
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit هي مكتبة Python تجعل من السهل إنشاء ومشاركة تطبيقات الويب المخصصة لمشاريع التعلم الآلي وعلوم البيانات.
numpy هي مكتبة بايثون الأساسية للحوسبة العددية. يوفر الدعم للمصفوفات والمصفوفات الكبيرة ومتعددة الأبعاد، إلى جانب مجموعة من الوظائف الرياضية للعمل على هذه المصفوفات بكفاءة.
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)يتم استرداد قيم الإدخال من نموذج الإدخال الذي تم إنشاؤه بواسطة Stremlit، ويتم ترميز المتغيرات الفئوية باستخدام نفس القواعد التي كانت عند إنشاء النموذج. لاحظ أن ترتيب كل البيانات يجب أن يكون هو نفسه الذي تم إنشاؤه عند إنشاء النموذج. إذا كان الترتيب مختلفًا، سيحدث خطأ عند تنفيذ التنبؤ باستخدام النموذج.
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
\\\"penguin_classifier_model.pkl\\\" هو الملف الذي تم تخزين النموذج المحفوظ فيه مسبقًا. يحتوي هذا الملف على RandomForestClassifier مدرب بتنسيق ثنائي. يؤدي تشغيل هذا الكود إلى تحميل النموذج إلى clf، مما يسمح لك باستخدامه للتنبؤات والتقييمات على البيانات الجديدة.
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): يستخدم النموذج المدرب للتنبؤ بفئة بيانات الإدخال المشفرة الجديدة، وتخزين النتيجة في التنبؤ.
clf.predict_proba(input_encoded_df): حساب الاحتمالية لكل فئة، وتخزين النتائج في Prophet_proba.
يمكنك نشر تطبيقك المطور على الإنترنت عن طريق الوصول إلى Stremlit Community Cloud (https://streamlit.io/cloud) وتحديد عنوان URL لمستودع GitHub.

عمل فني بواسطة @allison_horst (https://github.com/allisonhorst)
تم تدريب النموذج باستخدام مجموعة بيانات Palmer Penguins، وهي مجموعة بيانات معترف بها على نطاق واسع لممارسة تقنيات التعلم الآلي. توفر مجموعة البيانات هذه معلومات عن ثلاثة أنواع من طيور البطريق (أديلي، وشينستراب، وجنتو) من أرخبيل بالمر في القارة القطبية الجنوبية. تشمل الميزات الرئيسية ما يلي:
تم الحصول على مجموعة البيانات هذه من Kaggle، ويمكن الوصول إليها هنا. التنوع في الميزات يجعله خيارًا ممتازًا لبناء نموذج تصنيف وفهم أهمية كل ميزة في التنبؤ بالأنواع.
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} تصفح:912
تصفح:912
نموذج التعلم الآلي هو في الأساس مجموعة من القواعد أو الآليات المستخدمة للتنبؤات أو العثور على أنماط في البيانات. وبعبارة أبسط (وبدون خوف من التبسيط)، فإن خط الاتجاه المحسوب باستخدام طريقة المربعات الصغرى في Excel هو أيضًا نموذج. ومع ذلك، فإن النماذج المستخدمة في التطبيقات الحقيقية ليست بهذه البساطة، فهي غالبًا ما تتضمن معادلات وخوارزميات أكثر تعقيدًا، وليس مجرد معادلات بسيطة.
في هذا المنشور، سأبدأ ببناء نموذج بسيط جدًا للتعلم الآلي وإطلاقه كتطبيق ويب بسيط جدًا للتعرف على العملية.
هنا، سأركز فقط على العملية، وليس على نموذج تعلم الآلة نفسه. سأستخدم أيضًا Streamlit وStreamlit Community Cloud لإصدار تطبيقات ويب Python بسهولة.
باستخدام scikit-learn، وهي مكتبة Python شائعة للتعلم الآلي، يمكنك تدريب البيانات بسرعة وإنشاء نموذج باستخدام بضعة أسطر من التعليمات البرمجية للمهام البسيطة. يمكن بعد ذلك حفظ النموذج كملف قابل لإعادة الاستخدام باستخدام joblib. يمكن استيراد/تحميل هذا النموذج المحفوظ مثل مكتبة Python العادية في تطبيق ويب، مما يسمح للتطبيق بالتنبؤ باستخدام النموذج المُدرب!
