
وقت المغادرة؟ حان الوقت لإعادة البناء! صنع تويتر
 تصفح:426
تصفح:426
The most critical features of a new social network for users fed up with Musk and Twitter, are as follows;
- Import Twitter's archive.zip file
- Easy as possible to sign up
- Similar if not identical user features
Less critical but definitely helpful features of the platform;
- Ethically monetised and moderated
- Make use of AI to help identify problematic content
- Blue tick with the use of Onfido or SMART identity services
In this post, we'll focus on the first feature. Importing Twitter's archive.zip file.
The file
Twitter haven't made your data all that easy to obtain. It's great that they give you access to it (legally, they have to). The format is crap.
It actually comes as a mini web archive and all your data is stuck in JavaScript files. It is more of a web app than convenient storage of data.
When you open up the Your archive.html file you get something like this;
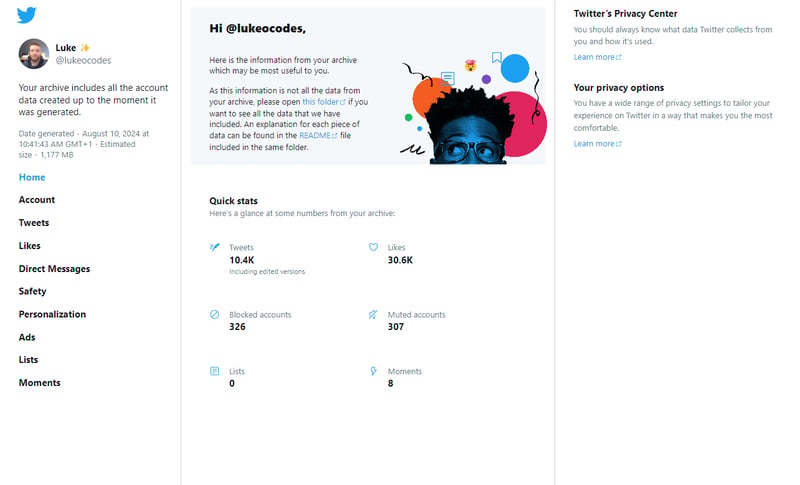
Note: I made the descision pretty early on to build using Next.js for the site, Go and GraphQL for the backend.
So, what do you do when your data isn't structured data?
Well, you parse it.
Creating a basic Go script
Head on over to the official docs on how to get started with Go, and set up your project directory.
We're going to hack this process together. It seems one of the most important features to attract people who feel too attached to TwitterX.
First step is to create a main.go file. In this file we'll GO (hah) and do some STUFF;
- os.Args: This is a slice that holds command-line arguments.
- os.Args[0] is the program's name, and os.Args[1] is the first argument passed to the program.
- Argument Check: The function checks if at least one argument is provided. If not, it prints a message asking for a path.
- run function: This function simply prints the path passed to it, for now.
package main
import (
"fmt"
"os"
)
func run(path string) {
fmt.Println("Path:", path)
}
func main() {
if len(os.Args)
At every step, we'll run the file like so;
go run main.go twitter.zip
If you don't have a Twitter archive export, create a simple manifest.js file and give it the following JavaScript.
window.__THAR_CONFIG = {
"userInfo" : {
"accountId" : "1234567890",
"userName" : "lukeocodes",
"displayName" : "Luke ✨"
},
};
Compress that into your twitter.zip file that we'll use throughout.
Read a Zip file
The next step is to read the contents of the zip file. We want to do this as efficiently as possible, and reduce time data is extracted on the disk.
There are many files in the zip that don't need to be extracted, too.
We'll edit the main.go file;
- Opening the ZIP file: The zip.OpenReader() function is used to open the ZIP file specified by path.
- Iterating through the files: The function loops over each file in the ZIP archive using r.File, which is a slice of zip.File. The Name property of each file is printed.
package main
import (
"archive/zip"
"fmt"
"log"
"os"
)
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("Files in the zip archive:")
for _, f := range r.File {
fmt.Println(f.Name)
}
}
func main() {
// Example usage
if len(os.Args)
JS only! We're hunting structured data
This archive file is seriously unhelpful. We want to check for just .js files, and only in the /data directory.
- Opening the ZIP file: The ZIP file is opened using zip.OpenReader().
- Checking the /data directory: The program iterates through the files in the ZIP archive. It uses strings.HasPrefix(f.Name, "data/") to check if the file resides in the /data directory.
- Finding .js files: The program also checks if the file has a .js extension using filepath.Ext(f.Name).
- Reading and printing contents: If a .js file is found in the /data directory, the program reads and prints its contents.
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Print the contents
fmt.Printf("Contents of %s:\n", file.Name)
fmt.Println(string(contents))
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args)
Parse the JS! We want that data
We've found the structured data. Now we need to parse it. The good news is there are existing packages for using JavaScript inside Go. We'll be using goja.
If you're on this section, familiar with Goja, and you've seen the output of the file, you may see we're going to have errors in our future.
