
انتقل إلى sync.Pool والآليات التي تقف وراءه
 تصفح:918
تصفح:918
هذا مقتطف من التدوينة؛ المنشور الكامل متاح هنا: https://victoriametrics.com/blog/go-sync-pool/
هذا المنشور جزء من سلسلة حول التعامل مع التزامن في Go:
- Go sync.Mutex: الوضع العادي ووضع التجويع
- Go sync.WaitGroup ومشكلة المحاذاة
- Go sync.Pool والآليات التي تقف وراءها (نحن هنا)
- Go sync.Cond، آلية المزامنة الأكثر إغفالًا
في كود مصدر VictoriaMetrics، نستخدم sync.Pool كثيرًا، وهو بصراحة مناسب تمامًا لكيفية تعاملنا مع الكائنات المؤقتة، وخاصة مخازن البايت المؤقتة أو الشرائح.
يشيع استخدامه في المكتبة القياسية. على سبيل المثال، في الحزمة encoding/json:
package json
var encodeStatePool sync.Pool
// An encodeState encodes JSON into a bytes.Buffer.
type encodeState struct {
bytes.Buffer // accumulated output
ptrLevel uint
ptrSeen map[any]struct{}
}
في هذه الحالة، يتم استخدام sync.Pool لإعادة استخدام كائنات *encodeState، التي تتعامل مع عملية تشفير JSON في بايت.Buffer.
بدلاً من مجرد رمي هذه الكائنات بعد كل استخدام، الأمر الذي من شأنه أن يمنح جامع البيانات المهملة المزيد من العمل، نقوم بتخزينها في تجمع (sync.Pool). في المرة القادمة التي نحتاج فيها إلى شيء مماثل، نلتقطه من حوض السباحة بدلاً من صنع شيء جديد من الصفر.
ستجد أيضًا العديد من مثيلات sync.Pool في حزمة net/http، والتي يتم استخدامها لتحسين عمليات الإدخال/الإخراج:
package http
var (
bufioReaderPool sync.Pool
bufioWriter2kPool sync.Pool
bufioWriter4kPool sync.Pool
)
عندما يقرأ الخادم نصوص الطلب أو يكتب الاستجابات، يمكنه بسرعة سحب القارئ أو الكاتب المخصص مسبقًا من هذه التجمعات، وتخطي التخصيصات الإضافية. علاوة على ذلك، تم إعداد مجموعتي الكاتب، *bufioWriter2kPool و*bufioWriter4kPool، للتعامل مع احتياجات الكتابة المختلفة.
func bufioWriterPool(size int) *sync.Pool {
switch size {
case 2
حسنًا، هذا يكفي للمقدمة.
اليوم، نحن نتعمق في موضوع المزامنة.Pool، التعريف، كيفية استخدامه، ما الذي يحدث تحت الغطاء، وكل شيء آخر قد ترغب في معرفته.
بالمناسبة، إذا كنت تريد شيئًا عمليًا أكثر، فهناك مقالة جيدة من خبراء Go لدينا توضح كيفية استخدامنا للمزامنة.Pool in VictoriaMetrics: تقنيات تحسين الأداء في قواعد بيانات السلاسل الزمنية: sync.Pool للعمليات المرتبطة بوحدة المعالجة المركزية
ما هو sync.Pool؟
بكل بساطة، sync.Pool in Go هو مكان يمكنك من خلاله الاحتفاظ بالكائنات المؤقتة لإعادة استخدامها لاحقًا.
ولكن هذا هو الأمر، فأنت لا تتحكم في عدد الأشياء التي تبقى في حوض السباحة، وأي شيء تضعه هناك يمكن إزالته في أي وقت، دون أي تحذير وستعرف السبب عند قراءة القسم الأخير.
]
النقطة الجيدة هي أن المجمع مصمم ليكون آمنًا للخيوط، لذلك يمكن للعديد من goroutines الاستفادة منه في وقت واحد. ليست مفاجأة كبيرة، مع الأخذ في الاعتبار أنها جزء من حزمة المزامنة.
