 الصفحة الأمامية > برمجة > استخراج البيانات من ملفات PDF الصعبة باستخدام Google Gemini في خطوط Python
الصفحة الأمامية > برمجة > استخراج البيانات من ملفات PDF الصعبة باستخدام Google Gemini في خطوط Python
استخراج البيانات من ملفات PDF الصعبة باستخدام Google Gemini في خطوط Python
 تصفح:910
تصفح:910
في هذا الدليل، سأوضح لك كيفية استخراج البيانات المنظمة من ملفات PDF باستخدام نماذج لغة الرؤية (VLMs) مثل Gemini Flash أو GPT-4o.
أظهرت سلسلة Gemini، أحدث سلسلة من نماذج الرؤية واللغة من Google، أداءً متطورًا في فهم النص والصور. هذه القدرة المحسنة متعددة الوسائط ونافذة السياق الطويلة تجعلها مفيدة بشكل خاص لمعالجة بيانات PDF المعقدة بصريًا والتي تواجهها نماذج الاستخراج التقليدية، مثل الأشكال والمخططات والجداول والرسوم البيانية.
من خلال القيام بذلك، يمكنك بسهولة إنشاء أداة استخراج البيانات الخاصة بك لاستخراج الملفات المرئية والويب. وإليك الطريقة:
إن نافذة السياق الطويلة لـ Gemini وإمكانيات الوسائط المتعددة تجعلها مفيدة بشكل خاص لمعالجة بيانات PDF المعقدة بصريًا حيث تكافح نماذج الاستخراج التقليدية.
إعداد بيئتك
قبل أن نتعمق في عملية الاستخراج، فلنقم بإعداد بيئة التطوير الخاصة بنا. يفترض هذا الدليل أن لغة Python مثبتة على نظامك. إذا لم يكن الأمر كذلك، فقم بتنزيله وتثبيته من https://www.python.org/downloads/
⚠️ لاحظ أنه إذا كنت لا ترغب في استخدام Python، فيمكنك استخدام النظام الأساسي السحابي على thepi.pe لتحميل ملفاتك وتنزيل نتيجتك كملف CSV دون كتابة أي كود.
تثبيت المكتبات المطلوبة
افتح المحطة الطرفية أو موجه الأوامر وقم بتشغيل الأوامر التالية:
pip install git https://github.com/emcf/thepipe pip install pandas
بالنسبة لأولئك الجدد في لغة Python، النقطة pip هي أداة تثبيت الحزمة لـ Python، وستقوم هذه الأوامر بتنزيل المكتبات الضرورية وتثبيتها.
قم بإعداد مفتاح API الخاص بك
لاستخدام الأنبوب، تحتاج إلى مفتاح API.
إخلاء المسؤولية: على الرغم من أن thepi.pe هي أداة مجانية مفتوحة المصدر، إلا أن تكلفة واجهة برمجة التطبيقات (API) تبلغ حوالي 0.00002 دولار لكل رمز مميز. إذا كنت تريد تجنب مثل هذه التكاليف، فراجع تعليمات الإعداد المحلية على GitHub. لاحظ أنه لا يزال يتعين عليك الدفع لمقدم خدمة LLM الذي تختاره.
