
Building a RAG app with LlamaIndex.ts and Azure OpenAI: Getting started!
 Browse:606
Browse:606
As AI continues to shape the way we work and interact with technology, many businesses are looking for ways to leverage their own data within intelligent applications. If you've used tools like ChatGPT or Azure OpenAI, you're already familiar with how generative AI can improve processes and enhance user experiences. However, for truly customized and relevant responses, your applications need to incorporate your proprietary data.
This is where Retrieval-Augmented Generation (RAG) comes in, providing a structured approach to integrating data retrieval with AI-powered responses. With frameworks like LlamaIndex, you can easily build this capability into your solutions, unlocking the full potential of your business data.
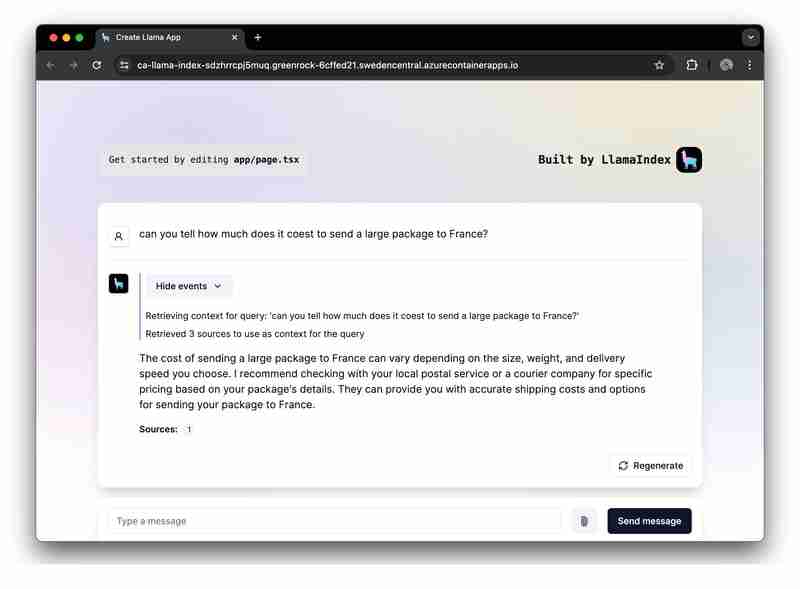
Want to quickly run and explore the app? Click here.
What is RAG - Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is a neural network framework that enhances AI text generation by including a retrieval component to access relevant information and integrate your own data. It consists of two main parts:
- Retriever: A dense retriever model (e.g., based on BERT) that searches a large corpus of documents to find relevant passages or information related to a given query.
- Generator: A sequence-to-sequence model (e.g., based on BART or T5) that takes the query and the retrieved text as input and generates a coherent, contextually enriched response.
The retriever finds relevant documents, and the generator uses them to create more accurate and informative responses. This combination allows the RAG model to leverage external knowledge effectively, improving the quality and relevance of the generated text.
How does LlamaIndex implement RAG?
To implement a RAG system using LlamaIndex, follow these general steps:
Data Ingestion:
- Load your documents into LlamaIndex.ts using a document loader such as SimpleDirectoryReader, which helps in importing data from various sources like PDFs, APIs, or SQL databases.
- Break down large documents into smaller, manageable chunks using the SentenceSplitter.
Index Creation:
- Create a vector index of these document chunks using VectorStoreIndex, allowing efficient similarity searches based on embeddings.
- Optionally, for complex datasets, use recursive retrieval techniques to manage hierarchically structured data and retrieve relevant sections based on user queries.
Query Engine Setup:
- Convert the vector index into a query engine using asQueryEngine with parameters such as similarityTopK to define how many top documents should be retrieved.
- For more advanced setups, create a multi-agent system where each agent is responsible for specific documents, and a top-level agent coordinates the overall retrieval process.
Retrieval and Generation:
- Implement the RAG pipeline by defining an objective function that retrieves relevant document chunks based on user queries.