"ولكن لماذا نهتم بإعادة استخدام الأشياء؟"
عندما يكون لديك الكثير من goroutines قيد التشغيل مرة واحدة، فغالبًا ما تحتاج إلى كائنات مماثلة. تخيل تشغيل go f() عدة مرات بشكل متزامن.
إذا قام كل goroutine بإنشاء كائناته الخاصة، فيمكن أن يزيد استخدام الذاكرة بسرعة وهذا يضع ضغطًا على أداة تجميع البيانات المهملة لأنه يتعين عليها تنظيف كل هذه الكائنات بمجرد عدم الحاجة إليها.
ينشئ هذا الموقف دورة يؤدي فيها التزامن العالي إلى زيادة استخدام الذاكرة، مما يؤدي بعد ذلك إلى إبطاء أداة تجميع مجمعي البيانات المهملة. تم تصميم sync.Pool للمساعدة في كسر هذه الحلقة المفرغة.
type Object struct {
Data []byte
}
var pool sync.Pool = sync.Pool{
New: func() any {
return &Object{
Data: make([]byte, 0, 1024),
}
},
}
لإنشاء تجمع، يمكنك توفير وظيفة New() التي تُرجع كائنًا جديدًا عندما يكون التجمع فارغًا. هذه الوظيفة اختيارية، إذا لم تقم بتوفيرها، فإن المجمع يُرجع صفرًا فقط إذا كان فارغًا.
في المقتطف أعلاه، الهدف هو إعادة استخدام مثيل بنية الكائن، وتحديدًا الشريحة الموجودة بداخله.
تساعد إعادة استخدام الشريحة على تقليل النمو غير الضروري.
على سبيل المثال، إذا زاد حجم الشريحة إلى 8192 بايت أثناء الاستخدام، فيمكنك إعادة تعيين طولها إلى الصفر قبل إعادتها إلى المجموعة. لا تزال سعة المصفوفة الأساسية تبلغ 8192، لذا في المرة القادمة التي تحتاج إليها، ستكون تلك الـ 8192 بايت جاهزة لإعادة الاستخدام.
func (o *Object) Reset() {
o.Data = o.Data[:0]
}
func main() {
testObject := pool.Get().(*Object)
// do something with testObject
testObject.Reset()
pool.Put(testObject)
}
التدفق واضح جدًا: تحصل على كائن من حمام السباحة، وتستخدمه، وتعيد تعيينه، ثم تعيده إلى حمام السباحة. يمكن إجراء إعادة ضبط الكائن إما قبل إعادته إلى مكانه مرة أخرى أو مباشرة بعد الحصول عليه من حوض السباحة، ولكنه ليس إلزاميًا، إنه ممارسة شائعة.
إذا لم تكن من محبي استخدام تأكيدات النوع Pool.Get().(*Object)، فهناك طريقتان لتجنب ذلك:
- استخدم وظيفة مخصصة للحصول على الكائن من التجمع:
func getObjectFromPool() *Object {
obj := pool.Get().(*Object)
return obj
}
- قم بإنشاء إصدار عام خاص بك من sync.Pool:
type Pool[T any] struct {
sync.Pool
}
func (p *Pool[T]) Get() T {
return p.Pool.Get().(T)
}
func (p *Pool[T]) Put(x T) {
p.Pool.Put(x)
}
func NewPool[T any](newF func() T) *Pool[T] {
return &Pool[T]{
Pool: sync.Pool{
New: func() interface{} {
return newF()
},
},
}
}
يمنحك الغلاف العام طريقة أكثر أمانًا للكتابة للعمل مع التجمع، وتجنب تأكيدات الكتابة.
لاحظ فقط أنه يضيف القليل من النفقات العامة بسبب الطبقة الإضافية من المراوغة. في معظم الحالات، يكون هذا الحمل ضئيلًا للغاية، ولكن إذا كنت تعمل في بيئة شديدة الحساسية لوحدة المعالجة المركزية، فمن الجيد تشغيل معايير لمعرفة ما إذا كان الأمر يستحق ذلك.
ولكن مهلا، هناك المزيد.
sync.Pool وفخ التخصيص
إذا لاحظت من العديد من الأمثلة السابقة، بما في ذلك تلك الموجودة في المكتبة القياسية، فإن ما نقوم بتخزينه في التجمع ليس الكائن نفسه ولكن مؤشر للكائن.
