 الصفحة الأمامية > برمجة > أكمل سير عمل التعلم الآلي باستخدام Scikit-Learn: التنبؤ بأسعار المساكن في كاليفورنيا
الصفحة الأمامية > برمجة > أكمل سير عمل التعلم الآلي باستخدام Scikit-Learn: التنبؤ بأسعار المساكن في كاليفورنيا
أكمل سير عمل التعلم الآلي باستخدام Scikit-Learn: التنبؤ بأسعار المساكن في كاليفورنيا
 تصفح:508
تصفح:508
مقدمة
في هذه المقالة، سنعرض سير عمل مشروع التعلم الآلي الكامل باستخدام Scikit-Learn. سنبني نموذجًا للتنبؤ بأسعار المساكن في كاليفورنيا استنادًا إلى ميزات مختلفة، مثل متوسط الدخل وعمر المنزل ومتوسط عدد الغرف. سيرشدك هذا المشروع خلال كل خطوة من خطوات العملية، بما في ذلك تحميل البيانات والاستكشاف والتدريب النموذجي والتقييم وتصور النتائج. سواء كنت مبتدئًا يتطلع إلى فهم الأساسيات أو ممارسًا ذو خبرة وتبحث عن تجديد المعلومات، ستوفر لك هذه المقالة رؤى قيمة حول التطبيق العملي لتقنيات التعلم الآلي.
مشروع التنبؤ بأسعار المساكن في كاليفورنيا
1. مقدمة
يشتهر سوق الإسكان في كاليفورنيا بخصائصه الفريدة وديناميكيات التسعير. نهدف في هذا المشروع إلى تطوير نموذج للتعلم الآلي للتنبؤ بأسعار المنازل بناءً على ميزات مختلفة. سنستخدم مجموعة بيانات الإسكان في كاليفورنيا، والتي تتضمن سمات مختلفة مثل متوسط الدخل وعمر المنزل ومتوسط الغرف والمزيد.
2. استيراد المكتبات
في هذا القسم، سنقوم باستيراد المكتبات اللازمة لمعالجة البيانات وتصورها وبناء نموذج التعلم الآلي الخاص بنا.
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.datasets import fetch_california_housing
3. تحميل مجموعة البيانات
سنقوم بتحميل مجموعة بيانات الإسكان في كاليفورنيا وإنشاء إطار بيانات لتنظيم البيانات. سيتم إضافة المتغير المستهدف، وهو سعر المنزل، كعمود جديد.
# Load the California Housing dataset california = fetch_california_housing() df = pd.DataFrame(california.data, columns=california.feature_names) df['PRICE'] = california.target
4. اختيار العينات بشكل عشوائي
للحفاظ على سهولة التحكم في التحليل، سنختار عشوائيًا 700 عينة من مجموعة البيانات لدراستنا.
# Randomly Selecting 700 Samples df_sample = df.sample(n=700, random_state=42)
5. النظر إلى بياناتنا
سيقدم هذا القسم نظرة عامة على مجموعة البيانات، ويعرض الصفوف الخمسة الأولى لفهم ميزات بياناتنا وبنيتها.