إليك كيفية الحصول عليه وإعداده:
- قم بزيارة https://thepi.pe/platform/
- إنشاء حساب أو تسجيل الدخول
- ابحث عن مفتاح API الخاص بك في صفحة الإعدادات

الآن، أنت بحاجة إلى تعيين هذا كمتغير بيئة. تختلف العملية حسب نظام التشغيل الخاص بك:
- انسخ مفتاح API من قائمة الإعدادات على منصة thepi.pe
لنظام التشغيل Windows:
- البحث عن "متغيرات البيئة" في قائمة ابدأ
- انقر على "تحرير متغيرات بيئة النظام"
- انقر على زر "متغيرات البيئة"
- ضمن "متغيرات المستخدم"، انقر على "جديد"
- قم بتعيين اسم المتغير كـ THEPIPE_API_KEY والقيمة كمفتاح API الخاص بك
- انقر على "موافق" للحفظ
بالنسبة لنظامي التشغيل MacOS وLinux:
افتح المحطة الطرفية الخاصة بك وأضف هذا السطر إلى ملف تكوين Shell الخاص بك (على سبيل المثال، ~/.bashrc أو ~/.zshrc):
export THEPIPE_API_KEY=your_api_key_here
ثم أعد تحميل التكوين الخاص بك:
source ~/.bashrc # or ~/.zshrc
تحديد مخطط الاستخراج الخاص بك
مفتاح الاستخراج الناجح هو تحديد مخطط واضح للبيانات التي تريد سحبها. لنفترض أننا نستخرج البيانات من مستند فاتورة الكميات:

مثال لصفحة من مستند فاتورة الكميات. البيانات الموجودة في كل صفحة مستقلة عن الصفحات الأخرى، لذلك نقوم باستخراجها "لكل صفحة". هناك أجزاء متعددة من البيانات لاستخراجها في كل صفحة، لذلك قمنا بتعيين عمليات الاستخراج المتعددة على True
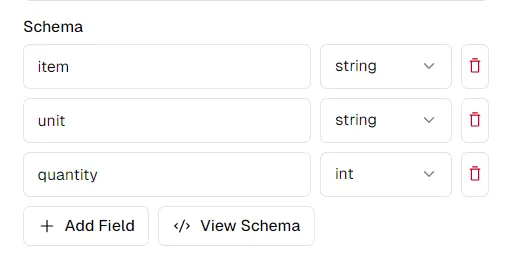
بالنظر إلى أسماء الأعمدة، قد نرغب في استخراج مخطط مثل هذا:
schema = {
"item": "string",
"unit": "string",
"quantity": "int",
}
يمكنك تعديل المخطط حسب رغبتك على منصة thepi.pe. يمنحك النقر على "عرض المخطط" مخططًا يمكنك نسخه ولصقه لاستخدامه مع Python API
استخراج البيانات من ملفات PDF
الآن، دعونا نستخدم extract_from_file لسحب البيانات من ملف PDF:
from thepipe.extract import extract_from_file results = extract_from_file( file_path = "bill_of_quantity.pdf", schema = schema, ai_model = "google/gemini-flash-1.5b", chunking_method = "chunk_by_page" )
هنا، قمنا بـchunking_method="chunk_by_page" لأننا نريد إرسال كل صفحة إلى نموذج الذكاء الاصطناعي بشكل فردي (ملف PDF كبير جدًا بحيث لا يمكن تغذية كل صفحة مرة واحدة). قمنا أيضًا بتعيين multiple_extractions=True لأن كل صفحة من صفحات PDF تحتوي على صفوف متعددة من البيانات. إليك الشكل الذي تبدو عليه صفحة من ملف PDF:
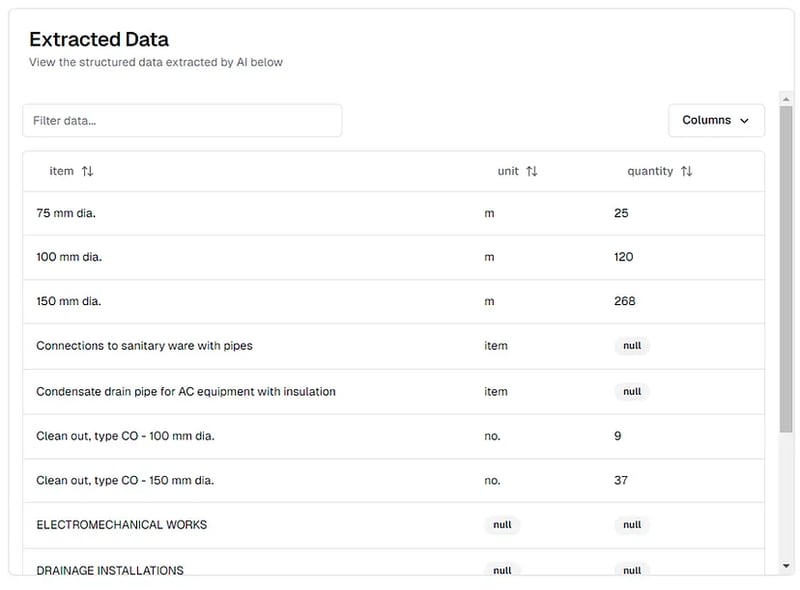
نتائج استخراج جدول الكميات PDF كما هي معروضة على منصة thepi.pe
معالجة النتائج
يتم إرجاع نتائج الاستخراج كقائمة من القواميس. يمكننا معالجة هذه النتائج لإنشاء إطار بيانات الباندا:
import pandas as pd df = pd.DataFrame(results) # Display the first few rows of the DataFrame print(df.head())
يؤدي هذا إلى إنشاء DataFrame بجميع المعلومات المستخرجة، بما في ذلك المحتوى النصي وأوصاف العناصر المرئية مثل الأشكال والجداول.