دعني أشرح السبب بمثال:
var pool = sync.Pool{
New: func() any {
return []byte{}
},
}
func main() {
bytes := pool.Get().([]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
نحن نستخدم مجموعة من [] بايت. بشكل عام (وإن لم يكن دائمًا)، عندما تقوم بتمرير قيمة إلى واجهة ما، قد يتسبب ذلك في وضع القيمة في الكومة. يحدث هذا هنا أيضًا، ليس فقط مع الشرائح ولكن مع أي شيء تمرره إلى Pool.Put() والذي لا يمثل مؤشرًا.
إذا قمت بالتحقق باستخدام تحليل الهروب:
// escape analysis $ go build -gcflags=-m bytes escapes to heap
الآن، لا أقول أن وحدات البايت المتغيرة تنتقل إلى الكومة، بل أود أن أقول "قيمة البايتات تهرب إلى الكومة من خلال الواجهة".
لمعرفة سبب حدوث ذلك، سنحتاج إلى البحث في كيفية عمل تحليل الهروب (وهو ما قد نفعله في مقال آخر). ومع ذلك، إذا قمنا بتمرير مؤشر إلى Pool.Put()، فلن يكون هناك تخصيص إضافي:
var pool = sync.Pool{
New: func() any {
return new([]byte)
},
}
func main() {
bytes := pool.Get().(*[]byte)
// do something with bytes
_ = bytes
pool.Put(bytes)
}
قم بتشغيل تحليل الهروب مرة أخرى، وسترى أنه لم يعد هناك إمكانية للهروب إلى الكومة. إذا كنت تريد معرفة المزيد، فهناك مثال في كود مصدر Go.
sync.Pool الداخلية
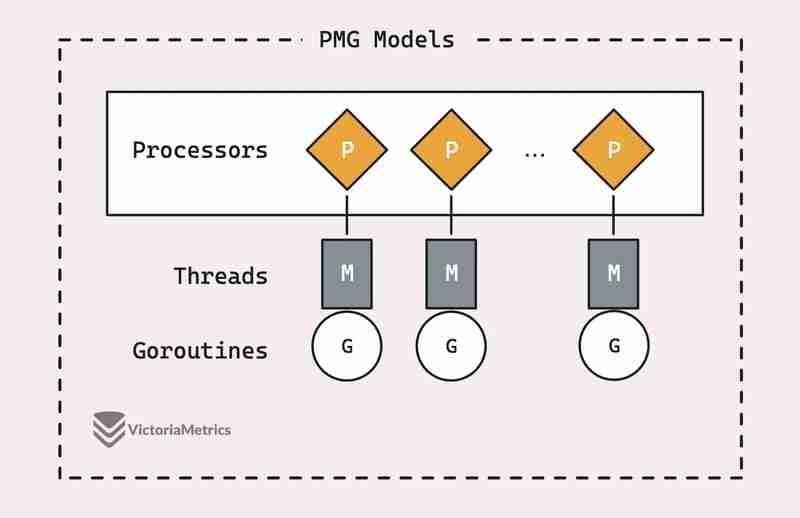
قبل أن نتطرق إلى كيفية عمل sync.Pool فعليًا، من المفيد التعرف على أساسيات نموذج جدولة PMG الخاص بـ Go، وهذا حقًا هو العمود الفقري لسبب كفاءة sync.Pool.
هناك مقالة جيدة تشرح نموذج PMG مع بعض العناصر المرئية: نماذج PMG في Go
إذا كنت تشعر بالكسل اليوم وتبحث عن ملخص مبسط، فأنا أساندك:
يرمز PMG إلى P (المعالجات المنطقية p)، وM (mخيوط الآلة)، وG (goroutines). النقطة الأساسية هي أن كل معالج منطقي (P) يمكن أن يعمل عليه مؤشر ترابط جهاز واحد فقط (M) في أي وقت. ولكي يتم تشغيل goroutine (G)، يجب ربطه بخيط (M).
يتلخص هذا في نقطتين رئيسيتين:
- إذا كان لديك n من المعالجات المنطقية (P)، فيمكنك تشغيل ما يصل إلى n goroutines بالتوازي، طالما أن لديك n على الأقل من سلاسل العمليات (M) المتاحة.