# Overview of the data
print("First five rows of the dataset:")
print(df_sample.head())
الإخراج
First five rows of the dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude \
20046 1.6812 25.0 4.192201 1.022284 1392.0 3.877437 36.06
3024 2.5313 30.0 5.039384 1.193493 1565.0 2.679795 35.14
15663 3.4801 52.0 3.977155 1.185877 1310.0 1.360332 37.80
20484 5.7376 17.0 6.163636 1.020202 1705.0 3.444444 34.28
9814 3.7250 34.0 5.492991 1.028037 1063.0 2.483645 36.62
Longitude PRICE
20046 -119.01 0.47700
3024 -119.46 0.45800
15663 -122.44 5.00001
20484 -118.72 2.18600
9814 -121.93 2.78000
عرض معلومات إطار البيانات
print(df_sample.info())
الإخراج
Index: 700 entries, 20046 to 5350 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 700 non-null float64 1 HouseAge 700 non-null float64 2 AveRooms 700 non-null float64 3 AveBedrms 700 non-null float64 4 Population 700 non-null float64 5 AveOccup 700 non-null float64 6 Latitude 700 non-null float64 7 Longitude 700 non-null float64 8 PRICE 700 non-null float64 dtypes: float64(9) memory usage: 54.7 KB
عرض إحصائيات الملخص
print(df_sample.describe())
الإخراج
MedInc HouseAge AveRooms AveBedrms Population \
count 700.000000 700.000000 700.000000 700.000000 700.000000
mean 3.937653 28.855714 5.404192 1.079266 1387.422857
std 2.085831 12.353313 1.848898 0.236318 1027.873659
min 0.852700 2.000000 2.096692 0.500000 8.000000
25% 2.576350 18.000000 4.397751 1.005934 781.000000
50% 3.480000 30.000000 5.145295 1.047086 1159.500000
75% 4.794625 37.000000 6.098061 1.098656 1666.500000
max 15.000100 52.000000 36.075472 5.273585 8652.000000
AveOccup Latitude Longitude PRICE
count 700.000000 700.000000 700.000000 700.000000
mean 2.939913 35.498243 -119.439729 2.082073
std 0.745525 2.123689 1.956998 1.157855
min 1.312994 32.590000 -124.150000 0.458000
25% 2.457560 33.930000 -121.497500 1.218500
50% 2.834524 34.190000 -118.420000 1.799000
75% 3.326869 37.592500 -118.007500 2.665500
max 7.200000 41.790000 -114.590000 5.000010
6. تقسيم مجموعة البيانات إلى مجموعات تدريب واختبار
سنقوم بفصل مجموعة البيانات إلى ميزات (X) والمتغير المستهدف (y) ثم تقسيمها إلى مجموعات تدريب واختبار لنموذج التدريب والتقييم.
# Splitting the dataset into Train and Test sets
X = df_sample.drop('PRICE', axis=1) # Features
y = df_sample['PRICE'] # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
7. التدريب النموذجي
في هذا القسم، سنقوم بإنشاء وتدريب نموذج الانحدار الخطي باستخدام بيانات التدريب لمعرفة العلاقة بين الميزات وأسعار المنازل.
# Creating and training the Linear Regression model lr = LinearRegression() lr.fit(X_train, y_train)
8. تقييم النموذج
سنقوم بعمل تنبؤات على مجموعة الاختبار وحساب متوسط الخطأ التربيعي (MSE) وقيم R-squared لتقييم أداء النموذج.
# Making predictions on the test set
y_pred = lr.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
print(f"\nLinear Regression Mean Squared Error: {mse}")
الإخراج
Linear Regression Mean Squared Error: 0.3699851092128846
9. عرض القيم الفعلية مقابل القيم المتوقعة
هنا، سنقوم بإنشاء DataFrame لمقارنة أسعار المنازل الفعلية مع الأسعار المتوقعة الناتجة عن نموذجنا.
# Displaying Actual vs Predicted Values
results = pd.DataFrame({'Actual Prices': y_test.values, 'Predicted Prices': y_pred})
print("\nActual vs Predicted:")
print(results)
الإخراج
Actual vs Predicted:
Actual Prices Predicted Prices
0 0.87500 0.887202
1 1.19400 2.445412
2 5.00001 6.249122
3 2.78700 2.743305
4 1.99300 2.794774
.. ... ...