Install goja:
go get github.com/dop251/goja
Now we're going to edit the main.go file to do the following;
- Parsing with goja: The goja.New() function creates a new JavaScript runtime, and vm.RunString(processedContents) runs the processed JavaScript code within that runtime.
- Handle errors in parsing
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"strings"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated? :/
if err != nil {
log.Fatal(err)
}
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(contents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
fmt.Printf("Parsed JavaScript file: %s\n", file.Name)
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
fmt.Println("JavaScript files in the zip archive:")
for _, f := range r.File {
// Use filepath.Ext to check the file extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args)
SUPRISE. window is not defined might be a familiar error. Basically goja runs an EMCA runtime. window is browser context and sadly unavailable.
ACTUALLY Parse the JS
I went through a few issues at this point. Including not being able to return data because it's a top level JS file.
Long story short, we need to modify the contents of the files before loading them into the runtime.
Let's modify the main.go file;
- reConfig: A regex that matches any assignment of the form window.someVariable = { and replaces it with var data = {.
- reArray: A regex that matches any assignment of the form window.someObject.someArray = [ and replaces it with var data = [
- Extracting data: Running the script, we use vm.Get("data") to retrieve the value of the data variable from the JavaScript context.
package main
import (
"archive/zip"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc)
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w \s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w \.\w \.\w \s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Output the parsed data
fmt.Printf("Processed JavaScript file: %s\n", file.Name)
fmt.Printf("Data extracted: %v\n", value.Export())
}
func run(path string) {
// Open the zip file
r, err := zip.OpenReader(path)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file so we don't end up printing a gazillion lines when testing
}
}
}
func main() {
// Example usage
if len(os.Args)
Hurrah. Assuming I didn't muck up the copypaste into this post, you should now see a rather ugly print of the struct data from Go.
JSON would be nice
Edit the main.go file to marshall the JSON output.
- Use value.Export() to get the data from the struct
- Use json.MarshallIndent() for pretty printed JSON (use json.Marshall if you want to minify the output).
package main
import (
"archive/zip"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
"path/filepath"
"regexp"
"strings"
"github.com/dop251/goja"
)
func readFile(file *zip.File) {
// Open the file inside the zip
rc, err := file.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
// Read the contents of the file
contents, err := ioutil.ReadAll(rc) // deprecated :/
if err != nil {
log.Fatal(err)
}
// Regular expressions to replace specific patterns
reConfig := regexp.MustCompile(`window\.\w \s*=\s*{`)
reArray := regexp.MustCompile(`window\.\w \.\w \.\w \s*=\s*\[`)
// Replace patterns in the content
processedContents := reConfig.ReplaceAllStringFunc(string(contents), func(s string) string {
return "var data = {"
})
processedContents = reArray.ReplaceAllStringFunc(processedContents, func(s string) string {
return "var data = ["
})
// Parse the JavaScript file using goja
vm := goja.New()
_, err = vm.RunString(processedContents)
if err != nil {
log.Fatalf("Error parsing JS file: %v", err)
}
// Retrieve the value of the 'data' variable from the JavaScript context
value := vm.Get("data")
if value == nil {
log.Fatalf("No data variable found in the JS file")
}
// Convert the data to a Go-native type
data := value.Export()
// Marshal the Go-native type to JSON
jsonData, err := json.MarshalIndent(data, "", " ")
if err != nil {
log.Fatalf("Error marshalling data to JSON: %v", err)
}
// Output the JSON data
fmt.Println(string(jsonData))
}
func run(zipFilePath string) {
// Open the zip file
r, err := zip.OpenReader(zipFilePath)
if err != nil {
log.Fatal(err)
}
defer r.Close()
// Iterate through the files in the zip archive
for _, f := range r.File {
// Check if the file is in the /data directory and has a .js extension
if strings.HasPrefix(f.Name, "data/") && strings.ToLower(filepath.Ext(f.Name)) == ".js" {
readFile(f)
return // Exit after processing the first .js file
}
}
}
func main() {
// Example usage
if len(os.Args)
That's it!
go run main.go twitter.zip
}
"userInfo": {
"accountId": "1234567890",
"displayName": "Luke ✨",
"userName": "lukeocodes"
}
}
Open source
I'll be open sourcing a lot of this work so that others who want to parse the data from the archive, can store it how they like.