- في أي وقت، يمكن تشغيل goroutine واحد فقط (G) على معالج واحد (P). لذا، عندما يكون P1 مشغولاً بـ G، لا يمكن لأي G آخر أن يعمل على P1 حتى يتم حظر G الحالي، أو ينتهي، أو يحدث شيء آخر لتحريره.
ولكن الأمر هو المزامنة. إن التجمع في Go ليس مجرد تجمع كبير واحد، فهو يتكون في الواقع من عدة تجمعات "محلية"، مع ربط كل منها بسياق معالج معين، أو P، وقت تشغيل Go هو الإدارة في أي وقت.
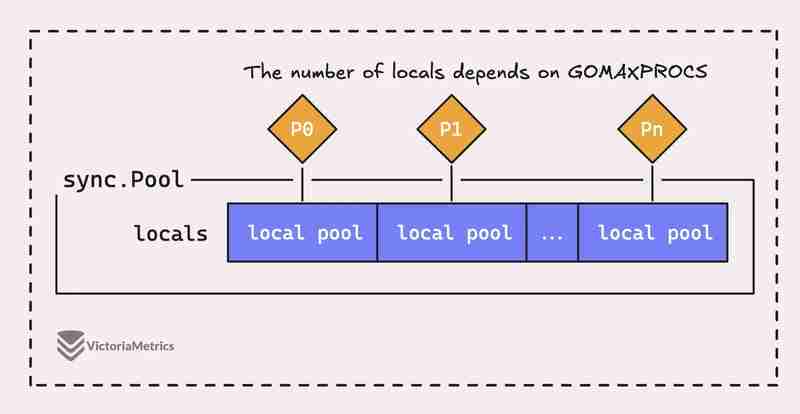
عندما يحتاج goroutine الذي يعمل على معالج (P) إلى كائن من المجموعة، فسوف يتحقق أولاً من تجمع P-local الخاص به قبل البحث في أي مكان آخر.
المنشور الكامل متاح هنا: https://victoriametrics.com/blog/go-sync-pool/
-
 كيف يمكنني التعامل مع أسماء ملفات UTF-8 في وظائف نظام ملفات PHP؟url تشفير أسماء الملفات لحل هذه المشكلة ، استخدم وظيفة urlencode لتحويل اسم المجلد المطلوب إلى تنسيق آمن لـ url قبل تمريره إلى mkdir: MKDIR (...برمجة نشر في 2025-03-28
كيف يمكنني التعامل مع أسماء ملفات UTF-8 في وظائف نظام ملفات PHP؟url تشفير أسماء الملفات لحل هذه المشكلة ، استخدم وظيفة urlencode لتحويل اسم المجلد المطلوب إلى تنسيق آمن لـ url قبل تمريره إلى mkdir: MKDIR (...برمجة نشر في 2025-03-28 -
كيف يمكنك استخدام مجموعة من خلال محور البيانات في MySQL؟هنا ، نتعامل مع تحد شائع: تحويل البيانات من الصف إلى الصفوف المستندة إلى الأعمدة باستخدام. لننظر في الاستعلام التالي: حدد البيانات مجموعة بوا...برمجة نشر في 2025-03-28
-
لماذا تظهر صورة خلفية CSS الخاصة بي؟توجد ورقة الصورة والأنماط في نفس الدليل ، ومع ذلك ، تظل الخلفية قماشًا أبيض فارغًا. إرفاق اسم ملف الصورة: -صورة الخلفية: url (nickcage.jpg) ؛ إذ...برمجة نشر في 2025-03-28
-
كيف يمكنني الجمع بشكل فعال بين Flexbox والتمرير العمودي في تصميم كامل؟ومع ذلك ، يمكن أن يطرح تحديات بسبب الطبيعة التفاعلية لتخطيطات Flexbox. يعتمد هذا الحل على تعيين اتجاه المرن للعمود واستخدام Overflow-y: تلقائيًا عل...برمجة نشر في 2025-03-28
-
كيف يمكنني إنشاء قواميس بكفاءة باستخدام فهم Python؟على الرغم من أنها تشبه إلى حد كبير اختصارات القائمة ، إلا أن هناك بعض الاختلافات الملحوظة. يجب عليك تحديد المفاتيح والقيم بشكل صريح. على سبيل المثا...برمجة نشر في 2025-03-28
-
كيف يمكنني تكوين pytesseract للتعرف على أرقام واحدة مع إخراج الأرقام فقط؟لمعالجة هذه المشكلة ، نقوم بالتعمق في تفاصيل خيارات تكوين Tesseract. من أجل التعرف على الأحرف الفردية ، فإن PSM المناسب هو 10. هذا الوضع يعامل الصو...برمجة نشر في 2025-03-28