135 1.62100 2.246041
136 3.52500 2.626354
137 1.91700 1.899090
138 2.27900 2.731436
139 1.73400 2.017134
[140 rows x
2 columns]
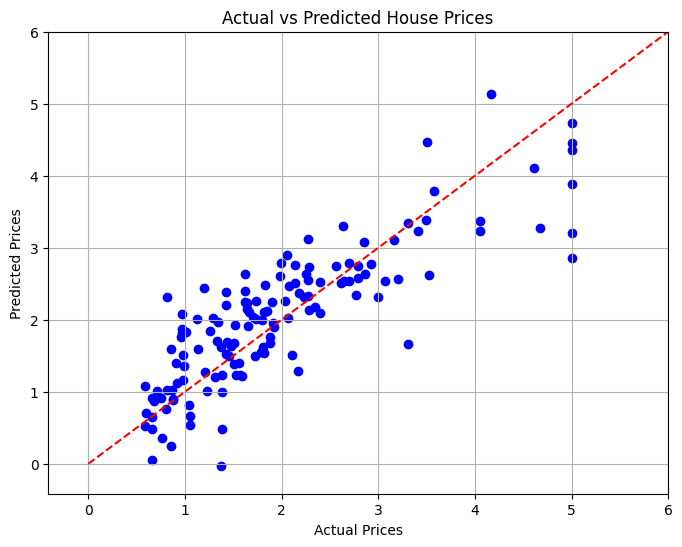
10. تصور النتائج
في القسم الأخير، سنقوم بتصور العلاقة بين أسعار المنازل الفعلية والمتوقعة باستخدام مخطط مبعثر لتقييم أداء النموذج بصريًا.
# Visualizing the Results
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue')
plt.xlabel('Actual Prices')
plt.ylabel('Predicted Prices')
plt.title('Actual vs Predicted House Prices')
# Draw the ideal line
plt.plot([0, 6], [0, 6], color='red', linestyle='--')
# Set limits to minimize empty space
plt.xlim(y_test.min() - 1, y_test.max() 1)
plt.ylim(y_test.min() - 1, y_test.max() 1)
plt.grid()
plt.show()
خاتمة
في هذا المشروع، قمنا بتطوير نموذج الانحدار الخطي للتنبؤ بأسعار المساكن في كاليفورنيا بناءً على ميزات مختلفة. تم حساب متوسط الخطأ التربيعي لتقييم أداء النموذج، والذي يوفر مقياسًا كميًا لدقة التنبؤ. ومن خلال التصور، تمكنا من رؤية مدى جودة أداء نموذجنا مقابل القيم الفعلية.
يوضح هذا المشروع قوة التعلم الآلي في التحليلات العقارية ويمكن أن يكون بمثابة أساس لتقنيات النمذجة التنبؤية الأكثر تقدمًا.
-
 كيف يمكنني استبدال سلاسل متعددة بكفاءة في سلسلة Java؟ومع ذلك ، يمكن أن يكون هذا غير فعال بالنسبة للسلاسل الكبيرة أو عند العمل مع العديد من الأوتار. تتيح لك التعبيرات العادية تحديد أنماط البحث المعقدة ...برمجة نشر في 2025-04-07
كيف يمكنني استبدال سلاسل متعددة بكفاءة في سلسلة Java؟ومع ذلك ، يمكن أن يكون هذا غير فعال بالنسبة للسلاسل الكبيرة أو عند العمل مع العديد من الأوتار. تتيح لك التعبيرات العادية تحديد أنماط البحث المعقدة ...برمجة نشر في 2025-04-07 -
كيف يمكنني التعامل مع عمليات تحميل ملفات متعددة باستخدام FormData ()؟معالجة تحميلات متعددة مع تحميلات مع FormData () عند العمل مع مدخلات الملفات ، فغالبًا ما يكون من الضروري التعامل مع تحميلات الملفات المتعددة. ...برمجة نشر في 2025-04-07
-
كيف يمكنني التعامل مع أسماء ملفات UTF-8 في وظائف نظام ملفات PHP؟url تشفير أسماء الملفات لحل هذه المشكلة ، استخدم وظيفة urlencode لتحويل اسم المجلد المطلوب إلى تنسيق آمن لـ url قبل تمريره إلى mkdir: MKDIR (...برمجة نشر في 2025-04-07
-
ما هي القيود المفروضة على استخدام Current_Timestamp مع أعمدة الطابع الزمني في MySQL قبل الإصدار 5.6.5؟Current_timestamp جملة. امتد هذا القيد إلى أعداد صحيحة ، و bigint ، و smallint عندما تم تقديمها في البداية في عام 2008. Current_Timestamp Value: إ...برمجة نشر في 2025-04-07
-
لماذا توجد خطوط في خلفية التدرج الخطية ، وكيف يمكنني إصلاحها؟لحفر خطوط الخلفية من التدرج الخطي عند توظيف خاصية الدرجات الخطية لخلفية ، قد تواجه خطوطًا ملحوظة عندما يتم ضبط الاتجاه على الأعلى أو الأسفل. ي...برمجة نشر في 2025-04-07