عنوان URL للتطبيق: https://yh-machine-learning.streamlit.app/
جيثب: https://github.com/yoshan0921/yh-machine-learning.git
يسمح لك هذا التطبيق بفحص التنبؤات التي قدمها نموذج غابة عشوائي تم تدريبه على مجموعة بيانات Palmer Penguins. (راجع نهاية هذه المقالة لمزيد من التفاصيل حول بيانات التدريب.)
على وجه التحديد، يتنبأ النموذج بأنواع البطريق بناءً على مجموعة متنوعة من الميزات، بما في ذلك النوع والجزيرة وطول المنقار وطول الزعنفة وحجم الجسم والجنس. يمكن للمستخدمين التنقل في التطبيق لمعرفة مدى تأثير الميزات المختلفة على توقعات النموذج.
شاشة التنبؤ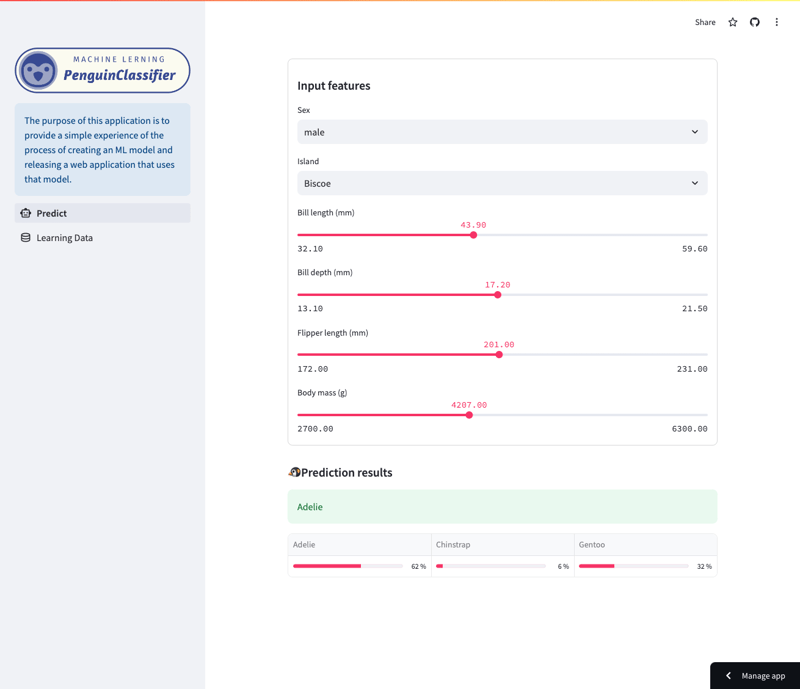
شاشة البيانات/التصورات التعليمية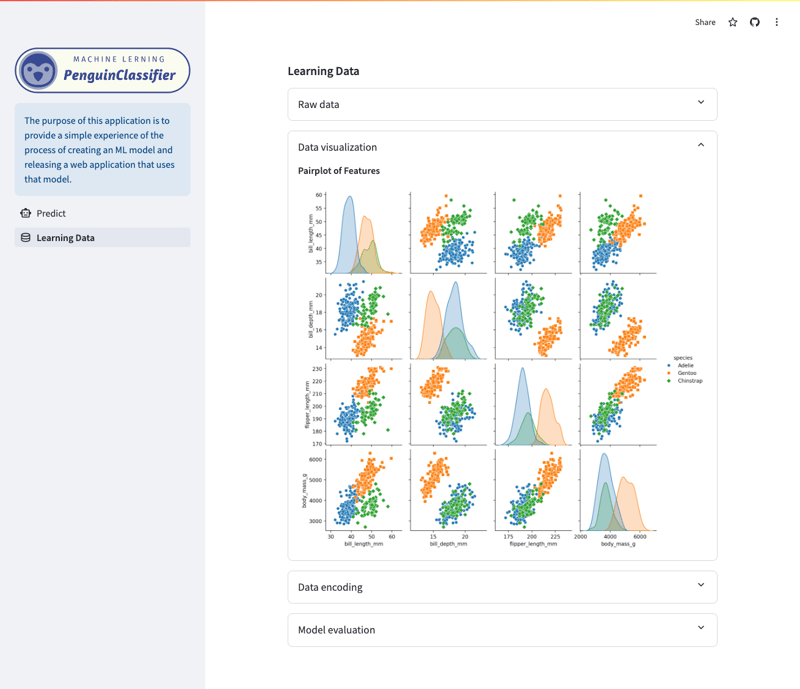
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas هي مكتبة بايثون متخصصة في معالجة البيانات وتحليلها. وهو يدعم تحميل البيانات، والمعالجة المسبقة، والهيكلة باستخدام DataFrames، وإعداد البيانات لنماذج التعلم الآلي.
