
Building Ollama Cloud - Scaling Local Inference to the Cloud
 Browse:548
Browse:548
Ollama is primarily a wrapper around llama.cpp, designed for local inference tasks. It's not typically your first choice if you're looking for cutting-edge performance or features, but it has its uses, especially in environments where external dependencies are a concern.
Local AI Development
When using Ollama for local AI development, the setup is straightforward but effective. Developers typically leverage Ollama to run inference tasks directly on their local machines. Here's a visual depiction of a typical local development setup using Ollama:

This configuration allows developers to test and iterate quickly without the complexities of remote server communications. It's ideal for initial prototyping and development phases where quick turnaround is critical.
From Local to Cloud
Transitioning from a local setup to a scalable cloud environment involves evolving from a simple 1:1 setup (one user request to one inference host) to a more complex many-to-many (multiple user requests to multiple inference hosts) configuration. This shift is necessary to maintain efficiency and responsiveness as demand increases.
Here's how this scaling looks when moving from local development to production:
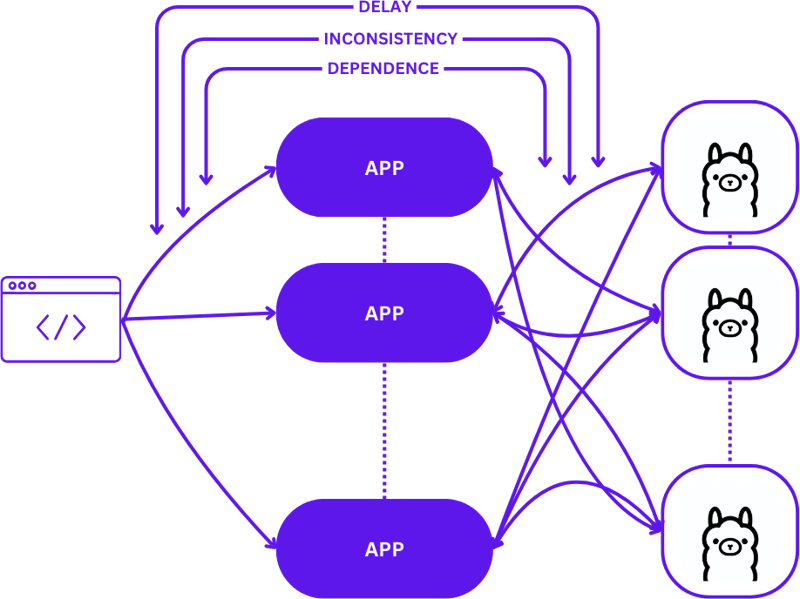
Adopting a straightforward approach during this transition can significantly increase the complexity of applications, especially as sessions need to maintain consistency across various states. Delays and inefficiencies may arise if requests are not optimally routed to the best available inference host.
Moreover, the complex nature of distributed applications makes them challenging to test locally, which can slow down the development process and increase the risk of failures in production environments.
Serverless
Serverless computing abstracts server management and infrastructure details, allowing developers to focus solely on code and business logic. By decoupling request handling and consistency maintenance from the application, serverless architecture simplifies scaling.
This approach allows the application to remain concentrated on delivering value, solving many common scaling challenges without burdening developers with infrastructure complexities.
WebAssembly
WebAssembly (Wasm) addresses the challenge of dependency management by enabling the compilation of applications into self-contained modules. This makes apps easier to orchestrate and test both locally and in the cloud, ensuring consistency across different environments.
Tau
Tau is a framework to build low-maintenance and highly scalable cloud computing platforms. It excels in simplicity and extendibility. Tau makes deployment straightforward and supports running a local cloud for development, allowing for end-to-end (E2E) testing of both the cloud infrastructure and the applications running on it.
This approach, referred to by Taubyte as "Local Coding Equals Global Production," ensures that what works locally will work globally, significantly easing the development and deployment processes.