-
كيفية استرداد الصف الأخير بكفاءة لكل معرف فريد في postgresql؟postgresql: استخراج الصف الأخير لكل معرف فريد في postgresql ، قد تواجه مواقف حيث تحتاج إلى استخراج المعلومات من الصف الأخير المرتبط بكل معرف م...برمجة نشر في 2025-04-07
-
كيفية إضافة قاعدة بيانات MySQL إلى مربع الحوار DataSource في Visual Studio 2012؟إضافة قاعدة بيانات mysql إلى مربع حوار dataSource في Visual Studio 2012 تتناول هذه المقالة هذه المشكلة وتوفر حلًا. على الرغم من تثبيت موصل MyS...برمجة نشر في 2025-04-07
-
كيفية التعامل مع مدخلات المستخدم في الوضع الحصري لشروط جافا؟تستكشف هذه المقالة النهج الصحيح للتعامل مع إدخال المستخدم من لوحة المفاتيح والماوس في هذا الوضع. ومع ذلك ، في وضع كامل الشاشة الحصري ، قد لا تعمل ه...برمجة نشر في 2025-04-07
-
كيف يمكنني تصميم المثال الأول لنوع عنصر معين عبر مستند HTML بأكمله؟مطابقة العنصر الأول من نوع معين في المستند بالكامل يمكن أن يكون التصميم الأول من نوع معين عبر مستند HTML بالكامل تحديًا باستخدام CSS وحده. يق...برمجة نشر في 2025-04-07
-
كيف يمكنني اتحاد جداول قاعدة البيانات مع أرقام مختلفة من الأعمدة؟الجداول مجتمعة مع أعمدة مختلفة ] يمكن أن تواجه تحديات عند محاولة دمج جداول قاعدة البيانات بأعمدة مختلفة. تتمثل الطريقة المباشرة في إلحاق القيم ...برمجة نشر في 2025-04-07
-
كيفية عرض التاريخ والوقت الحاليين بشكل صحيح في "DD/MM/Yyyy HH: MM: SS.SS" في جافا؟يكمن في استخدام مثيلات التبسيط المختلفة مع أنماط تنسيق مختلفة. الحل: java.text.simpledateformat ؛ استيراد java.util.calendar ؛ استيراد java.ut...برمجة نشر في 2025-04-07
-
كيفية إصلاح \ "mysql_config لم يتم العثور عليها \" عند تثبيت mysql-python على ubuntu/linux؟خطأ في تثبيت mysql-python: ينشأ هذا الخطأ بسبب مكتبة تطوير MySQL المفقودة. لحل هذه المشكلة ، يوصى باستخدام مستودع التوزيع على Ubuntu. قم بتثبيت...برمجة نشر في 2025-04-07
-
كيف تستخدم بشكل صحيح مثل الاستعلامات مع معلمات PDO؟استخدام مثل الاستعلامات في pdo عند محاولة تنفيذ الاستفسارات في pdo ، قد تواجه مشكلات مثل تلك الموصوفة في الاستعلام أدناه: $ params = array ($ ...برمجة نشر في 2025-04-07
-
كيفية حل خطأ \ "الاستخدام غير صالح لوظيفة المجموعة \" في MySQL عند العثور على عدد أقصى؟كيفية استرداد الحد الأقصى لعد باستخدام mysql حدد ماكس (العد (*)) من مجموعة EMP1 بالاسم ؛ خطأ 1111 (hy000): الاستخدام غير الصحيح لوظيفة المجموعة...برمجة نشر في 2025-04-07
-
هل يمكنك استخدام CSS لإخراج وحدة التحكم في الكروم و Firefox؟الرسائل؟ لتحقيق ذلك ، استخدم النمط التالي: console.log ('٪ c oh my Heavens!' ، 'الخلفية: #222 ؛ اللون: #bada55') ؛ في هذا المث...برمجة نشر في 2025-04-07















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









