
انحدار أقرب الجيران، الانحدار: التعلم الآلي الخاضع للإشراف
 تصفح:939
تصفح:939
ك-أقرب انحدار الجيران
انحدار k-أقرب الجيران (k-NN) هو طريقة غير معلمية تتنبأ بقيمة الإخراج بناءً على المتوسط (أو المتوسط المرجح) لأقرب نقاط بيانات التدريب k في مساحة الميزة. يمكن لهذا النهج أن يصمم بشكل فعال العلاقات المعقدة في البيانات دون افتراض نموذج وظيفي محدد.
يمكن تلخيص طريقة الانحدار k-NN على النحو التالي:
- قياس المسافة: تستخدم الخوارزمية مقياس المسافة (المسافة الإقليدية عادةً) لتحديد "القرب" من نقاط البيانات.
- k Neighbors: تحدد المعلمة k عدد الجيران الأقرب الذين يجب مراعاتهم عند إجراء التنبؤات.
- التنبؤ: القيمة المتوقعة لنقطة بيانات جديدة هي متوسط قيم أقرب جيرانها.
المفاهيم الأساسية
-
غير بارامترية : على عكس النماذج البارامترية، لا تفترض k-NN نموذجًا محددًا للعلاقة الأساسية بين ميزات الإدخال والمتغير المستهدف. وهذا يجعلها مرنة في التقاط الأنماط المعقدة.
حساب المسافة: يمكن أن يؤثر اختيار مقياس المسافة بشكل كبير على أداء النموذج. تشمل المقاييس الشائعة المسافات الإقليدية ومانهاتن ومينكوفسكي.
اختيار k: يمكن اختيار عدد الجيران (k) بناءً على التحقق المتبادل. يمكن أن يؤدي الحرف k الصغير إلى الإفراط في التجهيز، في حين أن الحرف k الكبير يمكن أن يؤدي إلى تسهيل التنبؤ أكثر من اللازم، ومن المحتمل أن يؤدي إلى نقص التجهيز.
ك-أقرب مثال على انحدار الجيران
يوضح هذا المثال كيفية استخدام انحدار k-NN مع ميزات متعددة الحدود لنمذجة العلاقات المعقدة مع الاستفادة من الطبيعة غير البارامترية لـ k-NN.
مثال كود بايثون
1. استيراد المكتبات
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
تستورد هذه الكتلة المكتبات اللازمة لمعالجة البيانات والتخطيط والتعلم الآلي.
2. إنشاء بيانات نموذجية
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() np.sin(2 * X.ravel()) * 5 np.random.normal(0, 1, 100)
تقوم هذه الكتلة بإنشاء بيانات نموذجية تمثل علاقة مع بعض الضوضاء، ومحاكاة اختلافات البيانات في العالم الحقيقي.
3. تقسيم مجموعة البيانات
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
تقسم هذه الكتلة مجموعة البيانات إلى مجموعات تدريب واختبار لتقييم النموذج.
4. إنشاء ميزات متعددة الحدود
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
تنشئ هذه الكتلة ميزات متعددة الحدود من مجموعات بيانات التدريب والاختبار، مما يسمح للنموذج بالتقاط العلاقات غير الخطية.
5. إنشاء وتدريب نموذج الانحدار k-NN
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
تقوم هذه الكتلة بتهيئة نموذج الانحدار k-NN وتدريبه باستخدام الميزات متعددة الحدود المستمدة من مجموعة بيانات التدريب.
6. توقع التنبؤات
y_pred = knn_model.predict(X_poly_test)
تستخدم هذه الكتلة النموذج المُدرب لإجراء تنبؤات على مجموعة الاختبار.
7. رسم النتائج
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
تنشئ هذه الكتلة مخططًا مبعثرًا لنقاط البيانات الفعلية مقابل القيم المتوقعة من نموذج الانحدار k-NN، مما يؤدي إلى تصور المنحنى المناسب.
