
قم بتوصيل AI/ML مع حل التحليلات التكيفية الخاص بك
 تصفح:524
تصفح:524
في مشهد البيانات اليوم، تواجه الشركات عددًا من التحديات المختلفة. أحدها هو إجراء التحليلات فوق طبقة البيانات الموحدة والمنسقة المتاحة لجميع المستهلكين. طبقة يمكنها تقديم نفس الإجابات لنفس الأسئلة بغض النظر عن اللهجة أو الأداة المستخدمة.
يجيب InterSystems IRIS Data Platform على ذلك من خلال Adaptive Analytics والوظيفة الإضافية التي يمكنها تقديم هذه الطبقة الدلالية الموحدة. هناك الكثير من المقالات في DevCommunity حول استخدامه عبر أدوات ذكاء الأعمال. ستغطي هذه المقالة الجزء الخاص بكيفية استهلاكها باستخدام الذكاء الاصطناعي وأيضًا كيفية إعادة بعض الأفكار إلى الوراء.
هيا بنا خطوة بخطوة...
ما هي التحليلات التكيفية؟
يمكنك بسهولة العثور على بعض التعريفات في موقع مجتمع المطورين
في بضع كلمات، يمكنه تقديم البيانات في شكل منظم ومنسق إلى أدوات مختلفة من اختيارك لمزيد من الاستهلاك والتحليل. فهو يوفر نفس هياكل البيانات لمختلف أدوات ذكاء الأعمال. ولكن... يمكنها أيضًا تقديم نفس هياكل البيانات لأدوات الذكاء الاصطناعي/تعلم الآلة الخاصة بك!
تحتوي التحليلات التكيفية على مكون إضافي يسمى AI-Link الذي يبني هذا الجسر من الذكاء الاصطناعي إلى ذكاء الأعمال.
ما هو بالضبط AI-Link؟
هو أحد مكونات لغة Python تم تصميمه لتمكين التفاعل البرمجي مع الطبقة الدلالية لأغراض تبسيط المراحل الرئيسية لسير عمل التعلم الآلي (ML) (على سبيل المثال، هندسة الميزات).
باستخدام AI-Link يمكنك:
- الوصول برمجيًا إلى ميزات نموذج البيانات التحليلية الخاص بك؛
- إجراء الاستعلامات واستكشاف الأبعاد والمقاييس؛
- تغذية خطوط أنابيب ML؛ ... وتسليم النتائج مرة أخرى إلى الطبقة الدلالية الخاصة بك ليتم استهلاكها مرة أخرى من قبل الآخرين (على سبيل المثال من خلال Tableau أو Excel).
نظرًا لأن هذه مكتبة بايثون، فيمكن استخدامها في أي بيئة بايثون. بما في ذلك أجهزة الكمبيوتر المحمولة.
وفي هذه المقالة سأقدم مثالًا بسيطًا للوصول إلى حل Adaptive Analytics من Jupyter Notebook بمساعدة AI-Link.
إليك مستودع git الذي سيحتوي على دفتر الملاحظات الكامل كمثال: https://github.com/v23ent/aa-hands-on
المتطلبات المسبقة
تفترض الخطوات الإضافية أن لديك المتطلبات المسبقة التالية مكتملة:
- تشغيل حل التحليلات التكيفية (باستخدام منصة بيانات IRIS كمستودع بيانات)
- تشغيل Jupyter Notebook
- يمكن إنشاء اتصال بين 1. و2.
الخطوة 1: الإعداد
أولاً، لنثبت المكونات المطلوبة في بيئتنا. سيؤدي ذلك إلى تنزيل بعض الحزم اللازمة لمزيد من الخطوات للعمل.
'atscale' - هذه هي الحزمة الرئيسية لدينا للاتصال
'prophet' - الحزمة التي سنحتاجها للقيام بالتنبؤات
pip install atscale prophet
ثم سنحتاج إلى استيراد الفئات الرئيسية التي تمثل بعض المفاهيم الأساسية للطبقة الدلالية لدينا.
العميل - الفئة التي سنستخدمها لإنشاء اتصال بالتحليلات التكيفية؛
المشروع - فئة لتمثيل المشاريع داخل التحليلات التكيفية؛
DataModel - الفئة التي ستمثل المكعب الافتراضي الخاص بنا؛
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
الخطوة 2: الاتصال
الآن يجب أن نكون مستعدين لإنشاء اتصال بمصدر البيانات لدينا.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
تابع وحدد تفاصيل الاتصال لمثيل Adaptive Analytics الخاص بك. بمجرد أن يُطلب منك رد المؤسسة في مربع الحوار، ثم الرجاء إدخال كلمة المرور الخاصة بك من مثيل AtScale.