- Use the RetrieverQueryEngine to perform the actual retrieval and query processing, with optional post-processing steps like re-ranking the retrieved documents using tools such as CohereRerank.
For a practical example, we have provided a sample application to demonstrate a complete RAG implementation using Azure OpenAI.
Practical RAG Sample Application
We'll now focus on building a RAG application using LlamaIndex.ts (the TypeScipt implementation of LlamaIndex) and Azure OpenAI, and deploy on it as a serverless Web Apps on Azure Container Apps.
Requirements to Run the Sample
- Azure Developer CLI (azd): A command-line tool to easily deploy your entire app, including backend, frontend, and databases.
- Azure Account: You'll need an Azure account to deploy the application. Get a free Azure account with some credits to get started.
You will find the getting started project on GitHub. We recommend you to fork this template so you can freely edit it when needed:

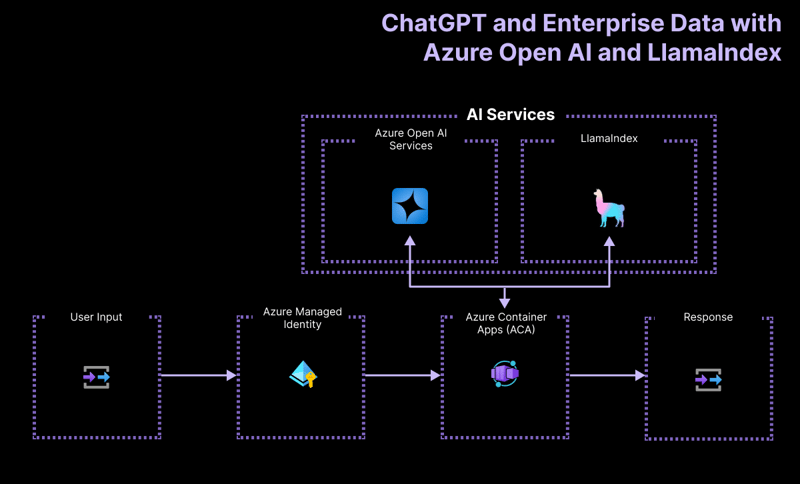
High-Level Architecture
The getting started project application is built based on the following architecture:
- Azure OpenAI: The AI provider that processes the user's queries.
- LlamaIndex.ts: The framework that helps ingest, transform, and vectorize content (PDFs) and create a search index.
- Azure Container Apps: The container environment where the serverless application is hosted.
- Azure Managed Identity: Ensures top-notch security and eliminates the need for handling credentials and API keys.
For more details on what resources are deployed, check the infra folder available in all our samples.
Example User Workflows
The sample application contains logic for two workflows:
-
Data Ingestion: Data is fetched, vectorized, and search indexes are created. If you want to add more files like PDFs or Word files, this is where you should add them.
npm run generate
Serving Prompt Requests: The app receives user prompts, sends them to Azure OpenAI, and augments these prompts using the vector index as a retriever.
Running the Sample
Before running the sample, ensure you have provisioned the necessary Azure resources.
To run the GitHub template in GitHub Codespace, simply click
In your Codespaces instance, sign into your Azure account, from your terminal:
azd auth login
Provision, package, and deploy the sample application to Azure using a single command:
azd up
To run and try the application locally, install the npm dependencies and run the app:
npm install npm run dev
The app will run on port 3000 in your Codespaces instance or at http://localhost:3000 in your browser.
Conclusion
This guide demonstrated how to build a serverless RAG (Retrieval-Augmented Generation) application using LlamaIndex.ts and Azure OpenAI, deployed on Microsoft Azure. By following this guide, you can leverage Azure's infrastructure and LlamaIndex's capabilities to create powerful AI applications that provide contextually enriched responses based on your data.
We’re excited to see what you build with this getting started application. Feel free to fork it and like the GitHub repository to receive the latest updates and features.