-
لماذا توجد خطوط في خلفية التدرج الخطية ، وكيف يمكنني إصلاحها؟لحفر خطوط الخلفية من التدرج الخطي عند توظيف خاصية الدرجات الخطية لخلفية ، قد تواجه خطوطًا ملحوظة عندما يتم ضبط الاتجاه على الأعلى أو الأسفل. ي...برمجة نشر في 2025-03-28
-
كيفية التحقق مما إذا كان كائن لديه سمة محددة في بيثون؟فكر في المثال التالي حيث تثير محاولة الوصول إلى خاصية غير محددة خطأً: >>> a = someclass () >>> A.Property Traceback (أحدث مكالمة أخيرة): ملف &...برمجة نشر في 2025-03-28
-
كيف يمكنني تنفيذ أوامر موجه الأوامر ، بما في ذلك تغييرات الدليل ، في جافا؟على الرغم من أنك قد تجد قصاصات رمز تفتح موجه الأوامر ، إلا أنها غالبًا ما تفتقر إلى القدرة على تغيير الدلائل وتنفيذ أوامر إضافية. يتيح لك هذا النهج...برمجة نشر في 2025-03-28
-
لماذا لا يوجد طلب آخر لالتقاط المدخلات في PHP على الرغم من الرمز الصحيح؟معالجة عطل طلب النشر في php $ _server ['php_self'] ؛؟> "method =" post "> ومع ذلك ، يظل الناتج فارغًا. على الرغم من ...برمجة نشر في 2025-03-28
-
كيفية التعامل مع مدخلات المستخدم في الوضع الحصري لشروط جافا؟تستكشف هذه المقالة النهج الصحيح للتعامل مع إدخال المستخدم من لوحة المفاتيح والماوس في هذا الوضع. ومع ذلك ، في وضع كامل الشاشة الحصري ، قد لا تعمل ه...برمجة نشر في 2025-03-28
-
Python قراءة ملف CSV UnicodedEcodeerror الحل النهائيلا يمكن فك تشفير البايت في الموضع 2-3: مقطوع \ uxxxxxxxxx escart string قم بتعبئة المسار إلى ملف CSV مع وضع صغير "r" للدلالة على سل...برمجة نشر في 2025-03-28
-
كيفية حل خطأ \ "الاستخدام غير صالح لوظيفة المجموعة \" في MySQL عند العثور على عدد أقصى؟كيفية استرداد الحد الأقصى لعد باستخدام mysql حدد ماكس (العد (*)) من مجموعة EMP1 بالاسم ؛ خطأ 1111 (hy000): الاستخدام غير الصحيح لوظيفة المجموعة...برمجة نشر في 2025-03-28
-
كيفية تحميل الملفات مع معلمات إضافية باستخدام java.net.urlconnection وترميز multipart/form-data؟فيما يلي تفصيل للعملية: يتضمن الترميز تقسيم جسم الطلب إلى أجزاء متعددة ، كل منها مسبق بسلسلة حدودية. استيراد java.io.outputStream ؛ استيراد java....برمجة نشر في 2025-03-28
-
كيف تحل `std :: karder` مشكلات التحويل المترجم مع أعضاء كونست في النقابات؟لفهم غرضه ، دعنا نتعامل في المشكلة المحددة التي تعالجها هذه الورقة وتعديلات اللغة اللاحقة التي نحتاجها إلى الاعتراف. المشكلة في متناول اليد } ؛...برمجة نشر في 2025-03-28















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