-
 الحقيقة حول تغطية الاختبارحقيقة قوية. انظر إلى الكود التالي البسيط والمباشر: function sum(a, b) { return a b; } الآن، دعونا نكتب بعض الاختبارات له: test('sum', ...برمجة تم النشر بتاريخ 2024-11-06
الحقيقة حول تغطية الاختبارحقيقة قوية. انظر إلى الكود التالي البسيط والمباشر: function sum(a, b) { return a b; } الآن، دعونا نكتب بعض الاختبارات له: test('sum', ...برمجة تم النشر بتاريخ 2024-11-06 -
لماذا لا يتم عرض مثلث OpenGL الخاص بي في Go؟ التحقيق في مشكلة Vertex Buffer.مشكلة المخزن المؤقت لـ OpenGL Vertex في Go في محاولة لعرض مثلث باستخدام OpenGL في Go، واجه المستخدم مشكلة في قمة الرأس فشل المخزن المؤقت في تقد...برمجة تم النشر بتاريخ 2024-11-06
-
لماذا يؤدي تعيين `ulimit -n` من برنامج Go على توزيعات Linux 32 بت إلى خطأ \"وسيطة غير صالحة\"؟كيفية تعيين ulimit -n من برنامج Go؟ مشكلة حاول مستخدم تعيين ulimit -n من داخل برنامج Go إلى قم بتقييده داخل البرنامج وليس عالميًا، باستخدام اس...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية إنشاء قواميس متداخلة ديناميكيًا بعمق غير محدود في بايثون؟قواميس متداخلة ديناميكيًا ذات عمق غير محدد في السيناريوهات التي تتضمن هياكل بيانات معقدة متعددة المستويات، غالبًا ما تكون هناك حاجة إلى قواميس...برمجة تم النشر بتاريخ 2024-11-06
-
لغة بايثون أصبحت قوية: دليل المبتدئين للبرمجة بدون جهدبايثون هي لغة برمجة قوية ذات بناء جملة بسيط وتطبيق واسع. بعد تثبيت بايثون، يمكنك معرفة تركيبها الأساسي، بما في ذلك تخصيص المتغيرات، وأنواع البيانات، و...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية الاستماع إلى الأحداث على العناصر التي تم إنشاؤها ديناميكيًا بدون jQuery؟الاستماع إلى الأحداث على العناصر التي تم إنشاؤها ديناميكيًا بدون jQuery عند العمل مع الصفحات الخارجية، قد يكون من الصعب إضافة مستمعي الأحداث إلى...برمجة تم النشر بتاريخ 2024-11-06
-
تحسين كفاءة القوى العاملة باستخدام نظام إدارة الحضور المتقدم من Snipbyteفي مشهد الأعمال اليوم، يمكن لإدارة حضور الموظفين، والتحولات، وكشوف المرتبات بكفاءة أن تؤدي إلى نجاح المؤسسة أو فشلها. لا يضمن تتبع الحضور الدقيق س...برمجة تم النشر بتاريخ 2024-11-06
-
دروس طرق مصادقة LaravelLaravel auth routes is one of the essential features of the Laravel framework. Using middlewares you can implement different authentication strategies...برمجة تم النشر بتاريخ 2024-11-06
-
كيف يمكنني الانتقال بكفاءة إلى سطر معين في ملف نصي كبير؟تحسين القفز بين الأسطر في الملفات النصية الكبيرة: نهج بديل عند معالجة ملفات نصية ضخمة ذات أسطر ذات أطوال مختلفة، غالبًا ما يكون من غير الفعال ...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية استرداد قيم خصائص CSS لعناصر HTML في JavaScript؟الحصول على قيم خصائص CSS لعناصر HTML في JavaScript في تطوير الويب، يمكن أن يؤدي التعامل مع خصائص CSS ديناميكيًا إلى تحسين تجربة المستخدم والواجه...برمجة تم النشر بتاريخ 2024-11-06
-
DBMS_OUTPUT.PUT_LINE في PLSQLفي Oracle PL/SQL، طريقة طباعة المخرجات هي استخدام إجراء DBMS_OUTPUT.PUT_LINE. يقوم هذا الإجراء بكتابة النص إلى وحدة التحكم أو المخزن المؤقت للإخرا...برمجة تم النشر بتاريخ 2024-11-06
-
الاستفادة من بايثون للأتمتة: تبسيط المهام اليومية باستخدام التعليمات البرمجيةمقدمة اكتسبت بايثون مكانتها كلغة مفضلة لمجموعة واسعة من التطبيقات، بدءًا من تطوير الويب وحتى علوم البيانات. إحدى المجالات التي تتألق فيها...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية تمرير الحجج لتطبيق وظائف سلسلة Pandas في بايثون؟تمرير الوسيطات إلى السلسلة، تطبيق الوظائف في Python Pandas توفر مكتبة الباندا طريقة 'apply()' لتطبيق دالة على كل عنصر من عناصر السلسلة...برمجة تم النشر بتاريخ 2024-11-06
-
كيفية فرز المجموعات حسب الحقول المتعددة بكفاءة باستخدام Java 8 Lambda؟فرز المجموعات ذات الحقول المتعددة باستخدام Java 8 Lambda يبدو رمز الفرز المقدم غير مكتمل وقد لا ينتج الترتيب المفرز المتوقع. دعونا نتعمق في نهج ...برمجة تم النشر بتاريخ 2024-11-06
-
كيف يمكن للمطورين تبادل البيانات بشكل آمن عبر صفحات HTML في جافا سكريبت؟الحفاظ على سلامة البيانات عبر صفحات HTML في JavaScript عند نقل البيانات بين صفحات الويب، النهج التقليدي لاستخدام معلمات الاستعلام (على سبيل المث...برمجة تم النشر بتاريخ 2024-11-06















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