sklearn هي مكتبة بايثون شاملة للتعلم الآلي توفر أدوات للتدريب والتقييم. في هذا المنشور، سأقوم ببناء نموذج باستخدام طريقة تعليمية تسمى Random Forest.
joblib هي مكتبة Python تساعد في حفظ وتحميل كائنات Python، مثل نماذج التعلم الآلي، بطريقة فعالة للغاية.
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
تحميل مجموعة البيانات (بيانات التدريب) وفصلها إلى ميزات (X) ومتغيرات الهدف (ص).
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
يتم تحويل المتغيرات الفئوية إلى تنسيق رقمي باستخدام التشفير الساخن (X_encoded). على سبيل المثال، إذا كانت "الجزيرة" تحتوي على الفئات "Biscoe" و"Dream" و"Torgersen"، فسيتم إنشاء عمود جديد لكل منها (island_Biscoe، Island_Dream، Island_Torgersen). وينطبق الشيء نفسه على الجنس. إذا كانت البيانات الأصلية هي "Biscoe"، فسيتم تعيين عمود Island_Biscoe على 1 والأعمدة الأخرى على 0.
يتم تعيين الأنواع المتغيرة المستهدفة إلى قيم عددية (y_encoded).
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
لتقييم النموذج، من الضروري قياس أداء النموذج على البيانات غير المستخدمة للتدريب. تُستخدم نسبة 7:3 على نطاق واسع كممارسة عامة في التعلم الآلي.
clf = RandomForestClassifier() clf.fit(x_train, y_train)
يتم استخدام طريقة الملاءمة لتدريب النموذج.
يمثل x_train بيانات التدريب للمتغيرات التوضيحية، ويمثل y_train المتغيرات المستهدفة.
من خلال استدعاء هذه الطريقة، يتم تخزين النموذج الذي تم تدريبه بناءً على بيانات التدريب في ملف clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump() هي دالة لحفظ كائنات Python بتنسيق ثنائي. من خلال حفظ النموذج بهذا التنسيق، يمكن تحميل النموذج من ملف واستخدامه كما هو دون الحاجة إلى التدريب مرة أخرى.
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit هي مكتبة Python تجعل من السهل إنشاء ومشاركة تطبيقات الويب المخصصة لمشاريع التعلم الآلي وعلوم البيانات.
numpy هي مكتبة بايثون الأساسية للحوسبة العددية. يوفر الدعم للمصفوفات والمصفوفات الكبيرة ومتعددة الأبعاد، إلى جانب مجموعة من الوظائف الرياضية للعمل على هذه المصفوفات بكفاءة.
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
يتم استرداد قيم الإدخال من نموذج الإدخال الذي تم إنشاؤه بواسطة Stremlit، ويتم ترميز المتغيرات الفئوية باستخدام نفس القواعد التي كانت عند إنشاء النموذج. لاحظ أن ترتيب كل البيانات يجب أن يكون هو نفسه الذي تم إنشاؤه عند إنشاء النموذج. إذا كان الترتيب مختلفًا، سيحدث خطأ عند تنفيذ التنبؤ باستخدام النموذج.
clf = joblib.load("penguin_classifier_model.pkl")
"penguin_classifier_model.pkl" هو الملف الذي تم تخزين النموذج المحفوظ فيه مسبقًا. يحتوي هذا الملف على RandomForestClassifier مدرب بتنسيق ثنائي. يؤدي تشغيل هذا الكود إلى تحميل النموذج إلى clf، مما يسمح لك باستخدامه للتنبؤات والتقييمات على البيانات الجديدة.