التصدير إلى صيغ مختلفة
الآن بعد أن أصبح لدينا بياناتنا في DataFrame، يمكننا بسهولة تصديرها إلى تنسيقات مختلفة. فيما يلي بعض الخيارات:
التصدير إلى إكسل
df.to_excel("extracted_research_data.xlsx", index=False, sheet_name="Research Data")
يؤدي هذا إلى إنشاء ملف Excel باسم "extracted_research_data.xlsx" مع ورقة باسم "Research Data". تمنع المعلمة Index=False تضمين فهرس DataFrame كعمود منفصل.
التصدير إلى CSV
إذا كنت تفضل تنسيقًا أبسط، يمكنك التصدير إلى ملف CSV:
df.to_csv("extracted_research_data.csv", index=False)
يؤدي هذا إلى إنشاء ملف CSV يمكن فتحه في Excel أو أي محرر نصوص.
ملاحظات النهاية
يكمن مفتاح الاستخراج الناجح في تحديد مخطط واضح واستخدام القدرات المتعددة الوسائط لنموذج الذكاء الاصطناعي. عندما تصبح أكثر ارتياحًا مع هذه التقنيات، يمكنك استكشاف المزيد من الميزات المتقدمة مثل طرق التجميع المخصصة، ومطالبات الاستخراج المخصصة، ودمج عملية الاستخراج في خطوط أنابيب بيانات أكبر.
-
 كائن مناسب: فشل الغطاء في IE و Edge ، كيفية إصلاح؟في CSS للحفاظ على ارتفاع الصور المتسق يعمل بسلاسة عبر المتصفحات. ومع ذلك ، في IE و Edge ، تنشأ قضية غريبة. عند توسيع نطاق المتصفح ، تتغير الصورة في...برمجة نشر في 2025-04-03
كائن مناسب: فشل الغطاء في IE و Edge ، كيفية إصلاح؟في CSS للحفاظ على ارتفاع الصور المتسق يعمل بسلاسة عبر المتصفحات. ومع ذلك ، في IE و Edge ، تنشأ قضية غريبة. عند توسيع نطاق المتصفح ، تتغير الصورة في...برمجة نشر في 2025-04-03 -
كيف يمكنني التعامل مع عمليات تحميل ملفات متعددة باستخدام FormData ()؟معالجة تحميلات متعددة مع تحميلات مع FormData () عند العمل مع مدخلات الملفات ، فغالبًا ما يكون من الضروري التعامل مع تحميلات الملفات المتعددة. ...برمجة نشر في 2025-04-03
-
كيف يمكنني تنفيذ عبارات SQL متعددة في استعلام واحد باستخدام Node-MySQL؟نصف كولون (؛) لفصل العبارات. ومع ذلك ، ينتج عن هذا خطأ يوضح أن هناك خطأ في بناء جملة SQL. لتمكين هذه الميزة ، تحتاج إلى تعيين تعدد الأطوار على صواب...برمجة نشر في 2025-04-03
-
كيف يمكنني تسلسل النص والقيم بأمان عند بناء استعلامات SQL في GO؟تسلسس النص والقيم في استعلامات sql go نهج tuple غير صالح في GO ، ومحاولة إلقاء المعلمات لأن السلاسل ستؤدي إلى أخطاء عدم التوافق في النوع. يتيح ل...برمجة نشر في 2025-04-03
-
كيف يمكنني اتحاد جداول قاعدة البيانات مع أرقام مختلفة من الأعمدة؟الجداول مجتمعة مع أعمدة مختلفة ] يمكن أن تواجه تحديات عند محاولة دمج جداول قاعدة البيانات بأعمدة مختلفة. تتمثل الطريقة المباشرة في إلحاق القيم ...برمجة نشر في 2025-04-03
-
