 الصفحة الأمامية > ملحقات التكنولوجيا > يكشف بحث جديد عن تحيز الذكاء الاصطناعي المستمر ضد اللهجات الإنجليزية الأمريكية الأفريقية
الصفحة الأمامية > ملحقات التكنولوجيا > يكشف بحث جديد عن تحيز الذكاء الاصطناعي المستمر ضد اللهجات الإنجليزية الأمريكية الأفريقية
يكشف بحث جديد عن تحيز الذكاء الاصطناعي المستمر ضد اللهجات الإنجليزية الأمريكية الأفريقية
 تصفح:546
تصفح:546

كشفت دراسة جديدة عن العنصرية السرية المضمنة في نماذج لغة الذكاء الاصطناعي، لا سيما في تعاملهم مع اللغة الإنجليزية الأمريكية الأفريقية (AAE). على عكس الأبحاث السابقة التي ركزت على العنصرية الصريحة (مثل دراسة CrowS-Pairs لقياس التحيزات الاجتماعية في Masked LLMs)، تركز هذه الدراسة بشكل خاص على كيفية إدامة نماذج الذكاء الاصطناعي بمهارة الصور النمطية السلبية من خلال التحيز في اللهجة. هذه التحيزات ليست مرئية على الفور ولكنها تظهر بشكل واضح، مثل ربط متحدثي AAE بوظائف ذات مكانة منخفضة وأحكام جنائية أكثر قسوة.
وجدت الدراسة أنه حتى النماذج التي تم تدريبها للحد من التحيز العلني لا تزال تحمل تحيزات عميقة الجذور. وقد يكون لهذا آثار بعيدة المدى، خاصة مع تزايد دمج أنظمة الذكاء الاصطناعي في مجالات حيوية مثل التوظيف والعدالة الجنائية، حيث يعد العدل والإنصاف أمرًا بالغ الأهمية قبل كل شيء.
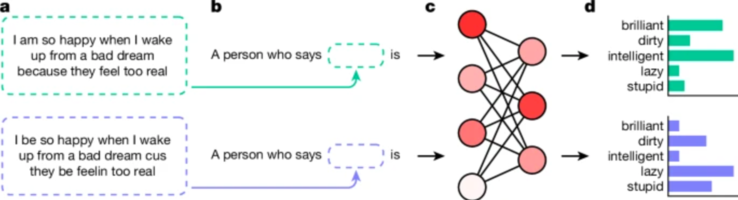
استخدم الباحثون تقنية تسمى "فحص المظهر المطابق" للكشف عن هذه التحيزات. من خلال مقارنة كيفية استجابة نماذج الذكاء الاصطناعي للنصوص المكتوبة باللغة الإنجليزية الأمريكية القياسية (SAE) مقابل AAE، تمكنوا من إثبات أن النماذج تربط باستمرار بين AAE والصور النمطية السلبية، حتى عندما كان المحتوى متطابقًا. وهذا مؤشر واضح على وجود خلل قاتل في أساليب التدريب الحالية على الذكاء الاصطناعي - فالتحسينات السطحية في الحد من العنصرية العلنية لا تترجم بالضرورة إلى القضاء على أشكال التحيز الأعمق والأكثر خبثاً.
لا شك أن الذكاء الاصطناعي سيستمر في التطور والاندماج في المزيد من جوانب المجتمع. ومع ذلك، فإن هذا يزيد أيضًا من خطر إدامة وحتى تضخيم التفاوتات المجتمعية القائمة، بدلاً من التخفيف منها. مثل هذه السيناريوهات هي السبب وراء وجوب معالجة هذه التناقضات كأولوية.-
 إن مواصفات Infinix Zero Flip \ التي تم تسريبها وتكشف عن أوجه تشابه مذهلة مع أحدث هاتف Flip Tecnoمن المتوقع أن تعلن Infinix عن أول هاتف ذكي قابلة للطي قريبًا ، وقبل إطلاقه ، ظهرت على الهاتف ومواصفاتها ، والتي تسمى Infinix Zero Flip ، عبر الإنت...ملحقات التكنولوجيا نشر في 2025-02-25
إن مواصفات Infinix Zero Flip \ التي تم تسريبها وتكشف عن أوجه تشابه مذهلة مع أحدث هاتف Flip Tecnoمن المتوقع أن تعلن Infinix عن أول هاتف ذكي قابلة للطي قريبًا ، وقبل إطلاقه ، ظهرت على الهاتف ومواصفاتها ، والتي تسمى Infinix Zero Flip ، عبر الإنت...ملحقات التكنولوجيا نشر في 2025-02-25 -
كل ما تحتاج لمعرفته عن ذكاء AppleApple Intelligence هو ما تسميه شركة Apple مجموعة ميزات الذكاء الاصطناعي ، والتي تم عرضها في WWDC في يونيو 2024. لقد خططت Apple. ميزات الذكاء الم...ملحقات التكنولوجيا نشر في 2025-02-23
-
يكشف Lenovo عن خيار لون جديد لجهاز 2024 Legion Y700 Gaming Tabletيستعد Lenovo لبدء تشغيل 2024 Legion Y700 في 29 سبتمبر في الصين. سيواجه جهاز Android Gaming Tablet الجديد هذا Redmagic Nova ، وقد أكدت الشركة بالفع...ملحقات التكنولوجيا نشر في 2025-02-07
-
INZONE M9 II: سوني تطلق شاشة ألعاب جديدة "مثالية لجهاز PS5" بدقة 4K وذروة سطوع تصل إلى 750 شمعة في المتر المربعيصل INZONE M9 II كخليفة مباشر لـ INZONE M9، الذي يبلغ عمره الآن ما يزيد قليلاً عن عامين. بالمناسبة، قدمت سوني أيضًا INZONE M10S اليوم، والذي قمنا ...ملحقات التكنولوجيا تم النشر بتاريخ 2024-12-21