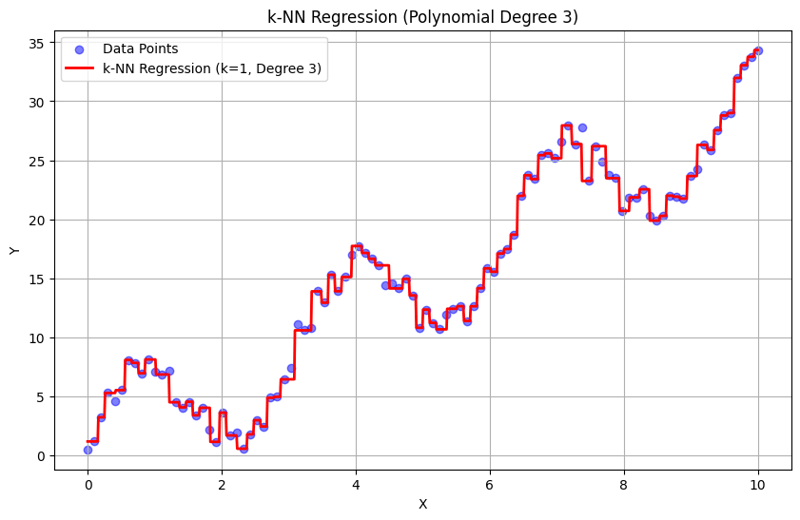
الإخراج بـ k = 1:
الإخراج بـ k = 10:
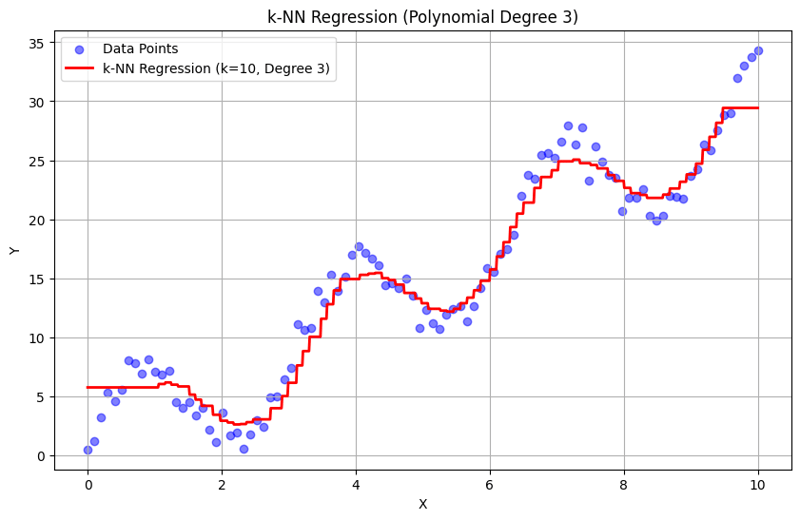
يوضح هذا النهج المنظم كيفية تنفيذ وتقييم انحدار k-Nearest Neighbors مع ميزات متعددة الحدود. من خلال التقاط الأنماط المحلية من خلال حساب متوسط استجابات الجيران القريبين، يقوم انحدار k-NN بنمذجة العلاقات المعقدة في البيانات بشكل فعال مع توفير تنفيذ مباشر. يؤثر اختيار k ودرجة متعددة الحدود بشكل كبير على أداء النموذج ومرونته في التقاط الاتجاهات الأساسية.
-
 بناء واجهة أمامية باستخدام بايثون فقطيمكن أن يكون تطوير الواجهة الأمامية مهمة شاقة، وحتى كابوسية، بالنسبة للمطورين الذين يركزون على الواجهة الخلفية. في بداية مسيرتي المهنية، كانت الخطوط ...برمجة تم النشر بتاريخ 2024-11-05
بناء واجهة أمامية باستخدام بايثون فقطيمكن أن يكون تطوير الواجهة الأمامية مهمة شاقة، وحتى كابوسية، بالنسبة للمطورين الذين يركزون على الواجهة الخلفية. في بداية مسيرتي المهنية، كانت الخطوط ...برمجة تم النشر بتاريخ 2024-11-05 -
كيفية تشغيل وظائف Cron في Laravelفي هذا البرنامج التعليمي سأوضح لك كيف يمكننا تشغيل وظائف cron في Laravel، ولكن فوق كل شيء سنبقي الأمور بسيطة وسهلة لطلابنا. سنذهب لاستكشاف كيفية إ...برمجة تم النشر بتاريخ 2024-11-05
-
كيف تؤثر الحشوة على تباعد العناصر المضمنة وكيف يمكنك حل التعارضات؟الحشو على العناصر المضمنة: التأثيرات والقيود وفقًا للمصدر، لا يؤثر إضافة الحشو إلى أعلى وأسفل العناصر المضمنة تباعد العناصر المحيطة. ومع ذلك، ...برمجة تم النشر بتاريخ 2024-11-05
-
أصبح عرض Django Class Based سهلاًكما نعلم جميعًا، يستخدم Django MVT (نموذج عرض القالب) لتصميمه عند تطوير تطبيقات الويب. العرض نفسه هو أمر قابل للاستدعاء ويستقبل الطلب ويعيد الاست...برمجة تم النشر بتاريخ 2024-11-05
-
قم ببناء وكيل الذكاء الاصطناعي بدون كود باستخدام VAKXIf you’ve been keeping up with the AI space, you already know that AI agents are becoming a game-changer in the world of automation and customer inter...برمجة تم النشر بتاريخ 2024-11-05
-
إليك كيفية تنفيذ ترقيم الصفحات المستند إلى المؤشر في jQuery Datatable.عند العمل مع مجموعات البيانات الكبيرة في تطبيقات الويب، يعد ترقيم الصفحات أمرًا بالغ الأهمية للأداء وتجربة المستخدم. يمكن أن يكون ترقيم الصفحات ال...برمجة تم النشر بتاريخ 2024-11-05
-
