
برنامج جافا لإزالة التكرارات من مكدس معين
 تصفح:175
تصفح:175
في هذه المقالة، سنستكشف طريقتين لإزالة العناصر المكررة من المكدس في Java. سنقوم بمقارنة الطريقة المباشرة مع الحلقات المتداخلة وطريقة أكثر كفاءة باستخدام HashSet. الهدف هو توضيح كيفية تحسين إزالة التكرارات وتقييم أداء كل نهج.
بيان المشكلة
اكتب برنامج Java لإزالة العنصر المكرر من المكدس.
مدخل
Stackdata = initData(10L);
الإخراج
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
لإزالة التكرارات من مكدس معين، لدينا طريقتان -
- منهج ساذج: أنشئ حلقتين متداخلتين لمعرفة العناصر الموجودة بالفعل ومنع إضافتها إلى إرجاع مكدس النتائج.
- منهج HashSet: استخدم Set لتخزين العناصر الفريدة، واستفد من تعقيد O(1) للتحقق مما إذا كان العنصر موجودًا أم لا.
إنشاء واستنساخ مكدسات عشوائية
فيما يلي برنامج Java يقوم أولاً بإنشاء مكدس عشوائي ثم يقوم بإنشاء نسخة مكررة منه لمزيد من الاستخدام −
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData يساعد في إنشاء مكدس بحجم محدد وعناصر عشوائية تتراوح من 1 إلى 100.
manualCloneStack يساعد في إنشاء البيانات عن طريق نسخ البيانات من مكدس آخر، واستخدامها لمقارنة الأداء بين الفكرتين.
إزالة التكرارات من مكدس معين باستخدام أسلوب السذاجة
فيما يلي خطوة إزالة التكرارات من مكدس معين باستخدام أسلوب Naïve −
- بدء تشغيل الموقت.
- إنشاء مكدس فارغ لتخزين العناصر الفريدة.
- قم بالتكرار باستخدام حلقة while واستمر حتى تصبح المكدس الأصلي فارغًا، ثم قم بإخراج العنصر العلوي.
- تحقق من التكرارات باستخدام resultStack.contains(element) لمعرفة ما إذا كان العنصر موجودًا بالفعل في حزمة النتائج.
- إذا لم يكن العنصر موجودًا في مكدس النتائج، فأضفه إلى resultStack.
- سجل وقت الانتهاء واحسب إجمالي الوقت المستغرق.
- إرجاع النتيجة
مثال
يوجد أدناه برنامج Java لإزالة التكرارات من مكدس معين باستخدام أسلوب Naïve −
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
للنهج الساذج، نستخدم
while (!stack.isEmpty())
resultStack.contains(element)
للتحقق مما إذا كان العنصر موجودًا بالفعل.إزالة التكرارات من مكدس معين باستخدام النهج الأمثل (HashSet)
فيما يلي خطوة إزالة التكرارات من مكدس معين باستخدام النهج الأمثل -
- بدء المؤقت
- قم بإنشاء مجموعة لتتبع العناصر المرئية (لفحوصات تعقيد O(1)).
- قم بإنشاء مكدس مؤقت لتخزين العناصر الفريدة.
- التكرار باستخدام أثناء الحلقة يستمر حتى يصبح المكدس فارغًا.
- قم بإزالة العنصر العلوي من المكدس.
- للتحقق من التكرارات سنستخدم seen.contains(element) للتحقق مما إذا كان العنصر موجودًا بالفعل في المجموعة.
- إذا لم يكن العنصر موجودًا في المجموعة، فأضفه إلى كل من المكدس المرئي والمؤقت.
- سجل وقت الانتهاء واحسب إجمالي الوقت المستغرق.