Integrating Ollama into Tau with the Orbit Plugin System
Tau’s plugin system, known as Orbit, significantly simplifies turning services into manageable components by wrapping them into WebAssembly host modules. This approach allows Tau to take over the orchestration duties, streamlining the deployment and management process.
Exporting Functions in Ollama
To make Ollama functions accessible within Tau’s ecosystem, we utilize the Orbit system to export Ollama’s capabilities as callable endpoints. Here’s how you can export an endpoint in Go:
func (s *ollama) W_pull(ctx context.Context, module satellite.Module, modelNamePtr uint32, modelNameSize uint32, pullIdptr uint32) Error {
model, err := module.ReadString(modelNamePtr, modelNameSize)
if err != nil {
return ErrorReadMemory
}
id, updateFunc := s.getPullId(model)
if updateFunc != nil {
go func() {
err = server.PullModel(s.ctx, model, &server.RegistryOptions{}, updateFunc)
s.pullLock.Lock()
defer s.pullLock.Unlock()
s.pulls[id].err = err
}()
}
module.WriteUint64(pullIdptr, id)
return ErrorNone
}
For a straightforward example of exporting functions, you can refer to the hello_world example.
Once defined, these functions, now called via satellite.Export, enable the seamless integration of Ollama into Tau’s environment:
func main() {
server := new(context.TODO(), "/tmp/ollama-wasm")
server.init()
satellite.Export("ollama", server)
}
Writing Tests for the Ollama Plugin
Testing the plugin is streamlined and straightforward. Here's how you can write a serverless function test in Go:
//export pull
func pull() {
var id uint64
err := Pull("gemma:2b-instruct", &id)
if err != 0 {
panic("failed to call pull")
}
}
Using Tau's test suite and Go builder tools, you can build your plugin, deploy it in a test environment, and execute the serverless functions to verify functionality:
func TestPull(t *testing.T) {
ctx := context.Background()
// Create a testing suite to test the plugin
ts, err := suite.New(ctx)
assert.NilError(t, err)
// Use a Go builder to build plugins and wasm
gob := builder.New()
// Build the plugin from the directory
wd, _ := os.Getwd()
pluginPath, err := gob.Plugin(path.Join(wd, "."), "ollama")
assert.NilError(t, err)
// Attach plugin to the testing suite
err = ts.AttachPluginFromPath(pluginPath)
assert.NilError(t, err)
// Build a wasm file from serverless function
wasmPath, err := gob.Wasm(ctx, path.Join(wd, "fixtures", "pull.go"), path.Join(wd, "fixtures", "common.go"))
assert.NilError(t, err)
// Load the wasm module and call the function
module, err := ts.WasmModule(wasmPath)
assert.NilError(t, err)
// Call the "pull" function from our wasm module
_, err = module.Call(ctx, "pull")
assert.NilError(t, err)
}
Code
You can find the complete code here https://github.com/ollama-cloud/ollama-as-wasm-plugin/tree/main/tau
What's Next?
You can now build LLM applications with ease. Here are the steps to get started:
- Start locally using dream: Set up your local environment to develop and test your application.
- Create a project: Begin a new project with Tau to harness its full potential.
- Create your production cloud: Deploy your project in a production cloud environment.
- Drop the plugin binary in the /tb/plugins folder.
- Import your project into production
- Show off!