مع الاتصال القائم، ستحتاج بعد ذلك إلى تحديد مشروعك من قائمة المشاريع المنشورة على الخادم. ستحصل على قائمة المشاريع كمطالبة تفاعلية ويجب أن تكون الإجابة هي المعرف الصحيح للمشروع. ومن ثم يتم تحديد نموذج البيانات تلقائيًا إذا كان هو النموذج الوحيد.
project = client.select_project() data_model = project.select_data_model()
الخطوة 3: استكشاف مجموعة البيانات الخاصة بك
هناك عدد من الطرق التي أعدتها AtScale في مكتبة مكونات AI-Link. فهي تسمح باستكشاف كتالوج البيانات لديك، والاستعلام عن البيانات، وحتى استيعاب بعض البيانات مرة أخرى. تحتوي وثائق AtScale على مرجع شامل لواجهة برمجة التطبيقات (API) يصف كل ما هو متاح.
دعونا أولاً نرى ما هي مجموعة البيانات لدينا عن طريق استدعاء بعض طرق data_model:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
يجب أن يبدو الإخراج مثل هذا
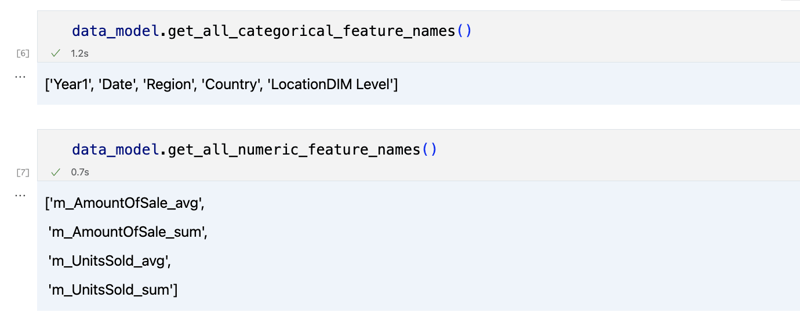
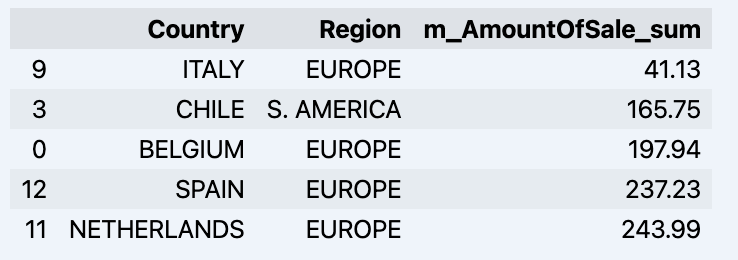
بمجرد أن ننظر حولنا قليلاً، يمكننا الاستعلام عن البيانات الفعلية التي نهتم بها باستخدام طريقة "get_data". سيعود مرة أخرى إلى DataFrame الباندا الذي يحتوي على نتائج الاستعلام.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
والتي سوف تظهر datadrame الخاص بك:
دعونا نجهز بعض مجموعات البيانات ونعرضها بسرعة على الرسم البياني
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
الإخراج:
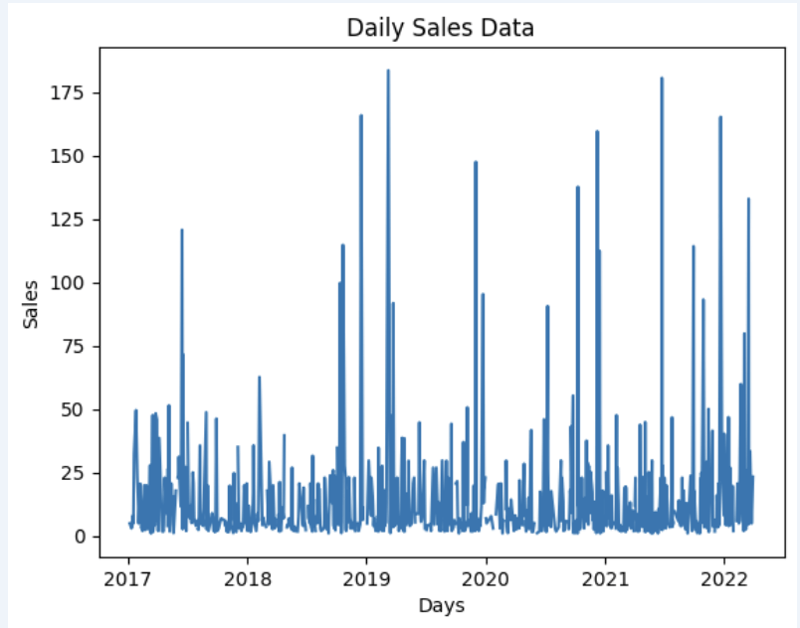
الخطوة 4: التنبؤ
الخطوة التالية هي الحصول على بعض القيمة من جسر AI-Link - فلنقم ببعض التنبؤات البسيطة!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
حصلنا هنا على مجموعتي بيانات مختلفتين: لتدريب نموذجنا واختباره.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
ثم نقوم بإنشاء إطار بيانات آخر لاستيعاب توقعاتنا وعرضه على الرسم البياني
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
الإخراج:
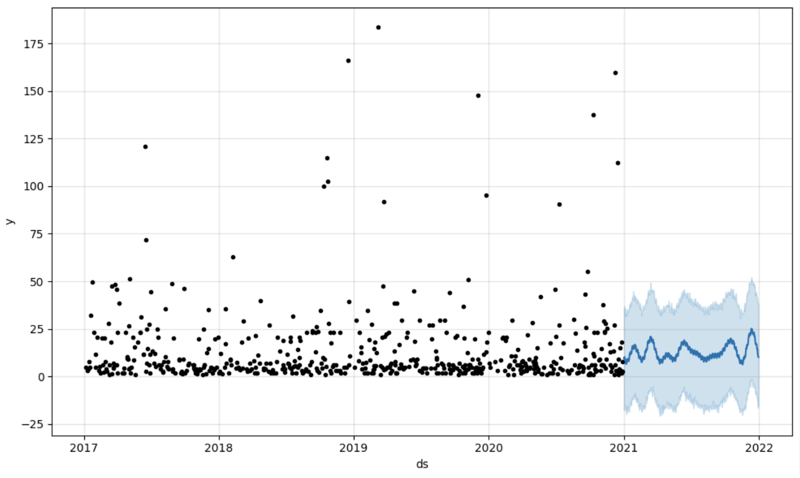
الخطوة 5: إعادة الكتابة
بمجرد أن نحصل على توقعاتنا في مكانها الصحيح، يمكننا بعد ذلك إعادتها إلى مستودع البيانات وإضافة تجميع إلى نموذجنا الدلالي ليعكسه للمستهلكين الآخرين. سيكون التنبؤ متاحًا من خلال أي أداة أخرى لذكاء الأعمال لمحللي ذكاء الأعمال ومستخدمي الأعمال.