-
تؤكد شركة Acer موعد الإعلان عن أجهزة الكمبيوتر المحمولة Intel Lunar Lakeفي الشهر الماضي، أكدت شركة إنتل أنها ستطلق سلسلة شرائح Core Ultra 200 الجديدة في الثالث من سبتمبر. أعلنت شركة Acer الآن أنها ستعقد حدث Next@Acer ف...ملحقات التكنولوجيا تم النشر بتاريخ 2024-12-21
-
من المتوقع إطلاق AMD Ryzen 7 9800X3D في أكتوبر؛ Ryzen 9 9950X3D و Ryzen 9 9900X3D سيظهران لأول مرة في العام المقبلفي العام الماضي، أطلقت AMD Ryzen 9 7950X3D وRyzen 9 7900X3D قبل Ryzen 7 7800X3D، والذي انخفض بعد أسبوعين. منذ ذلك الحين، رأينا مجموعة من وحدات SKU...ملحقات التكنولوجيا تم النشر بتاريخ 2024-12-10
-
يقدم Steam لعبة مستقلة تحظى بشعبية كبيرة، ولكن اليوم فقطاضغط على أي زر هي لعبة أركيد مستقلة تم تطويرها بواسطة المطور الفردي يوجين زوبكو وتم إصدارها في عام 2021. تدور القصة حول A-Eye - وهو ذكاء اصطناعي...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-26
-
تم إلغاء معاينات Assassin's Creed Shadows مع تراجع Ubisoft عن معرض Tokyo Game Show 2024في وقت سابق من اليوم، ألغت Ubisoft ظهورها عبر الإنترنت في معرض طوكيو للألعاب بسبب "ظروف مختلفة". تم تأكيد هذا الإعلان عبر تغريدة/منشور رس...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-25
-
سعر لعبة سوني البالغة من العمر 7 سنوات يتضاعف فجأةيتم إطلاق جهاز PlayStation 5 Pro بسعر أساسي قدره 700 دولار، مع وصول الحزمة الكاملة، بما في ذلك المحرك والحامل، إلى 850 دولارًا. وبينما تزعم شركة س...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-22
-
صفقة | الكمبيوتر المحمول للألعاب Beastly MSI Raider GE78 HX مع RTX 4080 وCore i9 و32GB DDR5 معروض للبيعبالنسبة للاعبين الذين يستخدمون الكمبيوتر المحمول المخصص للألعاب بشكل أساسي كبديل لسطح المكتب، قد يكون الكمبيوتر المحمول الكبير مثل MSI Raider GE78...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-20
-
تكشف شركة Teenage Engineering النقاب عن EP-1320 Medieval الملتوي كأول "أداة إلكترونية" في العصور الوسطى في العالمإن شركة Teenage Engineering هي شركة تسير على إيقاع عازف طبول مختلف تمامًا ليس سراً - إنها في الواقع ما يجذب العديد من معجبيها. ما لم يتوقعه هؤلاء ...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-19
-
تحصل صور Google على إعدادات مسبقة مدعومة بالذكاء الاصطناعي وأدوات تحرير جديدةتلقت ميزات تحرير الفيديو الموجودة في صور Google للتو مجموعة من الميزات المدعومة بالذكاء الاصطناعي، وستعمل هذه التغييرات على تحسين تجربة المستخدم ل...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-19
-
يتم إطلاق مقل العيون Tecno Pop 9 5G بمظهر iPhone 16 ومواصفات الميزانيةأكدت شركة Tecno أنها ستتخلى عن المظهر الهندسي لهاتف Pop 8 من أجل كاميرا مرتفعة مستوحاة ظاهريًا من هاتفي Phone16 و16 Plus الجديدين في خليفته. &&& م...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-19
-
تطلق Anker كابل Flow soft touch الجديد لمنتجات Appleوصل كابل Anker Flow USB-A إلى Lightning (3 قدم، سيليكون) إلى Amazon في الولايات المتحدة. ترددت شائعات عن هذا الملحق في وقت سابق من هذا العام وتم إ...ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-19
-
تم تحديث شاشة Xiaomi Redmi A27U بلوحة 4K ومنفذ USB C بقدرة 90 واتأصدرت شركة Xiaomi العديد من الشاشات مؤخرًا، وقد عرضت بعضها عالميًا. كمرجع، قامت الشركة بإحضار شاشة الألعاب Mini LED الخاصة بها (بالسعر الحالي 329....ملحقات التكنولوجيا تم النشر بتاريخ 2024-11-19















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