-
 Why Isn\'t Padding Working in Safari and IE Select Lists?Padding Not Displaying in Select Lists in Safari and IEDespite the lack of restrictions in the W3 specification, padding in select boxes is not suppor...Programming Published on 2024-11-05
Why Isn\'t Padding Working in Safari and IE Select Lists?Padding Not Displaying in Select Lists in Safari and IEDespite the lack of restrictions in the W3 specification, padding in select boxes is not suppor...Programming Published on 2024-11-05 -
The Ultimate Guide to Create Custom Annotations in Spring BootSuch annotations fill the entire project in Spring Boot. But do you know what problems these annotations solve? Why were custom annotations introduce...Programming Published on 2024-11-05
-
Why Elixir is better than Node.js for Asynchronous Processing?Simple answer: Node.js is single-threaded and splits that single thread to simulate concurrency, while Elixir takes advantage of the concurrency and p...Programming Published on 2024-11-05
-
How Can AngularJS $watch Replace Timers in Dynamic Navigation Height Adjustment?Avoiding Timers in Height Watching for AngularJSAngularJS programmers often face the challenge of responsive navigation when the navigation height is ...Programming Published on 2024-11-05
-
Go from Zero to Web Developer: Mastering the Fundamentals of PHPMastering the basics of PHP is essential: Install PHP Create PHP files Run code Understand variables and data types Use expressions and operators Cre...Programming Published on 2024-11-05
-
Buffers: Node.jsSimple Guide to Buffers in Node.js A Buffer in Node.js is used to handle raw binary data, which is useful when working with streams, files, o...Programming Published on 2024-11-05
-
Mastering Version Management in Node.jsAs developers, we frequently encounter projects that demand different Node.js versions. This scenario is a pitfall for both fresh and experienced deve...Programming Published on 2024-11-05
-
How to Embed Git Revision Information in Go Binaries for Troubleshooting?Determining Git Revision in Go BinariesWhen deploying code, it can be helpful to associate binaries with the git revision they were built from for tro...Programming Published on 2024-11-05
-
Common HTML Tags: A erspectiveHTML (HyperText Markup Language) forms the foundation of web development, serving as the structure for every webpage on the internet. By understanding...Programming Published on 2024-11-05
-
CSS Media QueriesEnsuring that websites function seamlessly across various devices is more critical than ever. With users accessing websites from desktops, laptops, ta...Programming Published on 2024-11-05
-
Understanding Hoisting in JavaScript: A Comprehensive GuideHoisting in JavaScript Hoisting is a behavior in which variable and function declarations are moved (or "hoisted") to the top of th...Programming Published on 2024-11-05
-
Integrating Stripe Into A One-Product Django Python ShopIn the first part of this series, we created a Django online shop with htmx. In this second part, we'll handle orders using Stripe. What We'll...Programming Published on 2024-11-05
-
Tips for testing queued jobs in LaravelWhen working with Laravel applications, it’s common to encounter scenarios where a command needs to perform an expensive task. To avoid blocking the m...Programming Published on 2024-11-05
-
How to create a Human-Level Natural Language Understanding (NLU) SystemScope: Creating an NLU system that fully understands and processes human languages in a wide range of contexts, from conversations to literature. ...Programming Published on 2024-11-05
-
How to Iterate an ArrayList Inside a HashMap Using JSTL?Iterating an ArrayList Inside a HashMap Using JSTLIn web development, JSTL (JavaServer Pages Standard Tag Library) provides a set of tags for simplify...Programming Published on 2024-11-05















Study Chinese
- 1 How do you say "walk" in Chinese? 走路 Chinese pronunciation, 走路 Chinese learning
- 2 How do you say "take a plane" in Chinese? 坐飞机 Chinese pronunciation, 坐飞机 Chinese learning
- 3 How do you say "take a train" in Chinese? 坐火车 Chinese pronunciation, 坐火车 Chinese learning
- 4 How do you say "take a bus" in Chinese? 坐车 Chinese pronunciation, 坐车 Chinese learning
- 5 How to say drive in Chinese? 开车 Chinese pronunciation, 开车 Chinese learning
- 6 How do you say swimming in Chinese? 游泳 Chinese pronunciation, 游泳 Chinese learning
- 7 How do you say ride a bicycle in Chinese? 骑自行车 Chinese pronunciation, 骑自行车 Chinese learning
- 8 How do you say hello in Chinese? 你好Chinese pronunciation, 你好Chinese learning
- 9 How do you say thank you in Chinese? 谢谢Chinese pronunciation, 谢谢Chinese learning
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