- إرجاع النتيجة
مثال
يوجد أدناه برنامج Java لإزالة التكرارات من مكدس معين باستخدام HashSet −
public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
للحصول على النهج الأمثل، نستخدم
Set seen استخدام كلا الطريقتين معًا
فيما يلي خطوة إزالة التكرارات من مكدس معين باستخدام كلا الطريقتين المذكورتين أعلاه -
- تهيئة البيانات نستخدم طريقة initData(حجم طويل) لإنشاء مكدس مليء بأعداد صحيحة عشوائية.
- استنساخ المكدس نستخدم طريقة cloneStack(Stack Stack) لإنشاء نسخة طبق الأصل من المكدس الأصلي.
- قم بإنشاء المكدس الأولي باستخدام initData.
- انسخ هذه المكدس باستخدام cloneStack.
- قم بتطبيق الأسلوب الساذج لإزالة التكرارات من المجموعة الأصلية.
- تطبيق الأسلوب الأمثل لإزالة التكرارات من المكدس المستنسخ. عرض الوقت المستغرق لكل طريقة والعناصر الفريدة التي تنتجها كلا الطريقتين
مثال
يوجد أدناه برنامج Java الذي يزيل العناصر المكررة من المكدس باستخدام كلا الطريقتين المذكورتين أعلاه -
استيراد java.util.HashSet; import java.util.Random; import java.util.Set; import java.util.Stack; الطبقة العامة DuplicateStackElements { مكدس ثابت خاص
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
} الإخراج
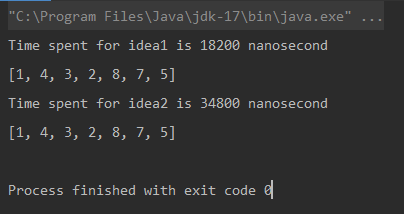
* وحدة القياس هي النانو ثانية.
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| 100 عنصر | 1000 عنصر | 10000 عنصر
| 100000 عنصر
1000000 عنصر |
| الفكرة 1|
| 4051600 |
19026900 |
114201800 |
1157256000 |
| الفكرة الثانية|
| 681400 |
2717800 |
11489400 |
36456100 |
|
-
 كيفية حل تباينات مسار الوحدة في GO Mod باستخدام توجيه استبدال؟يمكن أن يؤدي ذلك إلى فشل GO MOD TIDY ، كما يتضح من الرسائل المرددة: ` github.com/coreos/etcd/client تم اختبارها بواسطة استيرادات github.com/co...برمجة نشر في 2025-07-08
كيفية حل تباينات مسار الوحدة في GO Mod باستخدام توجيه استبدال؟يمكن أن يؤدي ذلك إلى فشل GO MOD TIDY ، كما يتضح من الرسائل المرددة: ` github.com/coreos/etcd/client تم اختبارها بواسطة استيرادات github.com/co...برمجة نشر في 2025-07-08 -
نصائح Spark DataFrame لإضافة أعمدة ثابتةيمكن أن تؤدي طريقة withColumn ، المخصصة لهذا الغرض ، إلى أخطاء عند محاولة توفير قيمة مباشرة كوسيطة ثانية. باستخدام القيم الحرفية (Spark 1.3) مض...برمجة نشر في 2025-07-08
-
كيفية تعيين مفاتيح ديناميكي في كائنات JavaScript؟كيفية إنشاء مفتاح ديناميكي لمتغير كائن JavaScript يستخدم النهج الصحيح بين قوسين مربعين: jsObj['key' i] = 'example' 1; لتسديد خاصية مع مفتاح...برمجة نشر في 2025-07-08
-
كيفية إضافة قاعدة بيانات MySQL إلى مربع الحوار DataSource في Visual Studio 2012؟إضافة قاعدة بيانات mysql إلى مربع حوار dataSource في Visual Studio 2012 تتناول هذه المقالة هذه المشكلة وتوفر حلًا. على الرغم من تثبيت موصل MyS...برمجة نشر في 2025-07-08