-
 How Can I Customize Compilation Optimizations in the Go Compiler?Customizing Compilation Optimizations in Go CompilerThe default compilation process in Go follows a specific optimization strategy. However, users may...Programming Posted on 2025-04-12
How Can I Customize Compilation Optimizations in the Go Compiler?Customizing Compilation Optimizations in Go CompilerThe default compilation process in Go follows a specific optimization strategy. However, users may...Programming Posted on 2025-04-12 -
How Can I UNION Database Tables with Different Numbers of Columns?Combined tables with different columns] Can encounter challenges when trying to merge database tables with different columns. A straightforward way i...Programming Posted on 2025-04-12
-
How Can I Synchronously Iterate and Print Values from Two Equal-Sized Arrays in PHP?Synchronously Iterating and Printing Values from Two Arrays of the Same SizeWhen creating a selectbox using two arrays of equal size, one containing c...Programming Posted on 2025-04-12
-
Why Does PHP's DateTime::modify('+1 month') Produce Unexpected Results?Modifying Months with PHP DateTime: Uncovering the Intended BehaviorWhen working with PHP's DateTime class, adding or subtracting months may not a...Programming Posted on 2025-04-12
-
How Can I Execute Command Prompt Commands, Including Directory Changes, in Java?Execute Command Prompt Commands in JavaProblem:Running command prompt commands through Java can be challenging. Although you may find code snippets th...Programming Posted on 2025-04-12
-
Python Read CSV File UnicodeDecodeError Ultimate SolutionUnicode Decode Error in CSV File ReadingWhen attempting to read a CSV file into Python using the built-in csv module, you may encounter an error stati...Programming Posted on 2025-04-12
-
How can I safely concatenate text and values when constructing SQL queries in Go?Concatenating Text and Values in Go SQL QueriesWhen constructing a text SQL query in Go, there are certain syntax rules to follow when concatenating s...Programming Posted on 2025-04-12
-
How do you extract a random element from an array in PHP?Random Selection from an ArrayIn PHP, obtaining a random item from an array can be accomplished with ease. Consider the following array:$items = [523,...Programming Posted on 2025-04-12
-
How to Implement a Generic Hash Function for Tuples in Unordered Collections?Generic Hash Function for Tuples in Unordered CollectionsThe std::unordered_map and std::unordered_set containers provide efficient lookup and inserti...Programming Posted on 2025-04-12
-
Why Doesn\'t Firefox Display Images Using the CSS `content` Property?Displaying Images with Content URL in FirefoxAn issue has been encountered where certain browsers, specifically Firefox, fail to display images when r...Programming Posted on 2025-04-12
-
How to Parse JSON Arrays in Go Using the `json` Package?Parsing JSON Arrays in Go with the JSON PackageProblem: How can you parse a JSON string representing an array in Go using the json package?Code Exampl...Programming Posted on 2025-04-12
-
Why Am I Getting a \"Class \'ZipArchive\' Not Found\" Error After Installing Archive_Zip on My Linux Server?Class 'ZipArchive' Not Found Error While Installing Archive_Zip on Linux ServerSymptom:When attempting to run a script that utilizes the ZipAr...Programming Posted on 2025-04-12
-
How to Capture and Stream stdout in Real Time for Chatbot Command Execution?Capturing stdout in Real Time from Command ExecutionIn the realm of developing chatbots capable of executing commands, a common requirement is the abi...Programming Posted on 2025-04-12
-
How to Send a Raw POST Request with cURL in PHP?How to Send a Raw POST Request Using cURL in PHPIn PHP, cURL is a popular library for sending HTTP requests. This article will demonstrate how to use ...Programming Posted on 2025-04-12
-
How does Android send POST data to PHP server?Sending POST Data in AndroidIntroductionThis article addresses the need to send POST data to a PHP script and display the result in an Android applica...Programming Posted on 2025-04-12















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