سيتم وضع التنبؤ نفسه في مستودع البيانات الخاص بنا وتخزينه هناك.
from atscale.db.connections import Iris
db = Iris(
username,
host,
namespace,
driver,
schema,
port=1972,
password=None,
warehouse_id=None
)data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
الزعنفة
هذا كل شيء!
حظا سعيدا في توقعاتك!
-
 خطأ المترجم "usr/bin/ld: لا يمكن العثور على -L" حل-l يشير هذا الخطأ إلى أن الرابط لا يمكنه تحديد موقع المكتبة المحددة أثناء ربطك القابل للتنفيذ. لحل هذه المشكلة ، سوف نتعمق في تفاصيل كيفية تحدي...برمجة نشر في 2025-04-28
خطأ المترجم "usr/bin/ld: لا يمكن العثور على -L" حل-l يشير هذا الخطأ إلى أن الرابط لا يمكنه تحديد موقع المكتبة المحددة أثناء ربطك القابل للتنفيذ. لحل هذه المشكلة ، سوف نتعمق في تفاصيل كيفية تحدي...برمجة نشر في 2025-04-28 -
كيفية إدراج أو تحديث الصفوف بكفاءة بناءً على شرطين في MySQL؟إدراج أو تحديث مع شرطين وصف المشكلة: صف موجود إذا تم العثور على تطابق. تتيح هذه الميزة القوية معالجة البيانات الفعالة من خلال إدخال صف جديد ...برمجة نشر في 2025-04-28
-
كيفية تحميل الملفات مع معلمات إضافية باستخدام java.net.urlconnection وترميز multipart/form-data؟فيما يلي تفصيل للعملية: يتضمن الترميز تقسيم جسم الطلب إلى أجزاء متعددة ، كل منها مسبق بسلسلة حدودية. استيراد java.io.outputStream ؛ استيراد java....برمجة نشر في 2025-04-28
-
كيفية حل الخطأ "لا يمكن تخمين نوع الملف ، واستخدام التطبيق/ثنائي الثماني ..." في AppEngine؟التطبيق/actet-stream ... " دقة مشكلة لتصحيح هذه المشكلة وتحديد نوع mime الصحيح للملفات الثابتة ، اتبع الخطوات هذه: /etc/mime.types file...برمجة نشر في 2025-04-28
-
لماذا لا تزال الصور لديها حدود في الكروم؟ `الحدود: لا شيء ؛` حل غير صالحإزالة حدود الصورة باللغة الكروم و "الحدود: لا شيء ؛" في CSS. لحل هذه المشكلة ، ضع في اعتبارك الأساليب التالية: تحيز خلل الكروم ل...برمجة نشر في 2025-04-28
-
دليل إنشاء صفحة Fastapi مخصص 404تعتمد الطريقة المناسبة على متطلباتك المحددة. call_next (طلب) إذا كان الاستجابة. status_code == 404: إرجاع RedirectResponse ("https://fasta...برمجة نشر في 2025-04-28
-
كيف يمكنني استبدال سلاسل متعددة بكفاءة في سلسلة Java؟ومع ذلك ، يمكن أن يكون هذا غير فعال بالنسبة للسلاسل الكبيرة أو عند العمل مع العديد من الأوتار. تتيح لك التعبيرات العادية تحديد أنماط البحث المعقدة ...برمجة نشر في 2025-04-28