-
طريقة فعالة Python لإزالة علامات HTML من النصيمكن تحقيق ذلك من خلال تجريد علامات HTML بشكل فعال ، مما يتركك مع النص العادي المطلوب. تحقيق استخراج النص فقط مع MLSTRIPPER PYTHON يأخذ Mlstri...برمجة نشر في 2025-07-08
-
شذوذات صفيف PHP: فهم الحالة الغريبة من 07 و 08في PHP ، تنشأ مشكلة غير عادية عندما تحتوي المفاتيح على قيم رقمية مثل 07 أو 08. تشغيل print_r (أشهر دولارات) يعيد نتائج غير متوقعة: المفتاح "0...برمجة نشر في 2025-07-08
-
أسباب وحلول لفشل الكشف عن الوجه: خطأ -215في الوظيفة detectmultiscale. " عادةً ما ينشأ هذا الخطأ عندما يتم تحميل مصنف Cascade للوجه ، وهو مكون حاسم للكشف عن الوجه ، بشكل صحيح. في مقتط...برمجة نشر في 2025-07-08
-
كيفية اكتشاف المصفوفات الفارغة بكفاءة في PHP؟إذا كانت الحاجة هي التحقق من وجود أي عنصر صفيف ، فإن الكتابة الفضفاضة لـ PHP تسمح بالتقييم المباشر للمصفوفة نفسها: إذا (! $ playerlist) { // ...برمجة نشر في 2025-07-08
-
كائن مناسب: فشل الغطاء في IE و Edge ، كيفية إصلاح؟في CSS للحفاظ على ارتفاع الصور المتسق يعمل بسلاسة عبر المتصفحات. ومع ذلك ، في IE و Edge ، تنشأ قضية غريبة. عند توسيع نطاق المتصفح ، تتغير الصورة في...برمجة نشر في 2025-07-08
-
كيفية تبسيط تحليل JSON في PHP للحصول على صفائف متعددة الأبعاد؟تحليل JSON مع PHP يمكن أن يكون تحليل بيانات JSON في PHP ، خاصة عند التعامل مع المصفوفات متعددة الأبعاد. لتبسيط العملية ، يوصى بتحليل JSON كصفيف ...برمجة نشر في 2025-07-08
-
كيفية تحميل الملفات مع معلمات إضافية باستخدام java.net.urlconnection وترميز multipart/form-data؟فيما يلي تفصيل للعملية: multipart/form-data الترميز تم تصميم multipart/form-data لطلبات النشر التي تجمع بين كل من الثنائي (على سبيل المثال ،...برمجة نشر في 2025-07-08
-
التنفيذ الديناميكي العاكس لواجهة GO لاستكشاف طريقة RPCأحد الأسئلة التي أثيرت هو ما إذا كان من الممكن استخدام الانعكاس لإنشاء وظيفة جديدة تنفذ واجهة محددة. بيان مشكلة على سبيل المثال ، فكر في واجهة...برمجة نشر في 2025-07-08
-
خطأ المترجم "usr/bin/ld: لا يمكن العثور على -L" حل-l يشير هذا الخطأ إلى أن الرابط لا يمكنه تحديد موقع المكتبة المحددة أثناء ربطك القابل للتنفيذ. لحل هذه المشكلة ، سوف نتعمق في تفاصيل كيفية تحدي...برمجة نشر في 2025-07-08
-
كيفية تحليل صفائف JSON في GO باستخدام حزمة `json`؟مثال: صفيف [] سلسلة } Func Main () { DataJson: = `[" 1 "،" 2 "،" 3 "]` ` ARR: = jsontype {} unmarsh...برمجة نشر في 2025-07-08
-
مستخدم تنسيق الوقت المحلي ودليل عرض إزاحة المنطقة الزمنيةعرض التاريخ/الوقت في تنسيق لغة المستخدم مع إزاحة الوقت عند تقديم التواريخ والأوقات إلى المستخدمين النهائيين ، من الأهمية بمكان عرضها في الوقت ...برمجة نشر في 2025-07-08















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