كيف يمكنك استخدام مجموعة من خلال محور البيانات في MySQL؟هنا ، نتعامل مع تحد شائع: تحويل البيانات من الصف إلى الصفوف المستندة إلى الأعمدة باستخدام. لننظر في الاستعلام التالي: حدد البيانات مجموعة بوا...برمجة نشر في 2025-04-03
-
\ "بينما (1) مقابل (؛؛): هل يزيل التحسين المترجم اختلافات الأداء؟ \"بينما (1) مقابل (؛؛): هل هناك فرق السرعة؟ حلقات؟ الإجابة: المجمعات: بيرل: 1 أدخل -> 2 2 NextState (Main 2 -e: 1) V -> 3 9 LEAVELOOP VK/2...برمجة نشر في 2025-04-03
-
كيفية التعامل مع مدخلات المستخدم في الوضع الحصري لشروط جافا؟تستكشف هذه المقالة النهج الصحيح للتعامل مع إدخال المستخدم من لوحة المفاتيح والماوس في هذا الوضع. ومع ذلك ، في وضع كامل الشاشة الحصري ، قد لا تعمل ه...برمجة نشر في 2025-04-03
-
كيفية إزالة الرموز التعبيرية من الأوتار في بيثون: دليل المبتدئين لتثبيت الأخطاء الشائعة؟إزالة الرموز التعبيرية من سلاسل في python يجب تعيين سلاسل Unicode باستخدام بادئة U '' على Python 2. بالإضافة إلى ذلك ، يجب تمرير علامة ...برمجة نشر في 2025-04-03
-
هل تسمح Java بأنواع عائدات متعددة: نظرة فاحصة على الطرق العامة؟أنواع عائدات متعددة في java: تم الكشف عن المفاهيم الخاطئة getResult (String s) ؛ حيث Foo فئة مخصصة. يبدو أن إعلان الطريقة يضم نوعين من الإرج...برمجة نشر في 2025-04-03
-
كيف يمكنني استرداد قيم السمات بكفاءة من ملفات XML باستخدام PHP؟عند العمل مع ملف XML يحتوي على سمات مثل المثال المقدم: Stumped. لحل هذا ، يقدم PHP حلًا مباشرًا باستخدام وظيفة SimplexMlelement :: Attribut...برمجة نشر في 2025-04-03
-
كيف يمكنني استبدال سلاسل متعددة بكفاءة في سلسلة Java؟ومع ذلك ، يمكن أن يكون هذا غير فعال بالنسبة للسلاسل الكبيرة أو عند العمل مع العديد من الأوتار. تتيح لك التعبيرات العادية تحديد أنماط البحث المعقدة ...برمجة نشر في 2025-04-03
-
كيف يمكنني إنشاء رخويات ملائمة عناوين URL بكفاءة من سلاسل Unicode في PHP؟صياغة دالة لتوليد سبيكة فعالة تقدم هذه المقالة حلاً موجزًا لتوليد الرخويات بكفاءة ، وتحويل الأحرف الخاصة والأحرف غير ASCII إلى تنسيقات سهلة U...برمجة نشر في 2025-04-03
-
لماذا ينتج عن DateTime's PHP :: تعديل ('+1 شهر') نتائج غير متوقعة؟تعديل شهور مع DateTime PHP: الكشف عن السلوك المقصود عند العمل مع فئة قاعدة بيانات PHP ، قد لا تسفر عن الشهور أو طرحها دائمًا عن النتائج المتوق...برمجة نشر في 2025-04-03
-
لماذا توجد خطوط في خلفية التدرج الخطية ، وكيف يمكنني إصلاحها؟لحفر خطوط الخلفية من التدرج الخطي عند توظيف خاصية الدرجات الخطية لخلفية ، قد تواجه خطوطًا ملحوظة عندما يتم ضبط الاتجاه على الأعلى أو الأسفل. ي...برمجة نشر في 2025-04-03















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