-
كيف يمكنني تخصيص تحسينات التجميع في برنامج التحويل البرمجي GO؟ومع ذلك ، قد يحتاج المستخدمون إلى ضبط هذه التحسينات لمتطلبات معينة. هذا يعني أن المترجم يطبق تلقائيًا التحسينات القائمة على الاستدلال المحدد مسبقً...برمجة نشر في 2025-04-28
-
هل أحتاج إلى حذف تخصيصات الكومة بشكل صريح في C ++ قبل خروج البرنامج؟هذه المقالة تتعطل في هذا الموضوع. في الوظيفة الرئيسية C ، يتم استخدام مؤشر لمتغير مخصص ديناميكيًا (ذاكرة الكومة). مع خروج التطبيق ، هل تم إصدار ه...برمجة نشر في 2025-04-28
-
ما هو الفرق بين الوظائف المتداخلة والإغلاق في بيثونلا تعتبر غير المساواة Make_printer (MSG): طابعة DEF (): طباعة (MSG) إرجاع طابعة هنا ، وظيفة الطابعة هي وظيفة متداخلة داخل Make_...برمجة نشر في 2025-04-28
-
لماذا ينتج عن DateTime's PHP :: تعديل ('+1 شهر') نتائج غير متوقعة؟تعديل شهور مع DateTime PHP: الكشف عن السلوك المقصود عند العمل مع فئة قاعدة بيانات PHP ، قد لا تسفر عن الشهور أو طرحها دائمًا عن النتائج المتوق...برمجة نشر في 2025-04-28
-
كيف تتجنب تسريبات الذاكرة عند الانتقال إلى اللغة؟تهدف هذه المقالة إلى تقديم توضيح من خلال فحص نهجين للتقطيع وعواقبها المحتملة. على الرغم من أنها فعالة بشكل عام ، إلا أنها قد تسبب تسرب الذاكرة إذا ...برمجة نشر في 2025-04-28
-
لماذا تفشل Microsoft Visual C ++ في تنفيذ إنشاء مثيل للقالب ثنائي المراحل بشكل صحيح؟] ما هي الجوانب المحددة للآلية تفشل في العمل كما هو متوقع؟ ومع ذلك ، تنشأ الشكوك فيما يتعلق بما إذا كان هذا الشيك يتحقق مما إذا كان يتم الإعلان عن الأ...برمجة نشر في 2025-04-28
-
كيف تمنع التقديمات المكررة بعد تحديث النموذج؟منع التقديمات المكررة مع تحديث المناولة في تطوير الويب ، من الشائع مواجهة مسألة التقديمات المكررة عند تحديث الصفحة بعد تقديم النموذج. لمعالجة ...برمجة نشر في 2025-04-28
-
هل يمكنك استخدام CSS لإخراج وحدة التحكم في الكروم و Firefox؟الرسائل؟ لتحقيق ذلك ، استخدم النمط التالي: console.log ('٪ c oh my Heavens!' ، 'الخلفية: #222 ؛ اللون: #bada55') ؛ في هذا المث...برمجة نشر في 2025-04-28















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