لماذا قد تكون محركات المزامنة هي مستقبل تطبيقات الويبفي عالم تطبيقات الويب المتطور، تعد الكفاءة وقابلية التوسع والتجارب السلسة في الوقت الفعلي أمرًا بالغ الأهمية. تعتمد بنيات الويب التقليدية بشكل كبي...برمجة تم النشر بتاريخ 2024-11-05
-
مقدمة للرؤية الحاسوبية باستخدام لغة بايثون (الجزء الأول)ملاحظة: في هذا المنشور، سنعمل فقط مع الصور ذات الحجم الرمادي لتسهيل متابعتها. ما هي الصورة؟ يمكن اعتبار الصورة مصفوفة من القيم، حيث تمثل كل ق...برمجة تم النشر بتاريخ 2024-11-05
-
كود HTML للموقعلقد كنت أحاول إنشاء موقع ويب يتعلق بشركات الطيران. أردت فقط التأكيد على إمكانية إنشاء موقع ويب كامل باستخدام الذكاء الاصطناعي لإنشاء التعليمات الب...برمجة تم النشر بتاريخ 2024-11-05
-
فكر كمبرمج: تعلم أساسيات جافاتقدم هذه المقالة المفاهيم والهياكل الأساسية لبرمجة Java. يبدأ بمقدمة للمتغيرات وأنواع البيانات، ثم يناقش العوامل والتعبيرات، بالإضافة إلى عمليات التح...برمجة تم النشر بتاريخ 2024-11-05
-
هل يمكن لـ PHP GD مقارنة صورتين للتشابه؟هل يمكن لـ PHP GD تحديد تشابه صورتين؟ يستفسر السؤال المطروح عما إذا كان من الممكن التأكد مما إذا كانت الصورتان متطابقتان باستخدام PHP GD من خل...برمجة تم النشر بتاريخ 2024-11-05
-
استخدم هذه المفاتيح لكتابة اختبارات المستوى الأعلى (اختبار Desiderata في JavaScript)في هذه المقالة، ستتعلم 12 من أفضل ممارسات الاختبار التي يجب أن يعرفها كل مطور كبير. سترى أمثلة واقعية لجافا سكريبت لمقالة كينت بيك "Test Desi...برمجة تم النشر بتاريخ 2024-11-05
-
أفضل حل لـ AEC عن طريق نقل خوارزمية matlab/octave إلى Cمنتهي! معجبة قليلاً بنفسي. يحتاج منتجنا إلى وظيفة إلغاء الصدى، وتم تحديد ثلاثة حلول تقنية ممكنة، 1) استخدم MCU للكشف عن الصوت الخارج والصوت في الإشار...برمجة تم النشر بتاريخ 2024-11-05
-
بناء صفحات الويب خطوة بخطوة: استكشاف البنية والعناصر في HTML؟ يمثل اليوم خطوة رئيسية في رحلتي لتطوير البرمجيات! ؟ لقد كتبت الأسطر الأولى من التعليمات البرمجية، وتعمقت في أساسيات HTML. العناصر والعلامات المغطاة....برمجة تم النشر بتاريخ 2024-11-05
-
لا يجب أن تكون أفكار المشاريع فريدة من نوعها: وإليك السببفي عالم الابتكار، هناك مفهوم خاطئ شائع مفاده أن أفكار المشاريع يجب أن تكون رائدة أو فريدة تمامًا حتى تكون ذات قيمة. ومع ذلك، هذا بعيد عن الحقيقة. ...برمجة تم النشر بتاريخ 2024-11-05















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









