try" instead of "if" to detect variable values in Python?Using "try" vs. "if" to Test Variable Value in PythonIn Python, there are situations where you may need to check if a variable has...Programming Posted on 2025-07-01
-
PHP Future: Adaptation and InnovationThe future of PHP will be achieved by adapting to new technology trends and introducing innovative features: 1) Adapting to cloud computing, container...Programming Posted on 2025-07-01
-
How to Implement a Generic Hash Function for Tuples in Unordered Collections?Generic Hash Function for Tuples in Unordered CollectionsThe std::unordered_map and std::unordered_set containers provide efficient lookup and inserti...Programming Posted on 2025-07-01
-
How does Android send POST data to PHP server?Sending POST Data in AndroidIntroductionThis article addresses the need to send POST data to a PHP script and display the result in an Android applica...Programming Posted on 2025-07-01
-
Async Void vs. Async Task in ASP.NET: Why does the Async Void method sometimes throw exceptions?Understanding the Distinction Between Async Void and Async Task in ASP.NetIn ASP.Net applications, asynchronous programming plays a crucial role in en...Programming Posted on 2025-07-01
-
Why Am I Getting a \"Class \'ZipArchive\' Not Found\" Error After Installing Archive_Zip on My Linux Server?Class 'ZipArchive' Not Found Error While Installing Archive_Zip on Linux ServerSymptom:When attempting to run a script that utilizes the ZipAr...Programming Posted on 2025-07-01
-
How Can I UNION Database Tables with Different Numbers of Columns?Combined tables with different columns] Can encounter challenges when trying to merge database tables with different columns. A straightforward way i...Programming Posted on 2025-07-01
-
How Can You Define Variables in Laravel Blade Templates Elegantly?Defining Variables in Laravel Blade Templates with EleganceUnderstanding how to assign variables in Blade templates is crucial for storing data for la...Programming Posted on 2025-07-01
-
User local time format and time zone offset display guideDisplaying Date/Time in User's Locale Format with Time OffsetWhen presenting dates and times to end-users, it's crucial to display them in the...Programming Posted on 2025-07-01
-
MySQL database method is not required to dump the same instanceCopying a MySQL Database on the Same Instance without DumpingCopying a database on the same MySQL instance can be done without having to create an int...Programming Posted on 2025-07-01
-
Spark DataFrame tips to add constant columnsCreating a Constant Column in a Spark DataFrameAdding a constant column to a Spark DataFrame with an arbitrary value that applies to all rows can be a...Programming Posted on 2025-07-01
-
How to Simplify JSON Parsing in PHP for Multi-Dimensional Arrays?Parsing JSON with PHPTrying to parse JSON data in PHP can be challenging, especially when dealing with multi-dimensional arrays. To simplify the proce...Programming Posted on 2025-07-01















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