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df): يستخدم النموذج المدرب للتنبؤ بفئة بيانات الإدخال المشفرة الجديدة، وتخزين النتيجة في التنبؤ.
clf.predict_proba(input_encoded_df): حساب الاحتمالية لكل فئة، وتخزين النتائج في Prophet_proba.
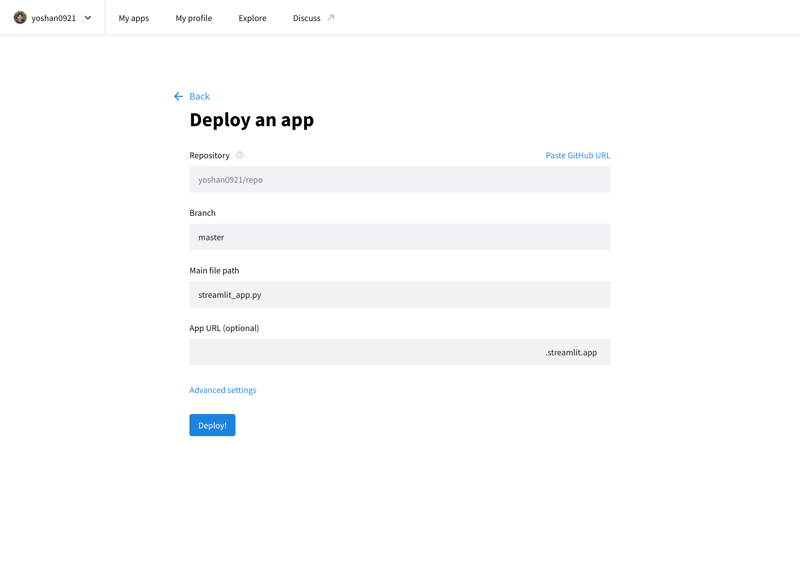
يمكنك نشر تطبيقك المطور على الإنترنت عن طريق الوصول إلى Stremlit Community Cloud (https://streamlit.io/cloud) وتحديد عنوان URL لمستودع GitHub.

عمل فني بواسطة @allison_horst (https://github.com/allisonhorst)
تم تدريب النموذج باستخدام مجموعة بيانات Palmer Penguins، وهي مجموعة بيانات معترف بها على نطاق واسع لممارسة تقنيات التعلم الآلي. توفر مجموعة البيانات هذه معلومات عن ثلاثة أنواع من طيور البطريق (أديلي، وشينستراب، وجنتو) من أرخبيل بالمر في القارة القطبية الجنوبية. تشمل الميزات الرئيسية ما يلي:
تم الحصول على مجموعة البيانات هذه من Kaggle، ويمكن الوصول إليها هنا. التنوع في الميزات يجعله خيارًا ممتازًا لبناء نموذج تصنيف وفهم أهمية كل ميزة في التنبؤ بالأنواع.







![[الحزمة اليومية] مللي ثانية](http://www.luping.net/uploads/20241006/17282235656702994dea8b1.jpg)







تنصل: جميع الموارد المقدمة هي جزئيًا من الإنترنت. إذا كان هناك أي انتهاك لحقوق الطبع والنشر الخاصة بك أو الحقوق والمصالح الأخرى، فيرجى توضيح الأسباب التفصيلية وتقديم دليل على حقوق الطبع والنشر أو الحقوق والمصالح ثم إرسالها إلى البريد الإلكتروني: [email protected]. سوف نتعامل مع الأمر لك في أقرب وقت ممكن.
Copyright© 2022 湘ICP备2022001581号-3










